 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Cudgel Network for Real-Time Semantic Segmentation
Mar 05, 2025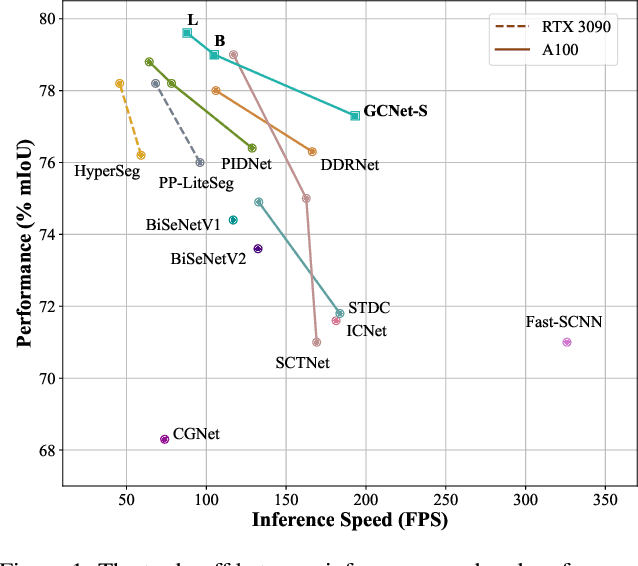
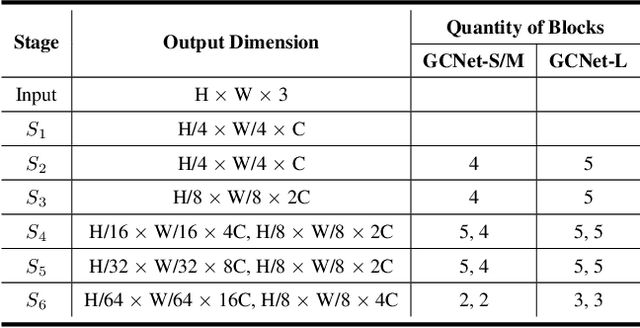
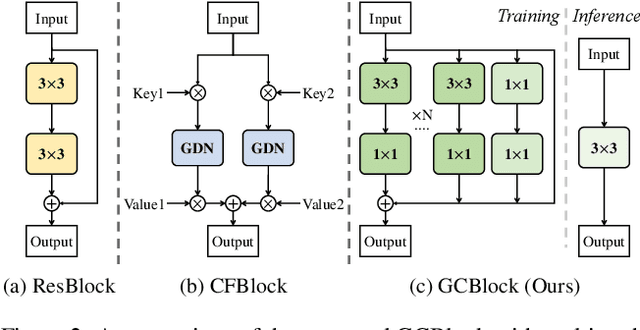
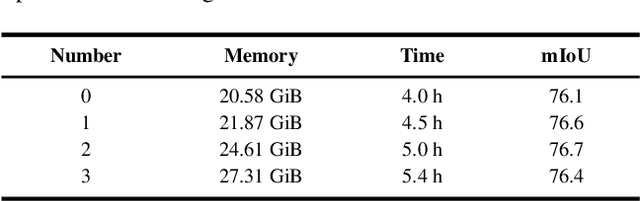
Recent real-time semantic segmentation models, whether single-branch or multi-branch, achieve good performance and speed. However, their speed is limited by multi-path blocks, and some depend on high-performance teacher models for training. To overcome these issues, we propose Golden Cudgel Network (GCNet). Specifically, GCNet uses vertical multi-convolutions and horizontal multi-paths for training, which are reparameterized into a single convolution for inference, optimizing both performance and speed. This design allows GCNet to self-enlarge during training and self-contract during inference, effectively becoming a "teacher model" without needing external ones. Experimental results show that GCNet outperforms existing state-of-the-art models in terms of performance and speed on the Cityscapes, CamVid, and Pascal VOC 2012 datasets. The code is available at https://github.com/gyyang23/GCNet.
