 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Databases via Independent Learning
May 28, 2022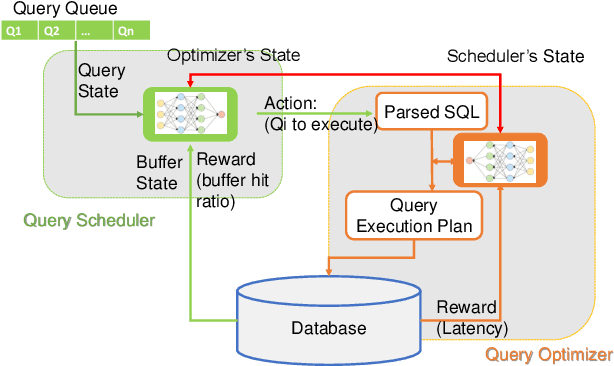

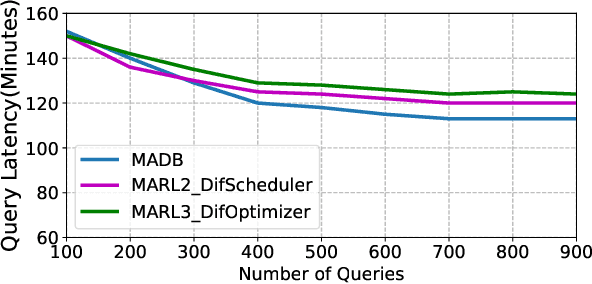
Machine learning is rapidly being used in database research to improve the effectiveness of numerous tasks included but not limited to query optimization, workload scheduling, physical design, etc. essential database components, such as the optimizer, scheduler, and physical designer. Currently, the research focus has been on replacing a single database component responsible for one task by its learning-based counterpart. However, query performance is not simply determined by the performance of a single component, but by the cooperation of multiple ones. As such, learned based database components need to collaborate during both training and execution in order to develop policies that meet end performance goals. Thus, the paper attempts to address the question "Is it possible to design a database consisting of various learned components that cooperatively work to improve end-to-end query latency?". To answer this question, we introduce MADB (Multi-Agent DB), a proof-of-concept system that incorporates a learned query scheduler and a learned query optimizer. MADB leverages a cooperative multi-agent reinforcement learning approach that allows the two components to exchange the context of their decisions with each other and collaboratively work towards reducing the query latency. Preliminary results demonstrate that MADB can outperform the non-cooperative integration of learned components.
Buffer Pool Aware Query Scheduling via Deep Reinforcement Learning
Jul 21, 2020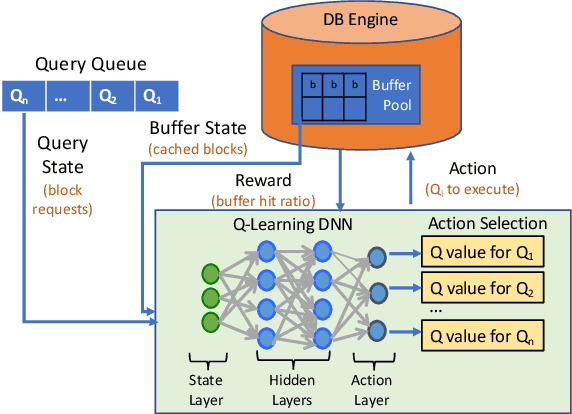
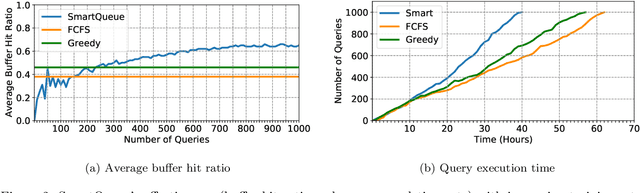
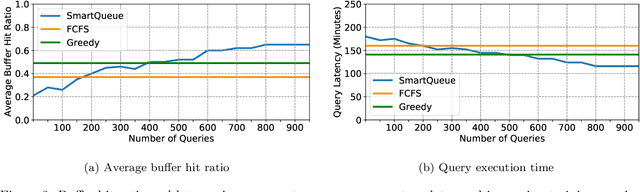
In this extended abstract, we propose a new technique for query scheduling with the explicit goal of reducing disk reads and thus implicitly increasing query performance. We introduce \system, a learned scheduler that leverages overlapping data reads among incoming queries and learns a scheduling strategy that improves cache hits. \system relies on deep reinforcement learning to produce workload-specific scheduling strategies that focus on long-term performance benefits while being adaptive to previously-unseen data access patterns. We present results from a proof-of-concept prototype, demonstrating that learned schedulers can offer significant performance improvements over hand-crafted scheduling heuristics. Ultimately, we make the case that this is a promising research direction in the intersection of machine learning and databases.
