 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness Tradeoff in Fine-Tuning
Mar 19, 2025Fine-tuning has become the standard practice for adapting pre-trained (upstream) models to downstream tasks. However, the impact on model robustness is not well understood. In this work, we characterize the robustness-accuracy trade-off in fine-tuning. We evaluate the robustness and accuracy of fine-tuned models over 6 benchmark datasets and 7 different fine-tuning strategies. We observe a consistent trade-off between adversarial robustness and accuracy. Peripheral updates such as BitFit are more effective for simple tasks--over 75% above the average measured with area under the Pareto frontiers on CIFAR-10 and CIFAR-100. In contrast, fine-tuning information-heavy layers, such as attention layers via Compacter, achieves a better Pareto frontier on more complex tasks--57.5% and 34.6% above the average on Caltech-256 and CUB-200, respectively. Lastly, we observe that robustness of fine-tuning against out-of-distribution data closely tracks accuracy. These insights emphasize the need for robustness-aware fine-tuning to ensure reliable real-world deployments.
Targeting Alignment: Extracting Safety Classifiers of Aligned LLMs
Jan 27, 2025



Alignment in large language models (LLMs) is used to enforce guidelines such as safety. Yet, alignment fails in the face of jailbreak attacks that modify inputs to induce unsafe outputs. In this paper, we present and evaluate a method to assess the robustness of LLM alignment. We observe that alignment embeds a safety classifier in the target model that is responsible for deciding between refusal and compliance. We seek to extract an approximation of this classifier, called a surrogate classifier, from the LLM. We develop an algorithm for identifying candidate classifiers from subsets of the LLM model. We evaluate the degree to which the candidate classifiers approximate the model's embedded classifier in benign (F1 score) and adversarial (using surrogates in a white-box attack) settings. Our evaluation shows that the best candidates achieve accurate agreement (an F1 score above 80%) using as little as 20% of the model architecture. Further, we find attacks mounted on the surrogate models can be transferred with high accuracy. For example, a surrogate using only 50% of the Llama 2 model achieved an attack success rate (ASR) of 70%, a substantial improvement over attacking the LLM directly, where we only observed a 22% ASR. These results show that extracting surrogate classifiers is a viable (and highly effective) means for modeling (and therein addressing) the vulnerability of aligned models to jailbreaking attacks.
A Machine Learning and Computer Vision Approach to Geomagnetic Storm Forecasting
Apr 04, 2022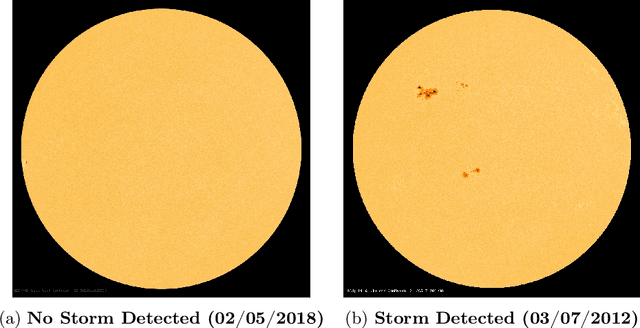
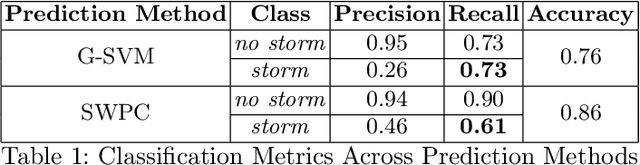
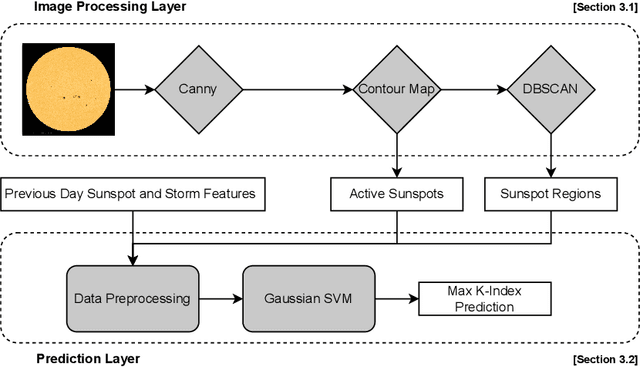
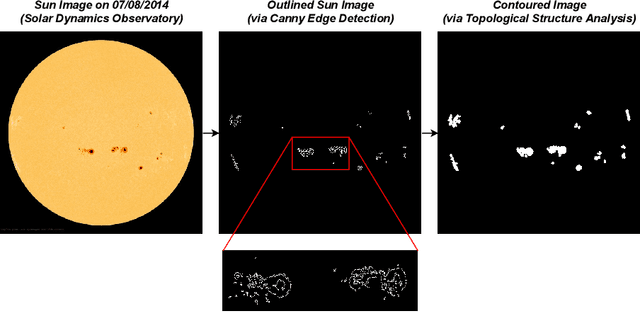
Geomagnetic storms, disturbances of Earth's magnetosphere caused by masses of charged particles being emitted from the Sun, are an uncontrollable threat to modern technology. Notably, they have the potential to damage satellites and cause instability in power grids on Earth, among other disasters. They result from high sun activity, which are induced from cool areas on the Sun known as sunspots. Forecasting the storms to prevent disasters requires an understanding of how and when they will occur. However, current prediction methods at the National Oceanic and Atmospheric Administration (NOAA) are limited in that they depend on expensive solar wind spacecraft and a global-scale magnetometer sensor network. In this paper, we introduce a novel machine learning and computer vision approach to accurately forecast geomagnetic storms without the need of such costly physical measurements. Our approach extracts features from images of the Sun to establish correlations between sunspots and geomagnetic storm classification and is competitive with NOAA's predictions. Indeed, our prediction achieves a 76% storm classification accuracy. This paper serves as an existence proof that machine learning and computer vision techniques provide an effective means for augmenting and improving existing geomagnetic storm forecasting methods.
