 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccented Speech Recognition Inspired by Human Perception
Apr 09, 2021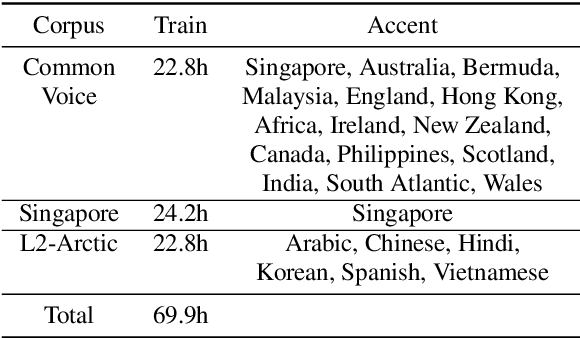
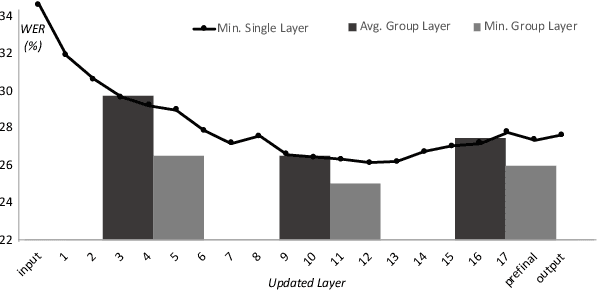
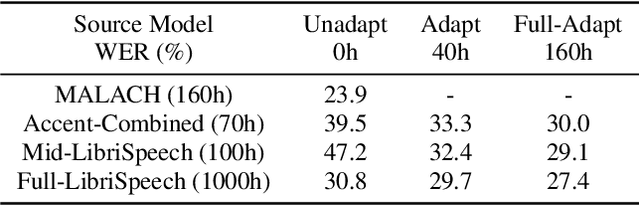
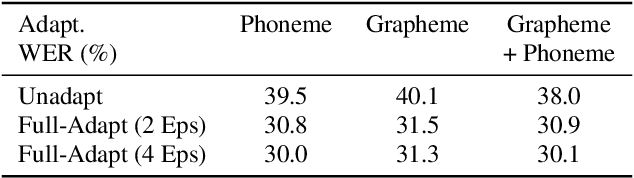
While improvements have been made in automatic speech recognition performance over the last several years, machines continue to have significantly lower performance on accented speech than humans. In addition, the most significant improvements on accented speech primarily arise by overwhelming the problem with hundreds or even thousands of hours of data. Humans typically require much less data to adapt to a new accent. This paper explores methods that are inspired by human perception to evaluate possible performance improvements for recognition of accented speech, with a specific focus on recognizing speech with a novel accent relative to that of the training data. Our experiments are run on small, accessible datasets that are available to the research community. We explore four methodologies: pre-exposure to multiple accents, grapheme and phoneme-based pronunciations, dropout (to improve generalization to a novel accent), and the identification of the layers in the neural network that can specifically be associated with accent modeling. Our results indicate that methods based on human perception are promising in reducing WER and understanding how accented speech is modeled in neural networks for novel accents.