Flexible Operator Embeddings via Deep Learning
Jan 31, 2019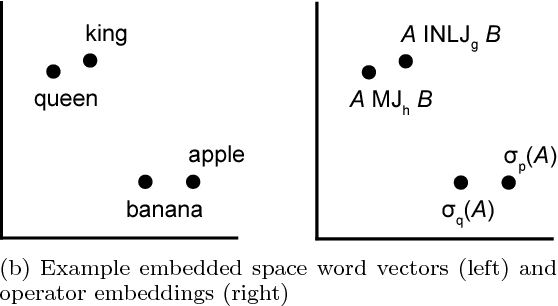
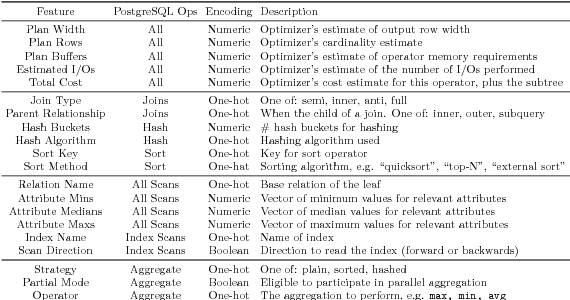

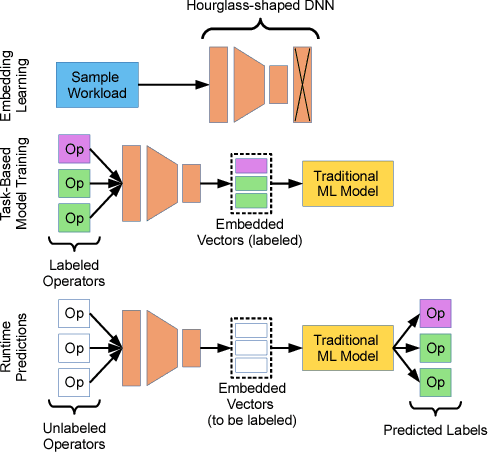
Integrating machine learning into the internals of database management systems requires significant feature engineering, a human effort-intensive process to determine the best way to represent the pieces of information that are relevant to a task. In addition to being labor intensive, the process of hand-engineering features must generally be repeated for each data management task, and may make assumptions about the underlying database that are not universally true. We introduce flexible operator embeddings, a deep learning technique for automatically transforming query operators into feature vectors that are useful for a multiple data management tasks and is custom-tailored to the underlying database. Our approach works by taking advantage of an operator's context, resulting in a neural network that quickly transforms sparse representations of query operators into dense, information-rich feature vectors. Experimentally, we show that our flexible operator embeddings perform well across a number of data management tasks, using both synthetic and real-world datasets.
Deep Reinforcement Learning for Join Order Enumeration
Mar 12, 2018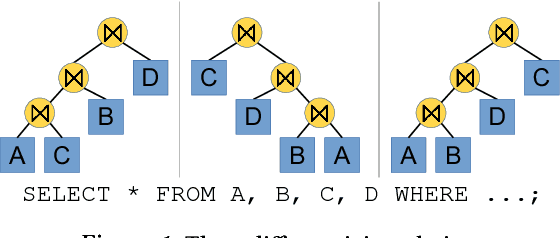
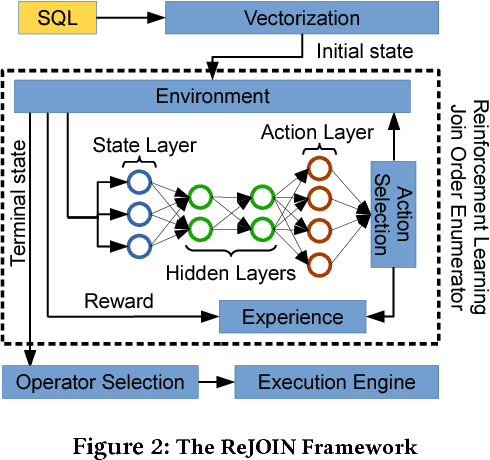
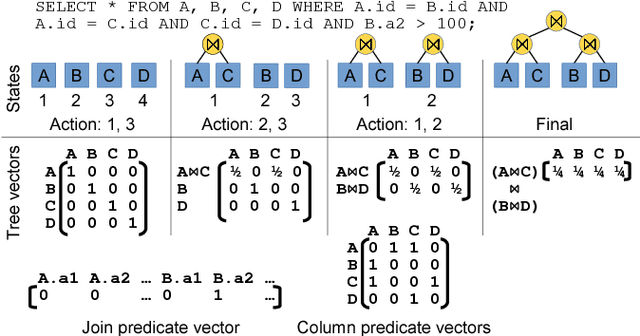
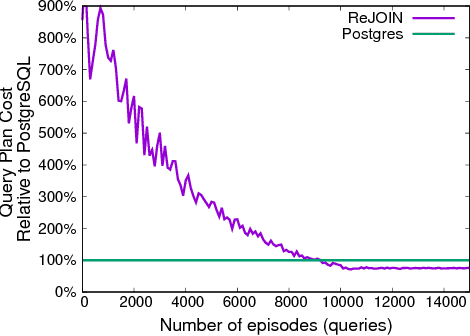
Join order selection plays a significant role in query performance. However, modern query optimizers typically employ static join enumeration algorithms that do not receive any feedback about the quality of the resulting plan. Hence, optimizers often repeatedly choose the same bad plan, as they do not have a mechanism for "learning from their mistakes". In this paper, we argue that existing deep reinforcement learning techniques can be applied to address this challenge. These techniques, powered by artificial neural networks, can automatically improve decision making by incorporating feedback from their successes and failures. Towards this goal, we present ReJOIN, a proof-of-concept join enumerator, and present preliminary results indicating that ReJOIN can match or outperform the PostgreSQL optimizer in terms of plan quality and join enumeration efficiency.