ReViVD: Exploration and Filtering of Trajectories in an Immersive Environment using 3D Shapes
Feb 21, 2022
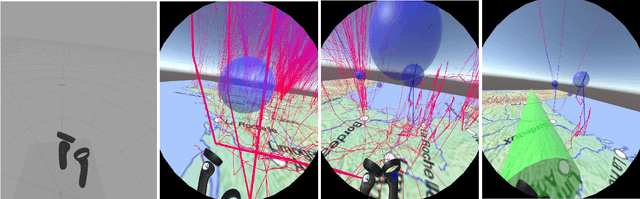

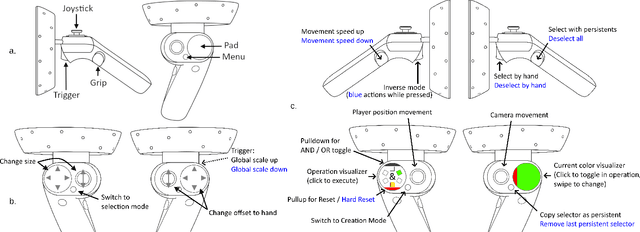
We present ReViVD, a tool for exploring and filtering large trajectory-based datasets using virtual reality. ReViVD's novelty lies in using simple 3D shapes -- such as cuboids, spheres and cylinders -- as queries for users to select and filter groups of trajectories. Building on this simple paradigm, more complex queries can be created by combining previously made selection groups through a system of user-created Boolean operations. We demonstrate the use of ReViVD in different application domains, from GPS position tracking to simulated data (e.g., turbulent particle flows and traffic simulation). Our results show the ease of use and expressiveness of the 3D geometric shapes in a broad range of exploratory tasks. ReViVD was found to be particularly useful for progressively refining selections to isolate outlying behaviors. It also acts as a powerful communication tool for conveying the structure of normally abstract datasets to an audience.
* Accepted at IEEE Conference on Virtual Reality and 3D User Interfaces (VR) 2020
HoneyModels: Machine Learning Honeypots
Feb 21, 2022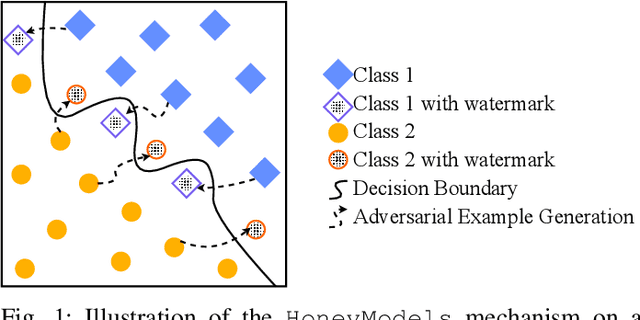
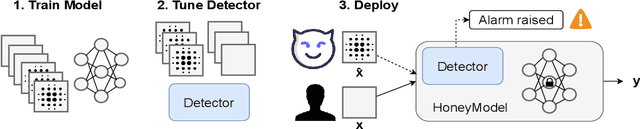
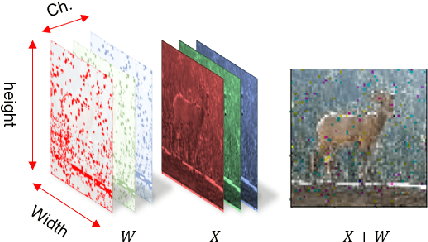
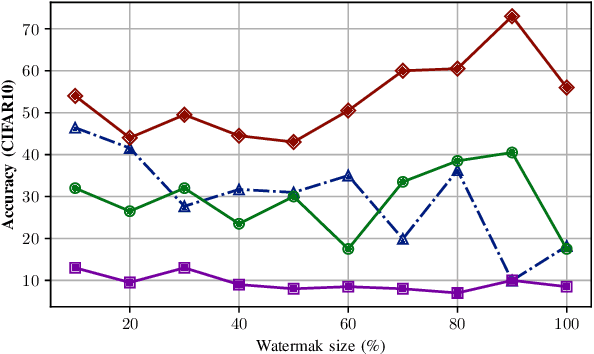
Machine Learning is becoming a pivotal aspect of many systems today, offering newfound performance on classification and prediction tasks, but this rapid integration also comes with new unforeseen vulnerabilities. To harden these systems the ever-growing field of Adversarial Machine Learning has proposed new attack and defense mechanisms. However, a great asymmetry exists as these defensive methods can only provide security to certain models and lack scalability, computational efficiency, and practicality due to overly restrictive constraints. Moreover, newly introduced attacks can easily bypass defensive strategies by making subtle alterations. In this paper, we study an alternate approach inspired by honeypots to detect adversaries. Our approach yields learned models with an embedded watermark. When an adversary initiates an interaction with our model, attacks are encouraged to add this predetermined watermark stimulating detection of adversarial examples. We show that HoneyModels can reveal 69.5% of adversaries attempting to attack a Neural Network while preserving the original functionality of the model. HoneyModels offer an alternate direction to secure Machine Learning that slightly affects the accuracy while encouraging the creation of watermarked adversarial samples detectable by the HoneyModel but indistinguishable from others for the adversary.
