 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemucAI at BAREC Shared Task 2025: Towards Uncertainty Aware Arabic Readability Assessment
Sep 18, 2025We present a simple, model-agnostic post-processing technique for fine-grained Arabic readability classification in the BAREC 2025 Shared Task (19 ordinal levels). Our method applies conformal prediction to generate prediction sets with coverage guarantees, then computes weighted averages using softmax-renormalized probabilities over the conformal sets. This uncertainty-aware decoding improves Quadratic Weighted Kappa (QWK) by reducing high-penalty misclassifications to nearer levels. Our approach shows consistent QWK improvements of 1-3 points across different base models. In the strict track, our submission achieves QWK scores of 84.9\%(test) and 85.7\% (blind test) for sentence level, and 73.3\% for document level. For Arabic educational assessment, this enables human reviewers to focus on a handful of plausible levels, combining statistical guarantees with practical usability.
mucAI at WojoodNER 2024: Arabic Named Entity Recognition with Nearest Neighbor Search
Aug 07, 2024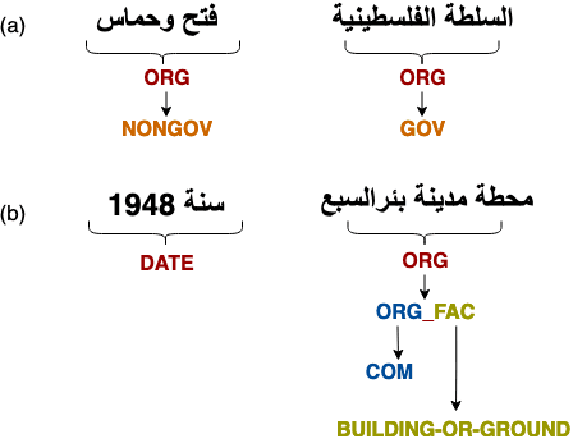
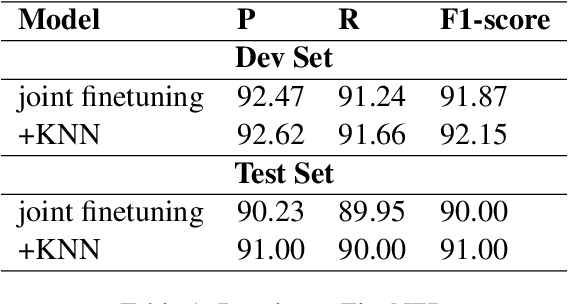
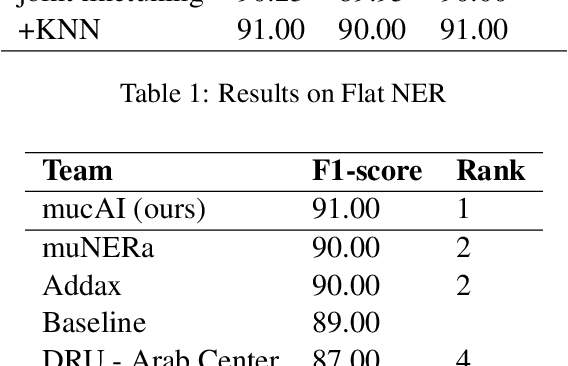
Named Entity Recognition (NER) is a task in Natural Language Processing (NLP) that aims to identify and classify entities in text into predefined categories. However, when applied to Arabic data, NER encounters unique challenges stemming from the language's rich morphological inflections, absence of capitalization cues, and spelling variants, where a single word can comprise multiple morphemes. In this paper, we introduce Arabic KNN-NER, our submission to the Wojood NER Shared Task 2024 (ArabicNLP 2024). We have participated in the shared sub-task 1 Flat NER. In this shared sub-task, we tackle fine-grained flat-entity recognition for Arabic text, where we identify a single main entity and possibly zero or multiple sub-entities for each word. Arabic KNN-NER augments the probability distribution of a fine-tuned model with another label probability distribution derived from performing a KNN search over the cached training data. Our submission achieved 91% on the test set on the WojoodFine dataset, placing Arabic KNN-NER on top of the leaderboard for the shared task.