Reparameterizable Dual-Resolution Network for Real-time Semantic Segmentation
Jun 18, 2024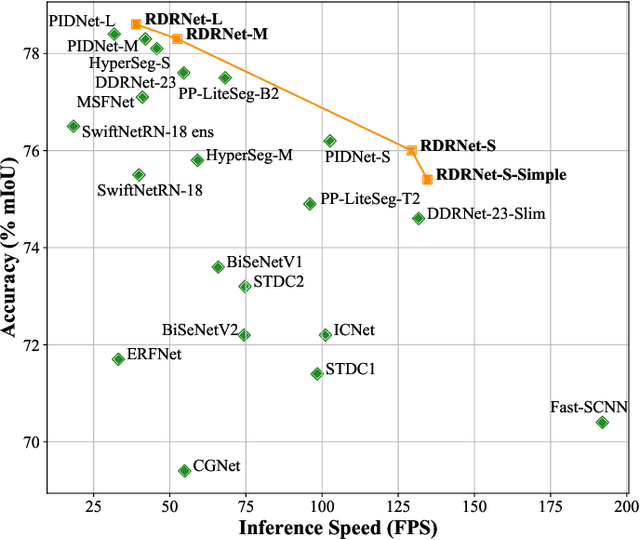
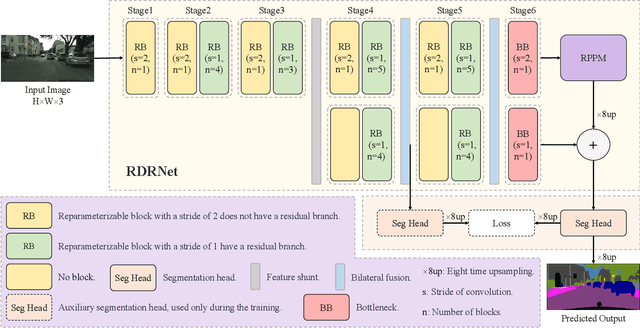
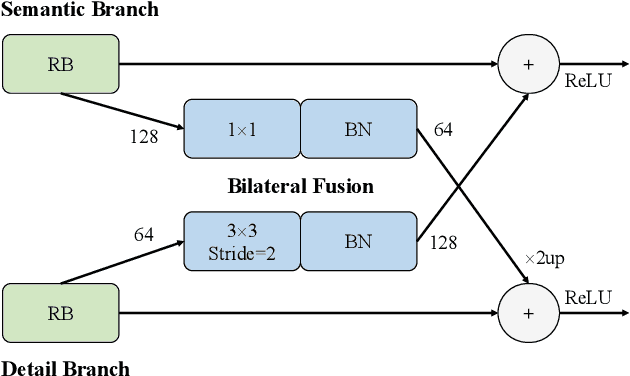
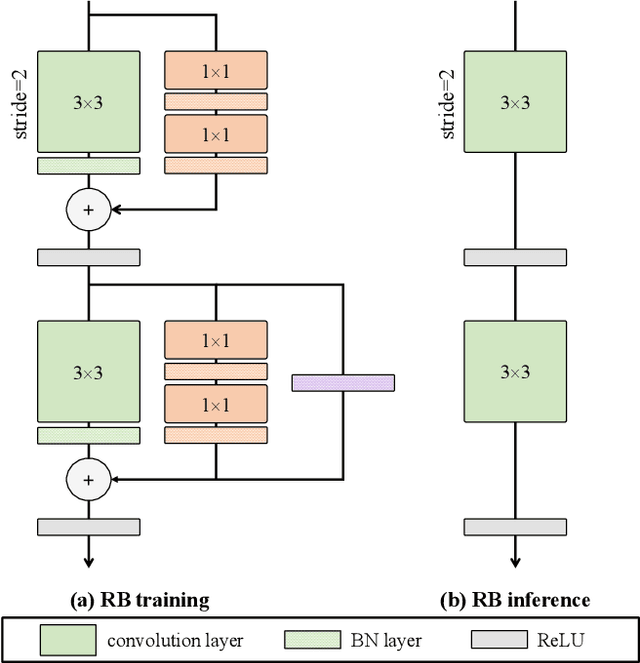
Semantic segmentation plays a key role in applications such as autonomous driving and medical image. Although existing real-time semantic segmentation models achieve a commendable balance between accuracy and speed, their multi-path blocks still affect overall speed. To address this issue, this study proposes a Reparameterizable Dual-Resolution Network (RDRNet) dedicated to real-time semantic segmentation. Specifically, RDRNet employs a two-branch architecture, utilizing multi-path blocks during training and reparameterizing them into single-path blocks during inference, thereby enhancing both accuracy and inference speed simultaneously. Furthermore, we propose the Reparameterizable Pyramid Pooling Module (RPPM) to enhance the feature representation of the pyramid pooling module without increasing its inference time. Experimental results on the Cityscapes, CamVid, and Pascal VOC 2012 datasets demonstrate that RDRNet outperforms existing state-of-the-art models in terms of both performance and speed. The code is available at https://github.com/gyyang23/RDRNet.
Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration
Apr 05, 2024



The rise of multi-agent systems, especially the success of multi-agent reinforcement learning (MARL), is reshaping our future across diverse domains like autonomous vehicle networks. However, MARL still faces significant challenges, particularly in achieving zero-shot scalability, which allows trained MARL models to be directly applied to unseen tasks with varying numbers of agents. In addition, real-world multi-agent systems usually contain agents with different functions and strategies, while the existing scalable MARL methods only have limited heterogeneity. To address this, we propose a novel MARL framework named Scalable and Heterogeneous Proximal Policy Optimization (SHPPO), integrating heterogeneity into parameter-shared PPO-based MARL networks. we first leverage a latent network to adaptively learn strategy patterns for each agent. Second, we introduce a heterogeneous layer for decision-making, whose parameters are specifically generated by the learned latent variables. Our approach is scalable as all the parameters are shared except for the heterogeneous layer, and gains both inter-individual and temporal heterogeneity at the same time. We implement our approach based on the state-of-the-art backbone PPO-based algorithm as SHPPO, while our approach is agnostic to the backbone and can be seamlessly plugged into any parameter-shared MARL method. SHPPO exhibits superior performance over the baselines such as MAPPO and HAPPO in classic MARL environments like Starcraft Multi-Agent Challenge (SMAC) and Google Research Football (GRF), showcasing enhanced zero-shot scalability and offering insights into the learned latent representation's impact on team performance by visualization.
Scalable Communication for Multi-Agent Reinforcement Learning via Transformer-Based Email Mechanism
Jan 05, 2023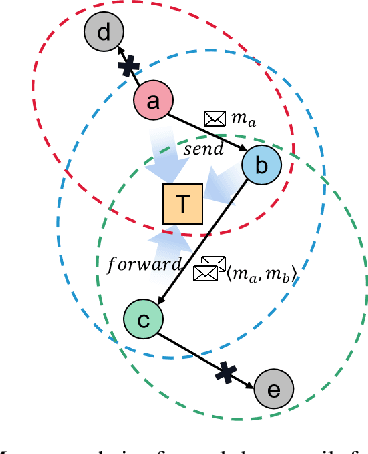
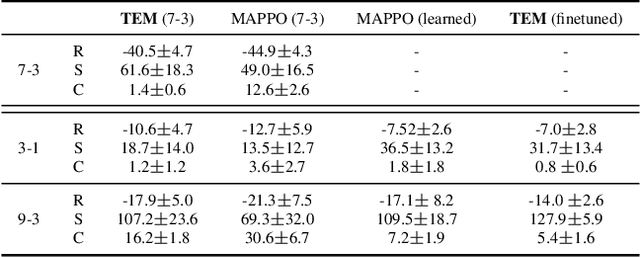
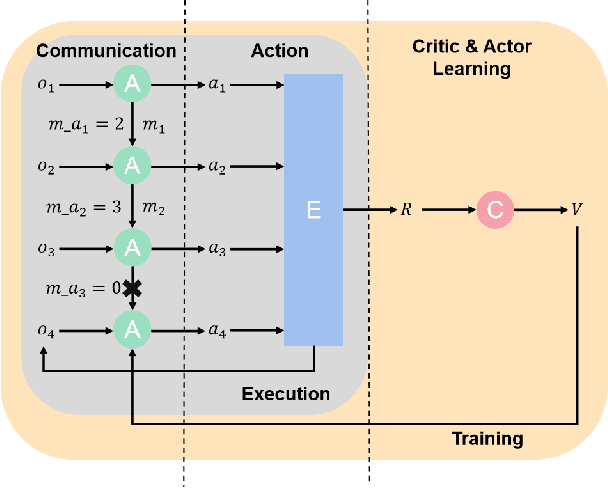
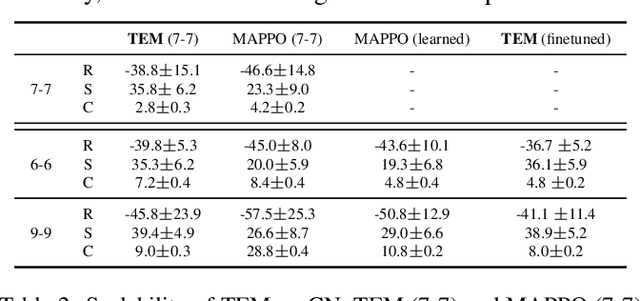
Communication can impressively improve cooperation in multi-agent reinforcement learning (MARL), especially for partially-observed tasks. However, existing works either broadcast the messages leading to information redundancy, or learn targeted communication by modeling all the other agents as targets, which is not scalable when the number of agents varies. In this work, to tackle the scalability problem of MARL communication for partially-observed tasks, we propose a novel framework Transformer-based Email Mechanism (TEM). The agents adopt local communication to send messages only to the ones that can be observed without modeling all the agents. Inspired by human cooperation with email forwarding, we design message chains to forward information to cooperate with the agents outside the observation range. We introduce Transformer to encode and decode the message chain to choose the next receiver selectively. Empirically, TEM outperforms the baselines on multiple cooperative MARL benchmarks. When the number of agents varies, TEM maintains superior performance without further training.