On the Robustness of Domain Constraints
May 18, 2021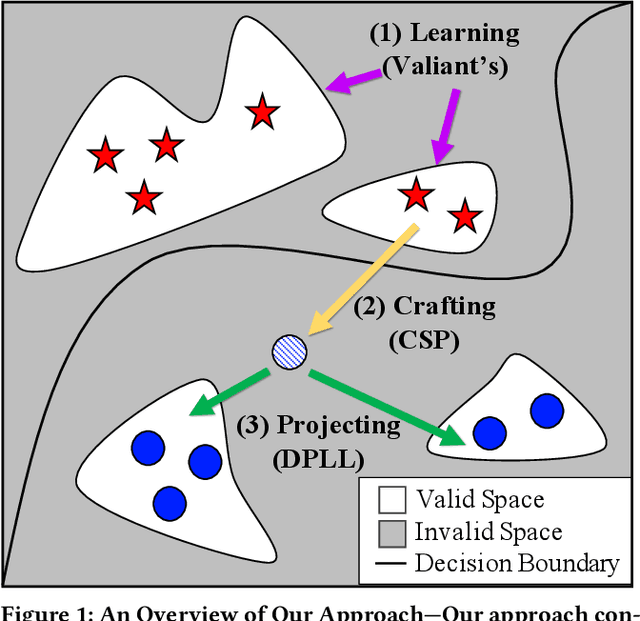

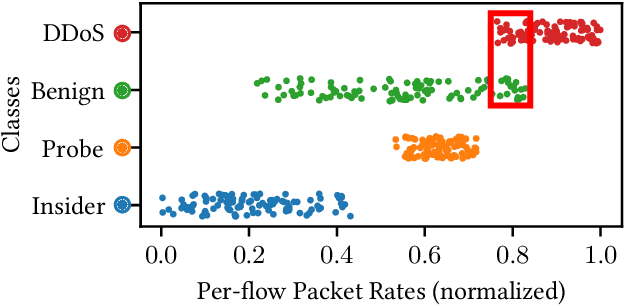
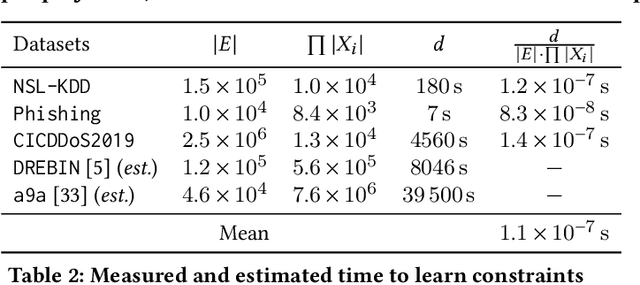
Machine learning is vulnerable to adversarial examples-inputs designed to cause models to perform poorly. However, it is unclear if adversarial examples represent realistic inputs in the modeled domains. Diverse domains such as networks and phishing have domain constraints-complex relationships between features that an adversary must satisfy for an attack to be realized (in addition to any adversary-specific goals). In this paper, we explore how domain constraints limit adversarial capabilities and how adversaries can adapt their strategies to create realistic (constraint-compliant) examples. In this, we develop techniques to learn domain constraints from data, and show how the learned constraints can be integrated into the adversarial crafting process. We evaluate the efficacy of our approach in network intrusion and phishing datasets and find: (1) up to 82% of adversarial examples produced by state-of-the-art crafting algorithms violate domain constraints, (2) domain constraints are robust to adversarial examples; enforcing constraints yields an increase in model accuracy by up to 34%. We observe not only that adversaries must alter inputs to satisfy domain constraints, but that these constraints make the generation of valid adversarial examples far more challenging.