 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Molecular Image Recognition: A Graph Generation Approach
Paper and Code
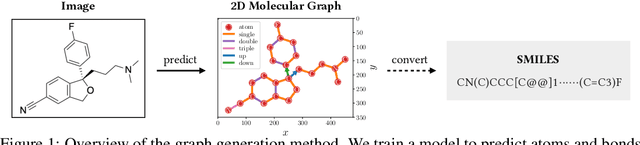
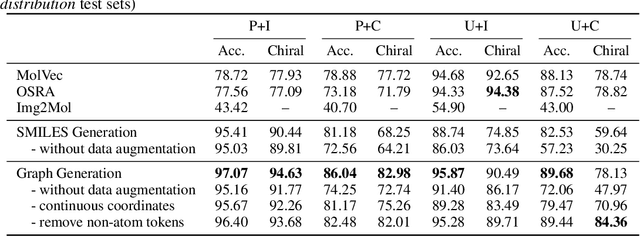
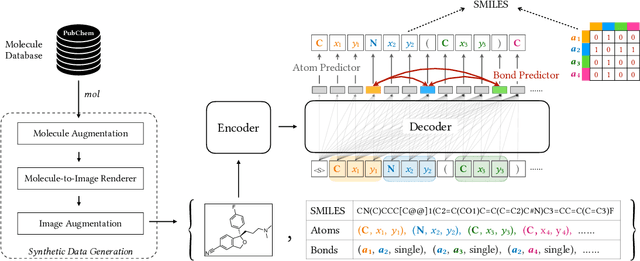
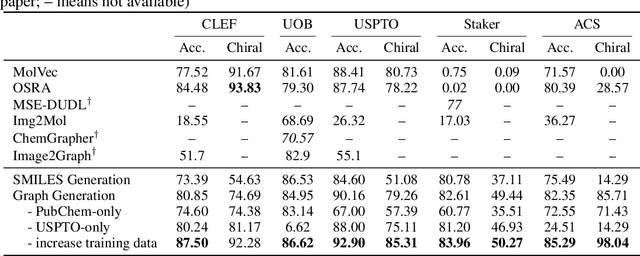
Molecular image recognition is a fundamental task in information extraction from chemistry literature. Previous data-driven models formulate it as an image-to-sequence task, to generate a sequential representation of the molecule (e.g. SMILES string) from its graphical representation. Although they perform adequately on certain benchmarks, these models are not robust in real-world situations, where molecular images differ in style, quality, and chemical patterns. In this paper, we propose a novel graph generation approach that explicitly predicts atoms and bonds, along with their geometric layouts, to construct the molecular graph. We develop data augmentation strategies for molecules and images to increase the robustness of our model against domain shifts. Our model is flexible to incorporate chemistry constraints, and produces more interpretable predictions than SMILES. In experiments on both synthetic and realistic molecular images, our model significantly outperforms previous models, achieving 84-93% accuracy on five benchmarks. We also conduct human evaluation and show that our model reduces the time for a chemist to extract molecular structures from images by roughly 50%.