 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemPO: Self-Memory Policy Optimization for Long-Horizon Agents
Feb 28, 2026Long-horizon agents face the challenge of growing context size during interaction with environment, which degrades the performance and stability. Existing methods typically introduce the external memory module and look up the relevant information from the stored memory, which prevents the model itself from proactively managing its memory content and aligning with the agent's overarching task objectives. To address these limitations, we propose the self-memory policy optimization algorithm (MemPO), which enables the agent (policy model) to autonomously summarize and manage their memory during interaction with environment. By improving the credit assignment mechanism based on memory effectiveness, the policy model can selectively retain crucial information, significantly reducing token consumption while preserving task performance. Extensive experiments and analyses confirm that MemPO achieves absolute F1 score gains of 25.98% over the base model and 7.1% over the previous SOTA baseline, while reducing token usage by 67.58% and 73.12%.
DeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints
Jan 26, 2026While agent evaluation has shifted toward long-horizon tasks, most benchmarks still emphasize local, step-level reasoning rather than the global constrained optimization (e.g., time and financial budgets) that demands genuine planning ability. Meanwhile, existing LLM planning benchmarks underrepresent the active information gathering and fine-grained local constraints typical of real-world settings. To address this, we introduce DeepPlanning, a challenging benchmark for practical long-horizon agent planning. It features multi-day travel planning and multi-product shopping tasks that require proactive information acquisition, local constrained reasoning, and global constrained optimization. Evaluations on DeepPlanning show that even frontier agentic LLMs struggle with these problems, highlighting the importance of reliable explicit reasoning patterns and parallel tool use for achieving better effectiveness-efficiency trade-offs. Error analysis further points to promising directions for improving agentic LLMs over long planning horizons. We open-source the code and data to support future research.
Leaning Time-Varying Instruments for Identifying Causal Effects in Time-Series Data
Nov 26, 2024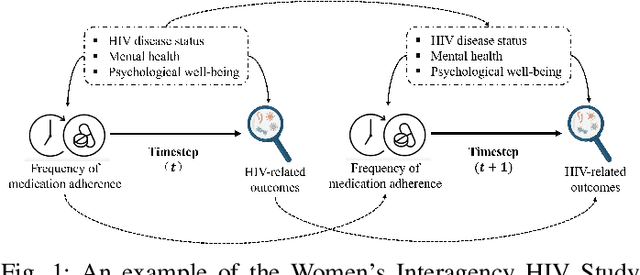
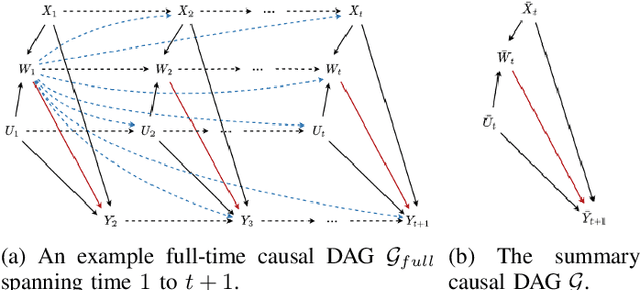
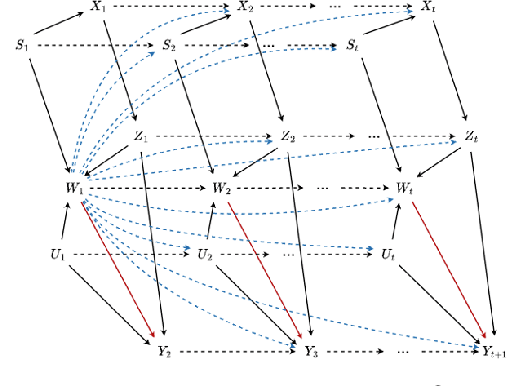
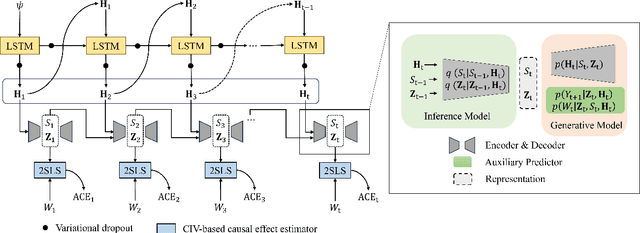
Querying causal effects from time-series data is important across various fields, including healthcare, economics, climate science, and epidemiology. However, this task becomes complex in the existence of time-varying latent confounders, which affect both treatment and outcome variables over time and can introduce bias in causal effect estimation. Traditional instrumental variable (IV) methods are limited in addressing such complexities due to the need for predefined IVs or strong assumptions that do not hold in dynamic settings. To tackle these issues, we develop a novel Time-varying Conditional Instrumental Variables (CIV) for Debiasing causal effect estimation, referred to as TDCIV. TDCIV leverages Long Short-Term Memory (LSTM) and Variational Autoencoder (VAE) models to disentangle and learn the representations of time-varying CIV and its conditioning set from proxy variables without prior knowledge. Under the assumptions of the Markov property and availability of proxy variables, we theoretically establish the validity of these learned representations for addressing the biases from time-varying latent confounders, thus enabling accurate causal effect estimation. Our proposed TDCIV is the first to effectively learn time-varying CIV and its associated conditioning set without relying on domain-specific knowledge.
SpecDec++: Boosting Speculative Decoding via Adaptive Candidate Lengths
May 30, 2024

