 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-MC-Affect: LLM-Based Monte Carlo Modeling of Affective Trajectories and Latent Ambiguity for Interpersonal Dynamic Insight
Jan 07, 2026Emotional coordination is a core property of human interaction that shapes how relational meaning is constructed in real time. While text-based affect inference has become increasingly feasible, prior approaches often treat sentiment as a deterministic point estimate for individual speakers, failing to capture the inherent subjectivity, latent ambiguity, and sequential coupling found in mutual exchanges. We introduce LLM-MC-Affect, a probabilistic framework that characterizes emotion not as a static label, but as a continuous latent probability distribution defined over an affective space. By leveraging stochastic LLM decoding and Monte Carlo estimation, the methodology approximates these distributions to derive high-fidelity sentiment trajectories that explicitly quantify both central affective tendencies and perceptual ambiguity. These trajectories enable a structured analysis of interpersonal coupling through sequential cross-correlation and slope-based indicators, identifying leading or lagging influences between interlocutors. To validate the interpretive capacity of this approach, we utilize teacher-student instructional dialogues as a representative case study, where our quantitative indicators successfully distill high-level interaction insights such as effective scaffolding. This work establishes a scalable and deployable pathway for understanding interpersonal dynamics, offering a generalizable solution that extends beyond education to broader social and behavioral research.
FLoRIST: Singular Value Thresholding for Efficient and Accurate Federated Fine-Tuning of Large Language Models
Jun 10, 2025Integrating Low-Rank Adaptation (LoRA) into federated learning offers a promising solution for parameter-efficient fine-tuning of Large Language Models (LLMs) without sharing local data. However, several methods designed for federated LoRA present significant challenges in balancing communication efficiency, model accuracy, and computational cost, particularly among heterogeneous clients. These methods either rely on simplistic averaging of local adapters, which introduces aggregation noise, require transmitting large stacked local adapters, leading to poor communication efficiency, or necessitate reconstructing memory-dense global weight-update matrix and performing computationally expensive decomposition to design client-specific low-rank adapters. In this work, we propose FLoRIST, a federated fine-tuning framework that achieves mathematically accurate aggregation without incurring high communication or computational overhead. Instead of constructing the full global weight-update matrix at the server, FLoRIST employs an efficient decomposition pipeline by performing singular value decomposition on stacked local adapters separately. This approach operates within a compact intermediate space to represent the accumulated information from local LoRAs. We introduce tunable singular value thresholding for server-side optimal rank selection to construct a pair of global low-rank adapters shared by all clients. Extensive empirical evaluations across multiple datasets and LLMs demonstrate that FLoRIST consistently strikes the best balance between superior communication efficiency and competitive performance in both homogeneous and heterogeneous setups.
NetDistiller: Empowering Tiny Deep Learning via In-Situ Distillation
Oct 24, 2023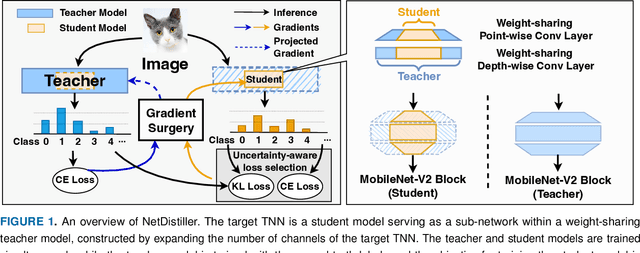
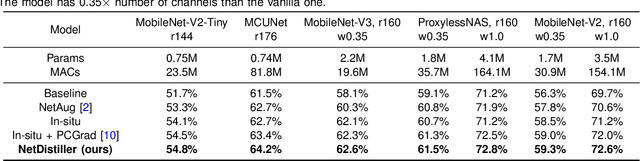
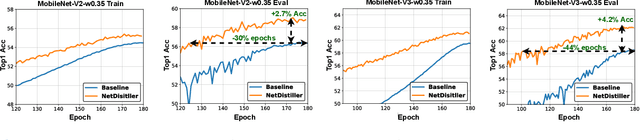
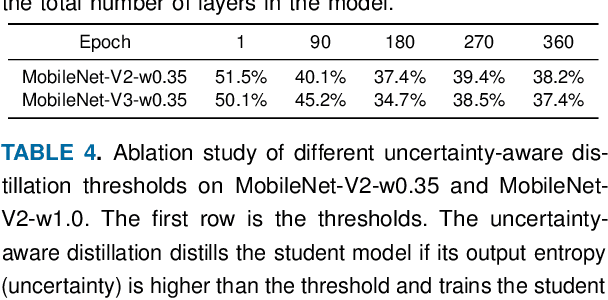
Boosting the task accuracy of tiny neural networks (TNNs) has become a fundamental challenge for enabling the deployments of TNNs on edge devices which are constrained by strict limitations in terms of memory, computation, bandwidth, and power supply. To this end, we propose a framework called NetDistiller to boost the achievable accuracy of TNNs by treating them as sub-networks of a weight-sharing teacher constructed by expanding the number of channels of the TNN. Specifically, the target TNN model is jointly trained with the weight-sharing teacher model via (1) gradient surgery to tackle the gradient conflicts between them and (2) uncertainty-aware distillation to mitigate the overfitting of the teacher model. Extensive experiments across diverse tasks validate NetDistiller's effectiveness in boosting TNNs' achievable accuracy over state-of-the-art methods. Our code is available at https://github.com/GATECH-EIC/NetDistiller.
ViTALiTy: Unifying Low-rank and Sparse Approximation for Vision Transformer Acceleration with a Linear Taylor Attention
Nov 09, 2022Vision Transformer (ViT) has emerged as a competitive alternative to convolutional neural networks for various computer vision applications. Specifically, ViT multi-head attention layers make it possible to embed information globally across the overall image. Nevertheless, computing and storing such attention matrices incurs a quadratic cost dependency on the number of patches, limiting its achievable efficiency and scalability and prohibiting more extensive real-world ViT applications on resource-constrained devices. Sparse attention has been shown to be a promising direction for improving hardware acceleration efficiency for NLP models. However, a systematic counterpart approach is still missing for accelerating ViT models. To close the above gap, we propose a first-of-its-kind algorithm-hardware codesigned framework, dubbed ViTALiTy, for boosting the inference efficiency of ViTs. Unlike sparsity-based Transformer accelerators for NLP, ViTALiTy unifies both low-rank and sparse components of the attention in ViTs. At the algorithm level, we approximate the dot-product softmax operation via first-order Taylor attention with row-mean centering as the low-rank component to linearize the cost of attention blocks and further boost the accuracy by incorporating a sparsity-based regularization. At the hardware level, we develop a dedicated accelerator to better leverage the resulting workload and pipeline from ViTALiTy's linear Taylor attention which requires the execution of only the low-rank component, to further boost the hardware efficiency. Extensive experiments and ablation studies validate that ViTALiTy offers boosted end-to-end efficiency (e.g., $3\times$ faster and $3\times$ energy-efficient) under comparable accuracy, with respect to the state-of-the-art solution.