Mind Your Neighbours: Leveraging Analogous Instances for Rhetorical Role Labeling for Legal Documents
Mar 31, 2024
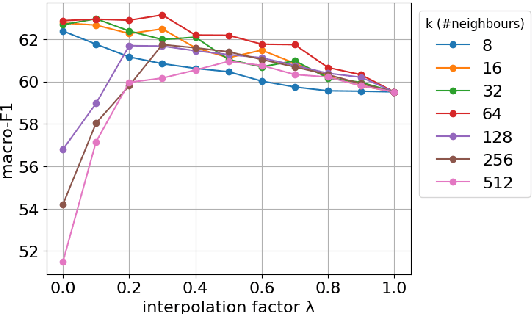

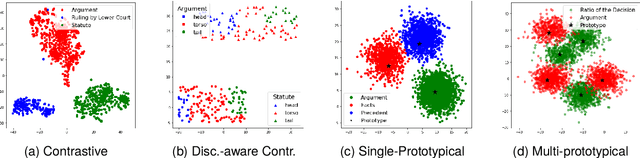
Rhetorical Role Labeling (RRL) of legal judgments is essential for various tasks, such as case summarization, semantic search and argument mining. However, it presents challenges such as inferring sentence roles from context, interrelated roles, limited annotated data, and label imbalance. This study introduces novel techniques to enhance RRL performance by leveraging knowledge from semantically similar instances (neighbours). We explore inference-based and training-based approaches, achieving remarkable improvements in challenging macro-F1 scores. For inference-based methods, we explore interpolation techniques that bolster label predictions without re-training. While in training-based methods, we integrate prototypical learning with our novel discourse-aware contrastive method that work directly on embedding spaces. Additionally, we assess the cross-domain applicability of our methods, demonstrating their effectiveness in transferring knowledge across diverse legal domains.
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022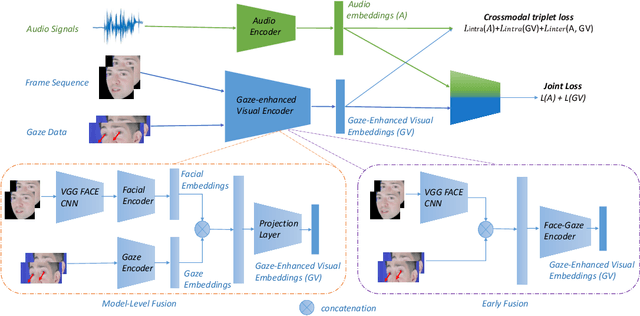
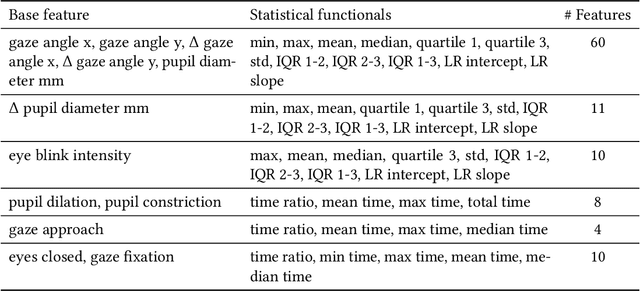

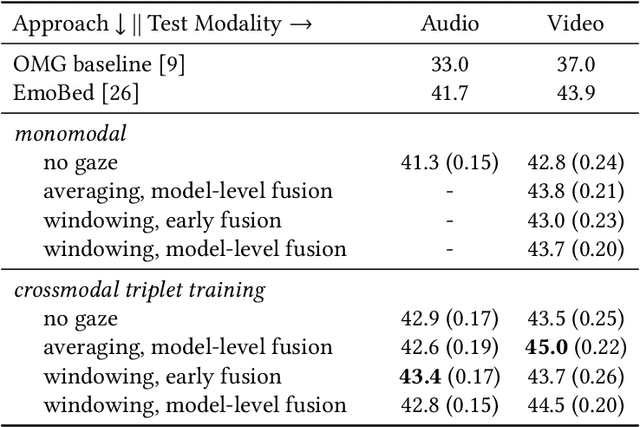
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
HoneyModels: Machine Learning Honeypots
Feb 21, 2022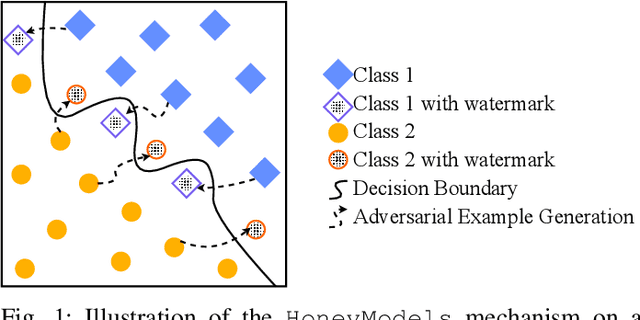
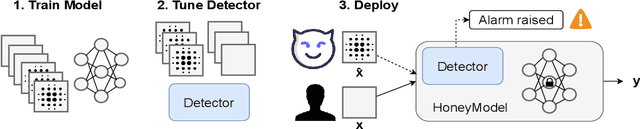
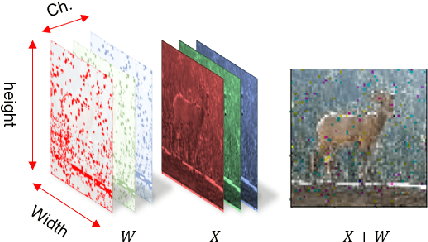
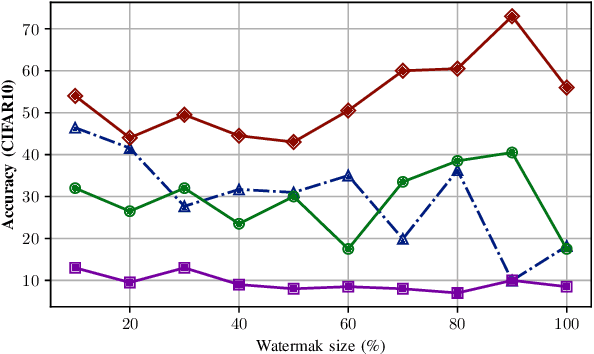
Machine Learning is becoming a pivotal aspect of many systems today, offering newfound performance on classification and prediction tasks, but this rapid integration also comes with new unforeseen vulnerabilities. To harden these systems the ever-growing field of Adversarial Machine Learning has proposed new attack and defense mechanisms. However, a great asymmetry exists as these defensive methods can only provide security to certain models and lack scalability, computational