 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-effects transformers for hierarchical adaptation
Paper and Code
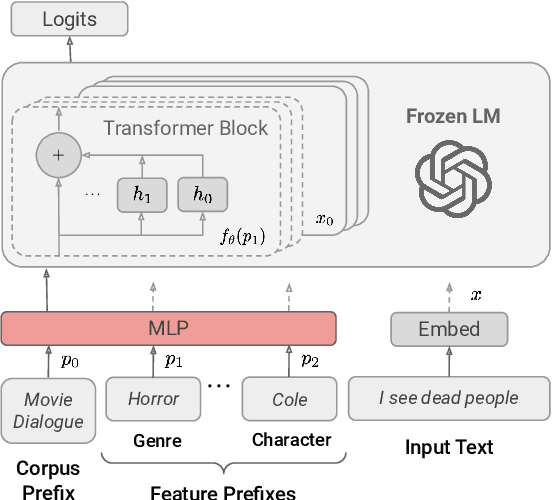
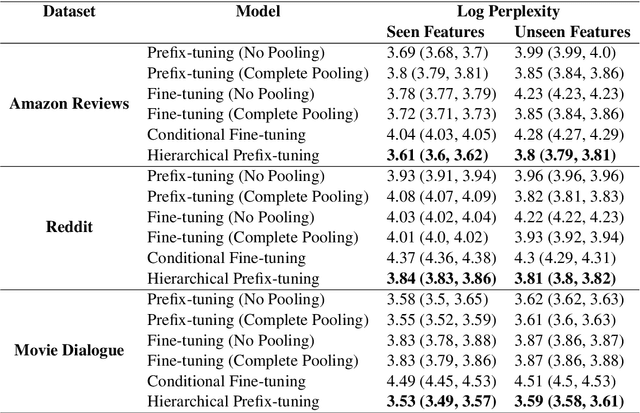
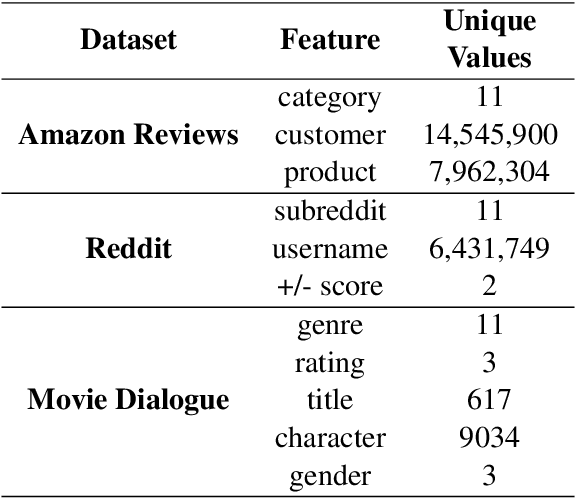
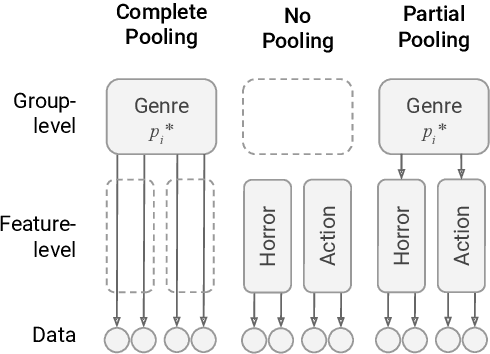
Language use differs dramatically from context to context. To some degree, modern language models like GPT-3 are able to account for such variance by conditioning on a string of previous input text, or prompt. Yet prompting is ineffective when contexts are sparse, out-of-sample, or extra-textual; for instance, accounting for when and where the text was produced or who produced it. In this paper, we introduce the mixed-effects transformer (MET), a novel approach for learning hierarchically-structured prefixes -- lightweight modules prepended to the input -- to account for structured variation. Specifically, we show how the popular class of mixed-effects models may be extended to transformer-based architectures using a regularized prefix-tuning procedure with dropout. We evaluate this approach on several domain-adaptation benchmarks, finding that it efficiently adapts to novel contexts with minimal data while still effectively generalizing to unseen contexts.