 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploration of Multicalibration Uniform Convergence Bounds
Paper and Code
Feb 09, 2022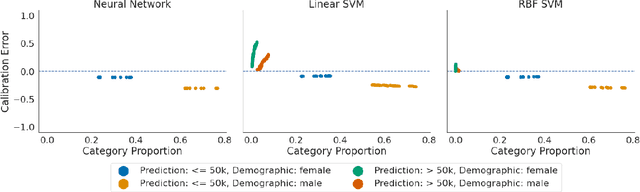
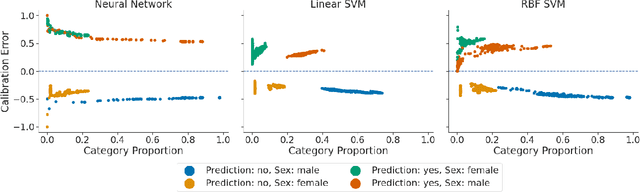
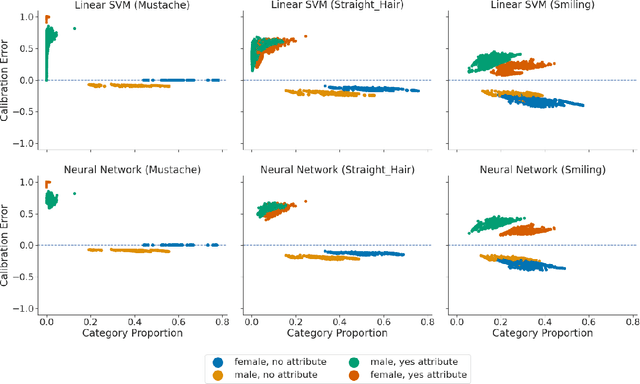
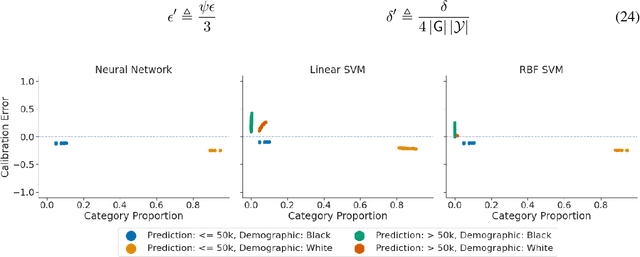
Recent works have investigated the sample complexity necessary for fair machine learning. The most advanced of such sample complexity bounds are developed by analyzing multicalibration uniform convergence for a given predictor class. We present a framework which yields multicalibration error uniform convergence bounds by reparametrizing sample complexities for Empirical Risk Minimization (ERM) learning. From this framework, we demonstrate that multicalibration error exhibits dependence on the classifier architecture as well as the underlying data distribution. We perform an experimental evaluation to investigate the behavior of multicalibration error for different families of classifiers. We compare the results of this evaluation to multicalibration error concentration bounds. Our investigation provides additional perspective on both algorithmic fairness and multicalibration error convergence bounds. Given the prevalence of ERM sample complexity bounds, our proposed framework enables machine learning practitioners to easily understand the convergence behavior of multicalibration error for a myriad of classifier architectures.