efficiency, and practicality due to overly restrictive constraints. Moreover, newly introduced attacks can easily bypass defensive strategies by making subtle alterations. In this paper, we study an alternate approach inspired by honeypots to detect adversaries. Our approach yields learned models with an embedded watermark. When an adversary initiates an interaction with our model, attacks are encouraged to add this predetermined watermark stimulating detection of adversarial examples. We show that HoneyModels can reveal 69.5% of adversaries attempting to attack a Neural Network while preserving the original functionality of the model. HoneyModels offer an alternate direction to secure Machine Learning that slightly affects the accuracy while encouraging the creation of watermarked adversarial samples detectable by the HoneyModel but indistinguishable from others for the adversary.
Enhancing Gradient-based Attacks with Symbolic Intervals
Jun 05, 2019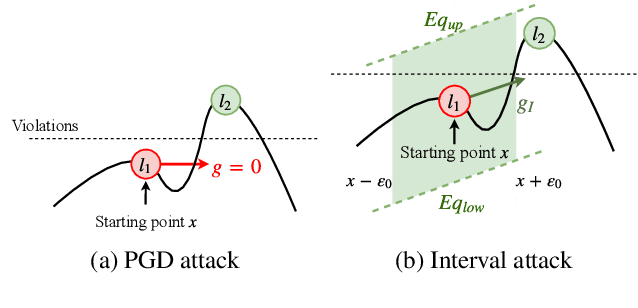

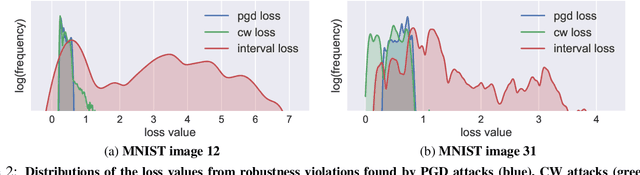
Recent breakthroughs in defenses against adversarial examples, like adversarial training, make the neural networks robust against various classes of attackers (e.g., first-order gradient-based attacks). However, it is an open question whether the adversarially trained networks are truly robust under unknown attacks. In this paper, we present interval attacks, a new technique to find adversarial examples to evaluate the robustness of neural networks. Interval attacks leverage symbolic interval propagation, a bound propagation technique that can exploit a broader view around the current input to locate promising areas containing adversarial instances, which in turn can be searched with existing gradient-guided attacks. We can obtain such a broader view using sound bound propagation methods to track and over-approximate the errors of the network within given input ranges. Our results show that, on state-of-the-art adversarially trained networks, interval attack can find on average 47% relatively more violations than the state-of-the-art gradient-guided PGD attack.
