 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenChemIE: An Information Extraction Toolkit For Chemistry Literature
Apr 01, 2024



Information extraction from chemistry literature is vital for constructing up-to-date reaction databases for data-driven chemistry. Complete extraction requires combining information across text, tables, and figures, whereas prior work has mainly investigated extracting reactions from single modalities. In this paper, we present OpenChemIE to address this complex challenge and enable the extraction of reaction data at the document level. OpenChemIE approaches the problem in two steps: extracting relevant information from individual modalities and then integrating the results to obtain a final list of reactions. For the first step, we employ specialized neural models that each address a specific task for chemistry information extraction, such as parsing molecules or reactions from text or figures. We then integrate the information from these modules using chemistry-informed algorithms, allowing for the extraction of fine-grained reaction data from reaction condition and substrate scope investigations. Our machine learning models attain state-of-the-art performance when evaluated individually, and we meticulously annotate a challenging dataset of reaction schemes with R-groups to evaluate our pipeline as a whole, achieving an F1 score of 69.5%. Additionally, the reaction extraction results of \ours attain an accuracy score of 64.3% when directly compared against the Reaxys chemical database. We provide OpenChemIE freely to the public as an open-source package, as well as through a web interface.
Accented Speech Recognition Inspired by Human Perception
Apr 09, 2021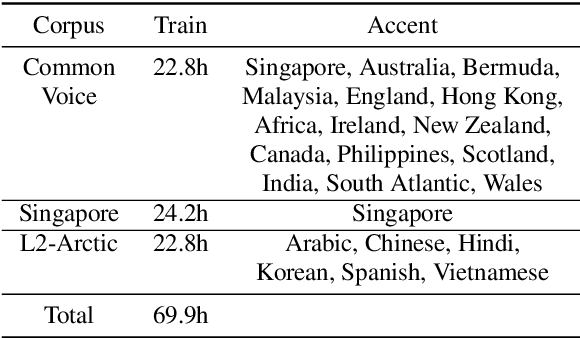
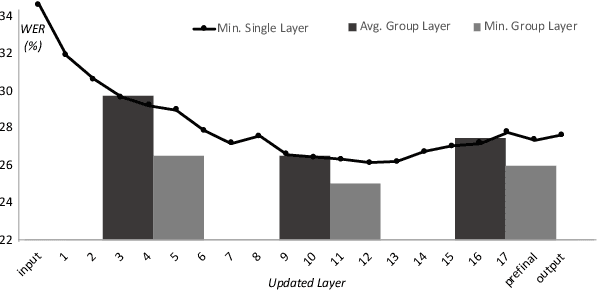
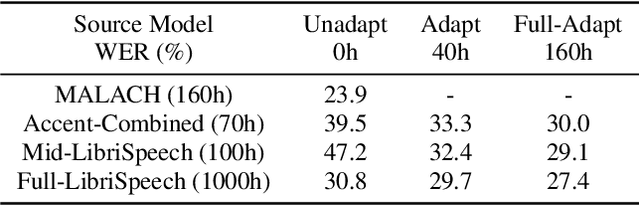
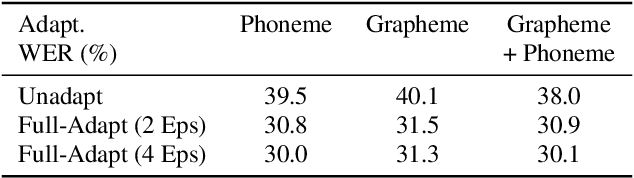
While improvements have been made in automatic speech recognition performance over the last several years, machines continue to have significantly lower performance on accented speech than humans. In addition, the most significant improvements on accented speech primarily arise by overwhelming the problem with hundreds or even thousands of hours of data. Humans typically require much less data to adapt to a new accent. This paper explores methods that are inspired by human perception to evaluate possible performance improvements for recognition of accented speech, with a specific focus on recognizing speech with a novel accent relative to that of the training data. Our experiments are run on small, accessible datasets that are available to the research community. We explore four methodologies: pre-exposure to multiple accents, grapheme and phoneme-based pronunciations, dropout (to improve generalization to a novel accent), and the identification of the layers in the neural network that can specifically be associated with accent modeling. Our results indicate that methods based on human perception are promising in reducing WER and understanding how accented speech is modeled in neural networks for novel accents.