Adaptive Unfolding Total Variation Network for Low-Light Image Enhancement
Oct 07, 2021
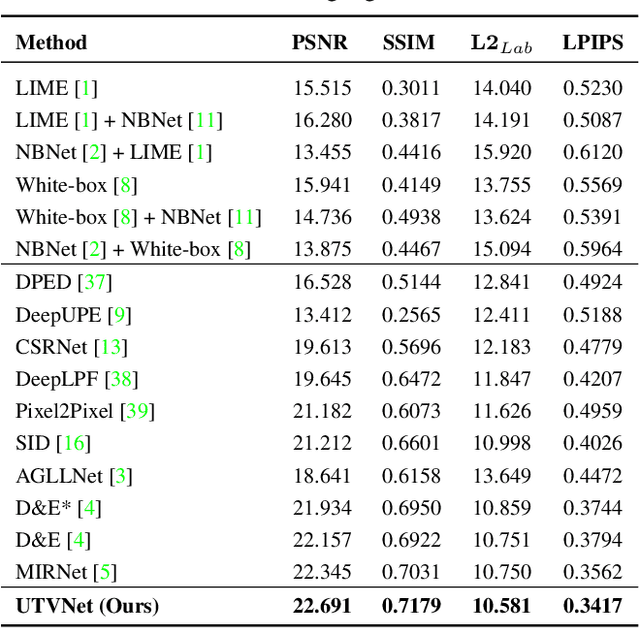
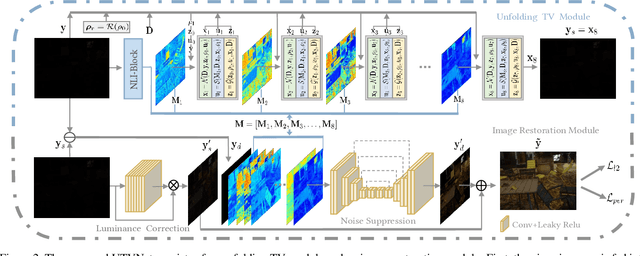

Real-world low-light images suffer from two main degradations, namely, inevitable noise and poor visibility. Since the noise exhibits different levels, its estimation has been implemented in recent works when enhancing low-light images from raw Bayer space. When it comes to sRGB color space, the noise estimation becomes more complicated due to the effect of the image processing pipeline. Nevertheless, most existing enhancing algorithms in sRGB space only focus on the low visibility problem or suppress the noise under a hypothetical noise level, leading them impractical due to the lack of robustness. To address this issue,we propose an adaptive unfolding total variation network (UTVNet), which approximates the noise level from the real sRGB low-light image by learning the balancing parameter in the model-based denoising method with total variation regularization. Meanwhile, we learn the noise level map by unrolling the corresponding minimization process for providing the inferences of smoothness and fidelity constraints. Guided by the noise level map, our UTVNet can recover finer details and is more capable to suppress noise in real captured low-light scenes. Extensive experiments on real-world low-light images clearly demonstrate the superior performance of UTVNet over state-of-the-art methods.