MixTrain: Scalable Training of Verifiably Robust Neural Networks
Dec 01, 2018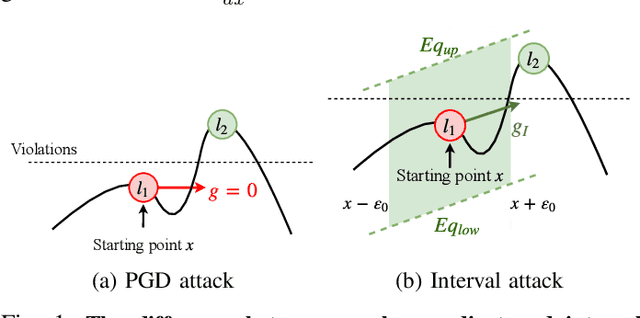
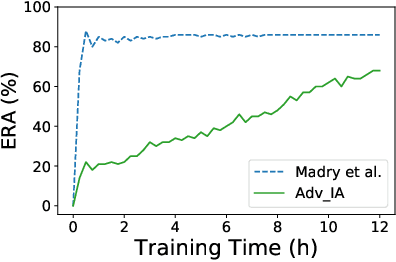
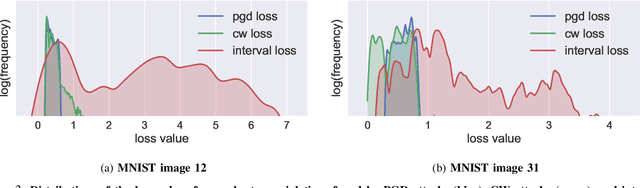
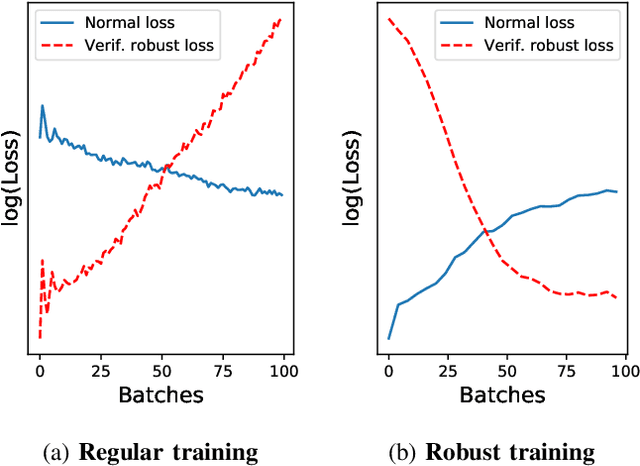
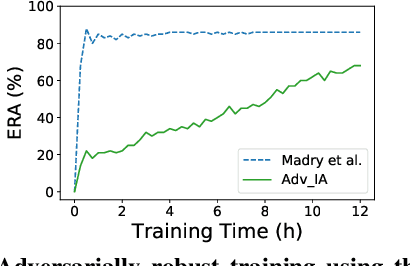
Making neural networks robust against adversarial inputs has resulted in an arms race between new defenses and attacks. The most promising defenses, adversarially robust training and verifiably robust training, have limitations that restrict their practical applications. The adversarially robust training only makes the networks robust against a subclass of attackers and we reveal such weaknesses by developing a new attack based on interval gradients. By contrast, verifiably robust training provides protection against any L-p norm-bounded attacker but incurs orders of magnitude more computational and memory overhead than adversarially robust training. We propose two novel techniques, stochastic robust approximation and dynamic mixed training, to drastically improve the efficiency of verifiably robust training without sacrificing verified robustness. We leverage two critical insights: (1) instead of over the entire training set, sound over-approximations over randomly subsampled training data points are sufficient for efficiently guiding the robust training process; and (2) We observe that the test accuracy and verifiable robustness often conflict after certain training epochs. Therefore, we use a dynamic loss function to adaptively balance them for each epoch. We designed and implemented our techniques as part of MixTrain and evaluated it on six networks trained on three popular datasets including MNIST, CIFAR, and ImageNet-200. Our evaluations show that MixTrain can achieve up to $95.2\%$ verified robust accuracy against $L_\infty$ norm-bounded attackers while taking $15$ and $3$ times less training time than state-of-the-art verifiably robust training and adversarially robust training schemes, respectively. Furthermore, MixTrain easily scales to larger networks like the one trained on ImageNet-200, significantly outperforming the existing verifiably robust training methods.