 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Ordinal Querying for Tuplewise Similarity Learning
Paper and Code

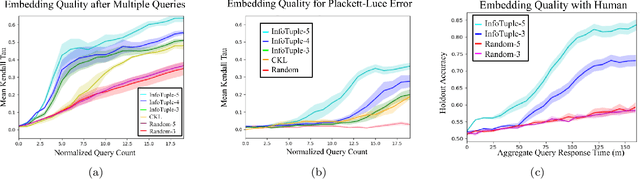
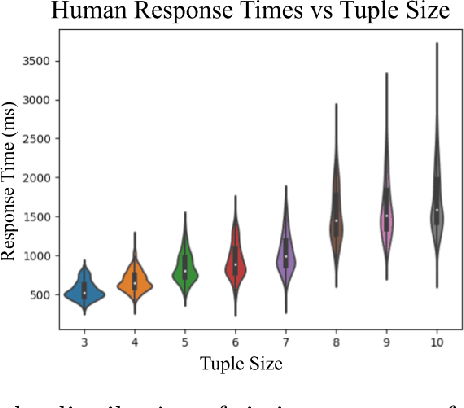
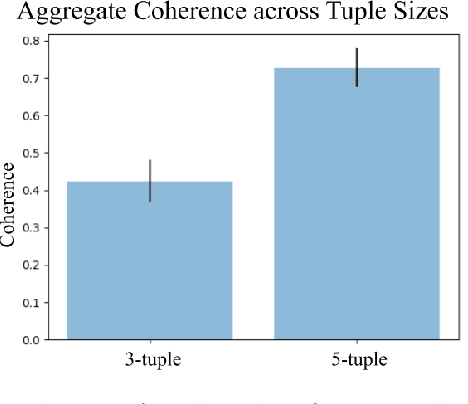
Many machine learning tasks such as clustering, classification, and dataset search benefit from embedding data points in a space where distances reflect notions of relative similarity as perceived by humans. A common way to construct such an embedding is to request triplet similarity queries to an oracle, comparing two objects with respect to a reference. This work generalizes triplet queries to tuple queries of arbitrary size that ask an oracle to rank multiple objects against a reference, and introduces an efficient and robust adaptive selection method called InfoTuple that uses a novel approach to mutual information maximization. We show that the performance of InfoTuple at various tuple sizes exceeds that of the state-of-the-art adaptive triplet selection method on synthetic tests and new human response datasets, and empirically demonstrate the significant gains in efficiency and query consistency achieved by querying larger tuples instead of triplets.