 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSITA: Learning Speaker-Invariant and Tone-Aware Speech Representations for Low-Resource Tonal Languages
Jan 14, 2026Tonal low-resource languages are widely spoken yet remain underserved by modern speech technology. A key challenge is learning representations that are robust to nuisance variation such as gender while remaining tone-aware for different lexical meanings. To address this, we propose SITA, a lightweight adaptation recipe that enforces Speaker-Invariance and Tone-Awareness for pretrained wav2vec-style encoders. SITA uses staged multi-objective training: (i) a cross-gender contrastive objective encourages lexical consistency across speakers, while a tone-repulsive loss prevents tone collapse by explicitly separating same-word different-tone realizations; and (ii) an auxiliary Connectionist Temporal Classification (CTC)-based ASR objective with distillation stabilizes recognition-relevant structure. We evaluate primarily on Hmong, a highly tonal and severely under-resourced language where off-the-shelf multilingual encoders fail to represent tone effectively. On a curated Hmong word corpus, SITA improves cross-gender lexical retrieval accuracy, while maintaining usable ASR accuracy relative to an ASR-adapted XLS-R teacher. We further observe similar gains when transferring the same recipe to Mandarin, suggesting SITA is a general, plug-in approach for adapting multilingual speech encoders to tonal languages.
No Preference Left Behind: Group Distributional Preference Optimization
Dec 28, 2024



Preferences within a group of people are not uniform but follow a distribution. While existing alignment methods like Direct Preference Optimization (DPO) attempt to steer models to reflect human preferences, they struggle to capture the distributional pluralistic preferences within a group. These methods often skew toward dominant preferences, overlooking the diversity of opinions, especially when conflicting preferences arise. To address this issue, we propose Group Distribution Preference Optimization (GDPO), a novel framework that aligns language models with the distribution of preferences within a group by incorporating the concept of beliefs that shape individual preferences. GDPO calibrates a language model using statistical estimation of the group's belief distribution and aligns the model with belief-conditioned preferences, offering a more inclusive alignment framework than traditional methods. In experiments using both synthetic controllable opinion generation and real-world movie review datasets, we show that DPO fails to align with the targeted belief distributions, while GDPO consistently reduces this alignment gap during training. Moreover, our evaluation metrics demonstrate that GDPO outperforms existing approaches in aligning with group distributional preferences, marking a significant advance in pluralistic alignment.
Towards Reliable and Empathetic Depression-Diagnosis-Oriented Chats
Apr 07, 2024Chatbots can serve as a viable tool for preliminary depression diagnosis via interactive conversations with potential patients. Nevertheless, the blend of task-oriented and chit-chat in diagnosis-related dialogues necessitates professional expertise and empathy. Such unique requirements challenge traditional dialogue frameworks geared towards single optimization goals. To address this, we propose an innovative ontology definition and generation framework tailored explicitly for depression diagnosis dialogues, combining the reliability of task-oriented conversations with the appeal of empathy-related chit-chat. We further apply the framework to D$^4$, the only existing public dialogue dataset on depression diagnosis-oriented chats. Exhaustive experimental results indicate significant improvements in task completion and emotional support generation in depression diagnosis, fostering a more comprehensive approach to task-oriented chat dialogue system development and its applications in digital mental health.
Empowering LLM-based Machine Translation with Cultural Awareness
May 23, 2023
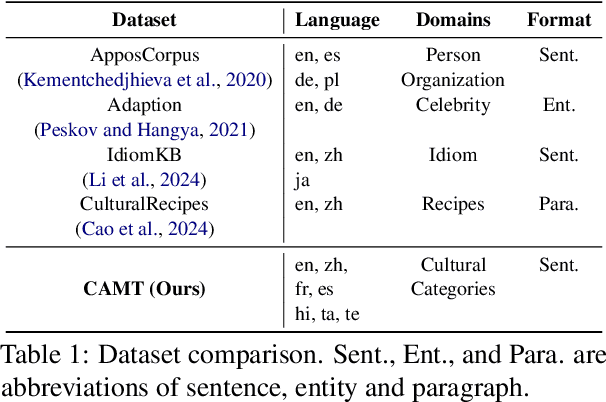


Traditional neural machine translation (NMT) systems often fail to translate sentences that contain culturally specific information. Most previous NMT methods have incorporated external cultural knowledge during training, which requires fine-tuning on low-frequency items specific to the culture. Recent in-context learning utilizes lightweight prompts to guide large language models (LLMs) to perform machine translation, however, whether such an approach works in terms of injecting culture awareness into machine translation remains unclear. To this end, we introduce a new data curation pipeline to construct a culturally relevant parallel corpus, enriched with annotations of cultural-specific entities. Additionally, we design simple but effective prompting strategies to assist this LLM-based translation. Extensive experiments show that our approaches can largely help incorporate cultural knowledge into LLM-based machine translation, outperforming traditional NMT systems in translating cultural-specific sentences.
D4: a Chinese Dialogue Dataset for Depression-Diagnosis-Oriented Chat
May 24, 2022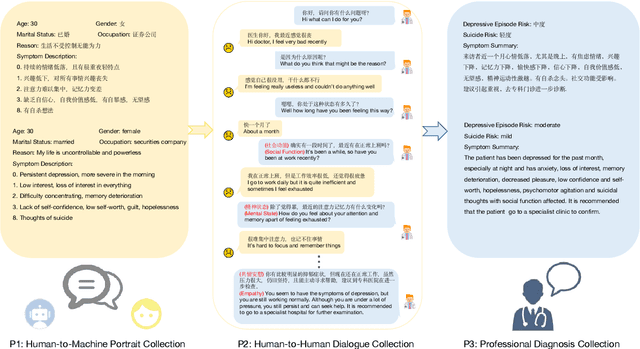
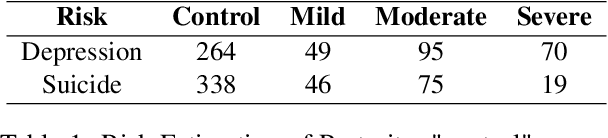
In a depression-diagnosis-directed clinical session, doctors initiate a conversation with ample emotional support that guides the patients to expose their symptoms based on clinical diagnosis criteria. Such a dialog is a combination of task-oriented and chitchat, different from traditional single-purpose human-machine dialog systems. However, due to the social stigma associated with mental illness, the dialogue data related to depression consultation and diagnosis are rarely disclosed. Though automatic dialogue-based diagnosis foresees great application potential, data sparsity has become one of the major bottlenecks restricting research on such task-oriented chat dialogues. Based on clinical depression diagnostic criteria ICD-11 and DSM-5, we construct the D$^4$: a Chinese Dialogue Dataset for Depression-Diagnosis-Oriented Chat which simulates the dialogue between doctors and patients during the diagnosis of depression, including diagnosis results and symptom summary given by professional psychiatrists for each dialogue.Finally, we finetune on state-of-the-art pre-training models and respectively present our dataset baselines on four tasks including response generation, topic prediction, dialog summary, and severity classification of depressive episode and suicide risk. Multi-scale evaluation results demonstrate that a more empathy-driven and diagnostic-accurate consultation dialogue system trained on our dataset can be achieved compared to rule-based bots.