 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Cudgel Network for Real-Time Semantic Segmentation
Mar 05, 2025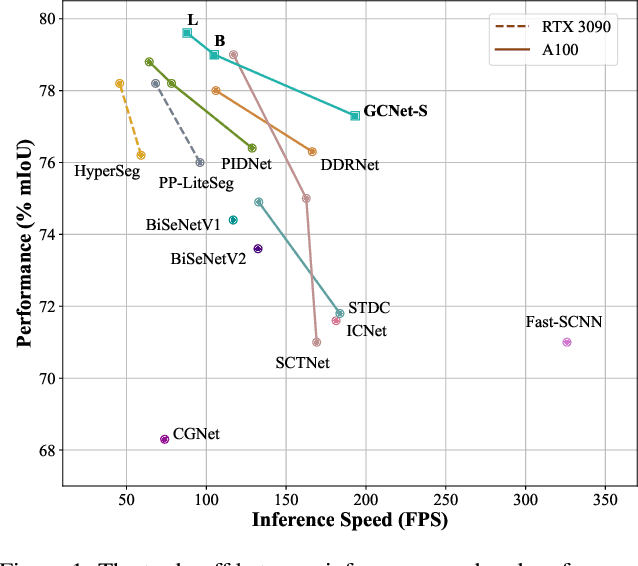
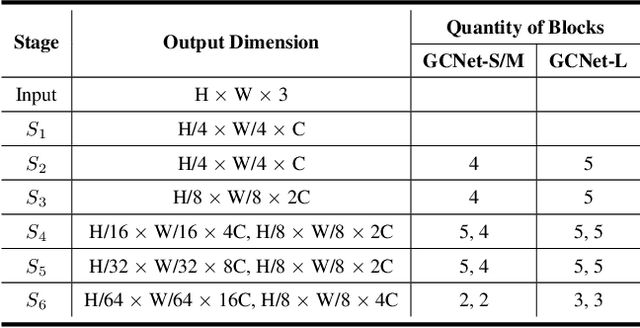
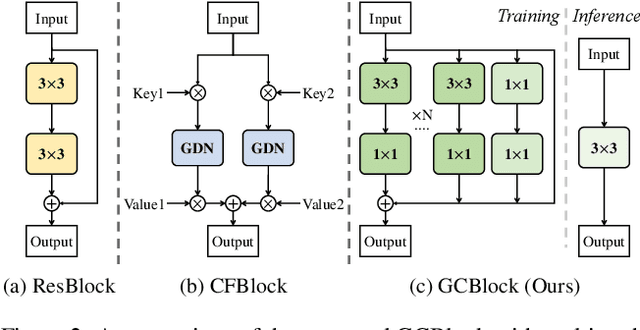
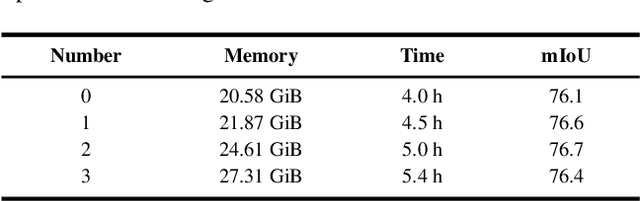
Recent real-time semantic segmentation models, whether single-branch or multi-branch, achieve good performance and speed. However, their speed is limited by multi-path blocks, and some depend on high-performance teacher models for training. To overcome these issues, we propose Golden Cudgel Network (GCNet). Specifically, GCNet uses vertical multi-convolutions and horizontal multi-paths for training, which are reparameterized into a single convolution for inference, optimizing both performance and speed. This design allows GCNet to self-enlarge during training and self-contract during inference, effectively becoming a "teacher model" without needing external ones. Experimental results show that GCNet outperforms existing state-of-the-art models in terms of performance and speed on the Cityscapes, CamVid, and Pascal VOC 2012 datasets. The code is available at https://github.com/gyyang23/GCNet.
