 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Interpretable Traffic Signal Control Policy
Paper and Code
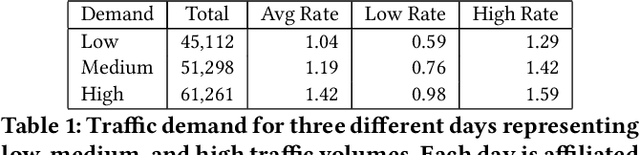
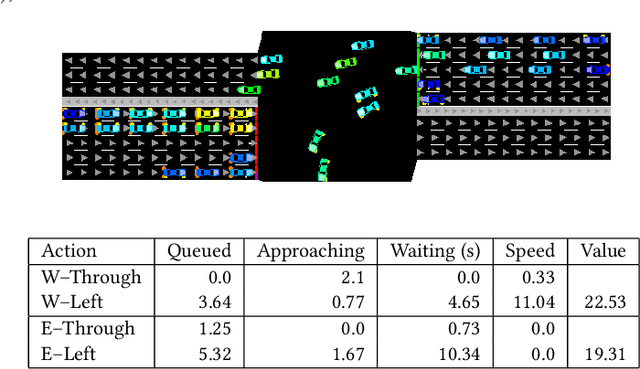

Signalized intersections are managed by controllers that assign right of way (green, yellow, and red lights) to non-conflicting directions. Optimizing the actuation policy of such controllers is expected to alleviate traffic congestion and its adverse impact. Given such a safety-critical domain, the affiliated actuation policy is required to be interpretable in a way that can be understood and regulated by a human. This paper presents and analyzes several on-line optimization techniques for tuning interpretable control functions. Although these techniques are defined in a general way, this paper assumes a specific class of interpretable control functions (polynomial functions) for analysis purposes. We show that such an interpretable policy function can be as effective as a deep neural network for approximating an optimized signal actuation policy. We present empirical evidence that supports the use of value-based reinforcement learning for on-line training of the control function. Specifically, we present and study three variants of the Deep Q-learning algorithm that allow the training of an interpretable policy function. Our Deep Regulatable Hardmax Q-learning variant is shown to be particularly effective in optimizing our interpretable actuation policy, resulting in up to 19.4% reduced vehicles delay compared to commonly deployed actuated signal controllers.