Reparameterizable Dual-Resolution Network for Real-time Semantic Segmentation
Jun 18, 2024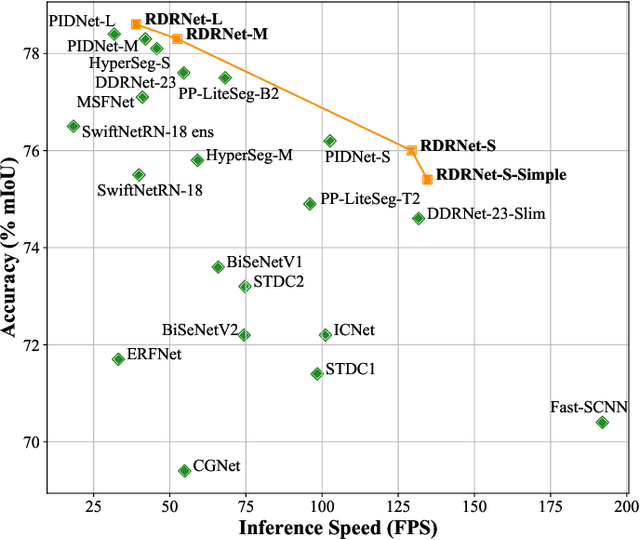
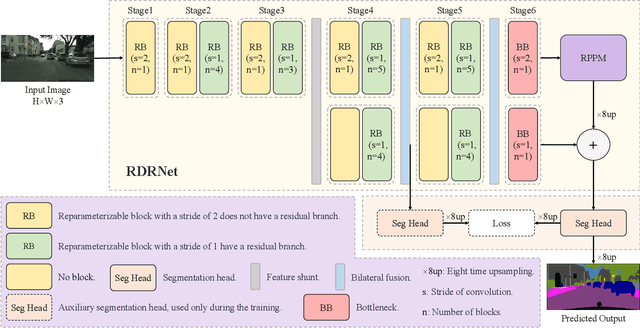
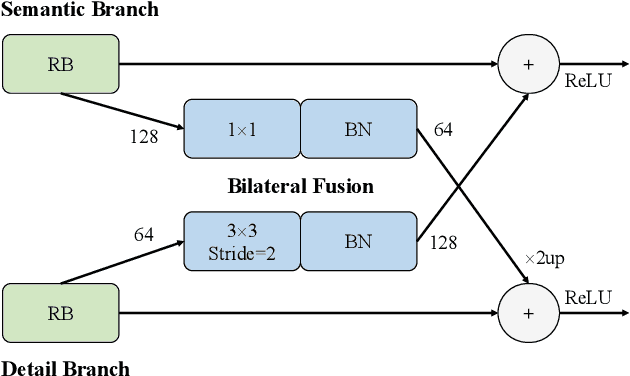
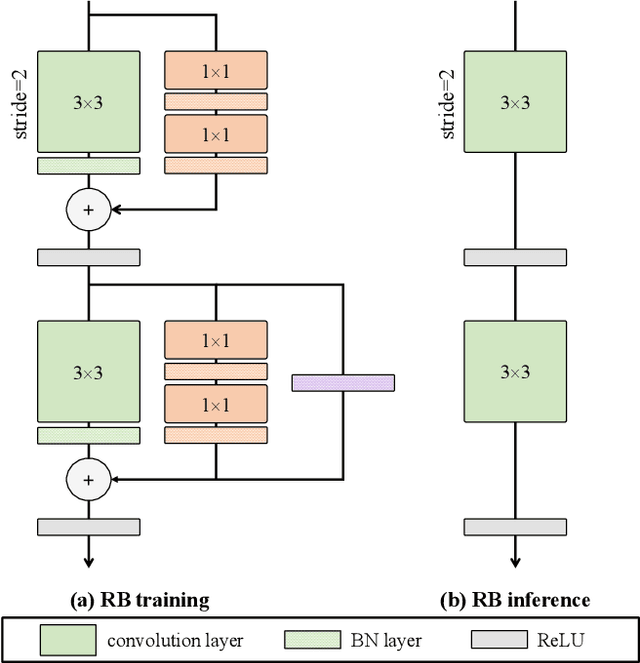
Semantic segmentation plays a key role in applications such as autonomous driving and medical image. Although existing real-time semantic segmentation models achieve a commendable balance between accuracy and speed, their multi-path blocks still affect overall speed. To address this issue, this study proposes a Reparameterizable Dual-Resolution Network (RDRNet) dedicated to real-time semantic segmentation. Specifically, RDRNet employs a two-branch architecture, utilizing multi-path blocks during training and reparameterizing them into single-path blocks during inference, thereby enhancing both accuracy and inference speed simultaneously. Furthermore, we propose the Reparameterizable Pyramid Pooling Module (RPPM) to enhance the feature representation of the pyramid pooling module without increasing its inference time. Experimental results on the Cityscapes, CamVid, and Pascal VOC 2012 datasets demonstrate that RDRNet outperforms existing state-of-the-art models in terms of both performance and speed. The code is available at https://github.com/gyyang23/RDRNet.
AFPN: Asymptotic Feature Pyramid Network for Object Detection
Jun 28, 2023



Multi-scale features are of great importance in encoding objects with scale variance in object detection tasks. A common strategy for multi-scale feature extraction is adopting the classic top-down and bottom-up feature pyramid networks. However, these approaches suffer from the loss or degradation of feature information, impairing the fusion effect of non-adjacent levels. This paper proposes an asymptotic feature pyramid network (AFPN) to support direct interaction at non-adjacent levels. AFPN is initiated by fusing two adjacent low-level features and asymptotically incorporates higher-level features into the fusion process. In this way, the larger semantic gap between non-adjacent levels can be avoided. Given the potential for multi-object information conflicts to arise during feature fusion at each spatial location, adaptive spatial fusion operation is further utilized to mitigate these inconsistencies. We incorporate the proposed AFPN into both two-stage and one-stage object detection frameworks and evaluate with the MS-COCO 2017 validation and test datasets. Experimental evaluation shows that our method achieves more competitive results than other state-of-the-art feature pyramid networks. The code is available at \href{https://github.com/gyyang23/AFPN}{https://github.com/gyyang23/AFPN}.
Mid-level Representation Enhancement and Graph Embedded Uncertainty Suppressing for Facial Expression Recognition
Jul 27, 2022

Facial expression is an essential factor in conveying human emotional states and intentions. Although remarkable advancement has been made in facial expression recognition (FER) task, challenges due to large variations of expression patterns and unavoidable data uncertainties still remain. In this paper, we propose mid-level representation enhancement (MRE) and graph embedded uncertainty suppressing (GUS) addressing these issues. On one hand, MRE is introduced to avoid expression representation learning being dominated by a limited number of highly discriminative patterns. On the other hand, GUS is introduced to suppress the feature ambiguity in the representation space. The proposed method not only has stronger generalization capability to handle different variations of expression patterns but also more robustness to capture expression representations. Experimental evaluation on Aff-Wild2 have verified the effectiveness of the proposed method.