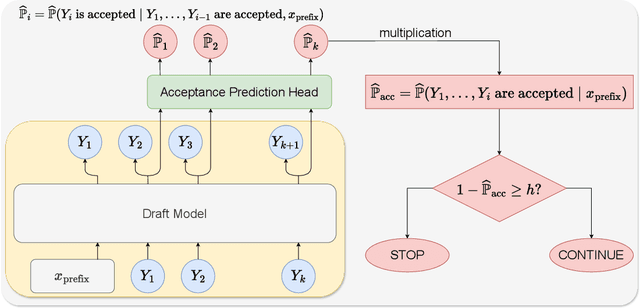
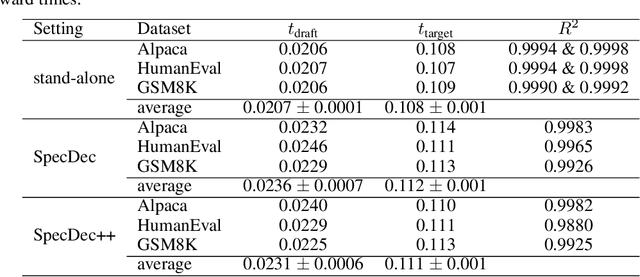
Speculative decoding reduces the inference latency of a target large language model via utilizing a smaller and faster draft model. Its performance depends on a hyperparameter K -- the candidate length, i.e., the number of candidate tokens for the target model to verify in each round. However, previous methods often use simple heuristics to choose K, which may result in sub-optimal performance. We study the choice of the candidate length K and formulate it as a Markov Decision Process. We theoretically show that the optimal policy of this Markov decision process takes the form of a threshold policy, i.e., the current speculation should stop and be verified when the probability of getting a rejection exceeds a threshold value. Motivated by this theory, we propose SpecDec++, an enhanced version of speculative decoding that adaptively determines the candidate length on the fly. We augment the draft model with a trained acceptance prediction head to predict the conditional acceptance probability of the candidate tokens. SpecDec++ will stop the current speculation when the predicted probability that at least one token gets rejected exceeds a threshold. We implement SpecDec++ and apply it to the llama-2-chat 7B & 70B model pair. Our adaptive method achieves a 2.04x speedup on the Alpaca dataset (an additional 7.2% improvement over the baseline speculative decoding). On the GSM8K and HumanEval datasets, our method achieves a 2.26x speedup (9.4% improvement) and 2.23x speedup (11.1% improvement), respectively.
Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration
Apr 05, 2024



The rise of multi-agent systems, especially the success of multi-agent reinforcement learning (MARL), is reshaping our future across diverse domains like autonomous vehicle networks. However, MARL still faces significant challenges, particularly in achieving zero-shot scalability, which allows trained MARL models to be directly applied to unseen tasks with varying numbers of agents. In addition, real-world multi-agent systems usually contain agents with different functions and strategies, while the existing scalable MARL methods only have limited heterogeneity. To address this, we propose a novel MARL framework named Scalable and Heterogeneous Proximal Policy Optimization (SHPPO), integrating heterogeneity into parameter-shared PPO-based MARL networks. we first leverage a latent network to adaptively learn strategy patterns for each agent. Second, we introduce a heterogeneous layer for decision-making, whose parameters are specifically generated by the learned latent variables. Our approach is scalable as all the parameters are shared except for the heterogeneous layer, and gains both inter-individual and temporal heterogeneity at the same time. We implement our approach based on the state-of-the-art backbone PPO-based algorithm as SHPPO, while our approach is agnostic to the backbone and can be seamlessly plugged into any parameter-shared MARL method. SHPPO exhibits superior performance over the baselines such as MAPPO and HAPPO in classic MARL environments like Starcraft Multi-Agent Challenge (SMAC) and Google Research Football (GRF), showcasing enhanced zero-shot scalability and offering insights into the learned latent representation's impact on team performance by visualization.
Embodied LLM Agents Learn to Cooperate in Organized Teams
Mar 19, 2024

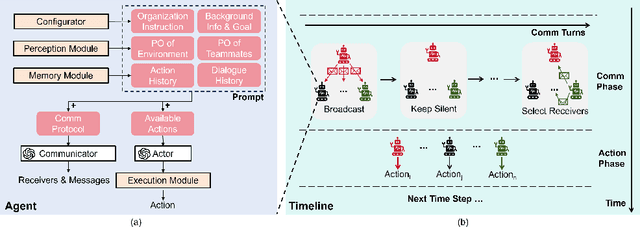

Large Language Models (LLMs) have emerged as integral tools for reasoning, planning, and decision-making, drawing upon their extensive world knowledge and proficiency in language-related tasks. LLMs thus hold tremendous potential for natural language interaction within multi-agent systems to foster cooperation. However, LLM agents tend to over-report and comply with any instruction, which may result in information redundancy and confusion in multi-agent cooperation. Inspired by human organizations, this paper introduces a framework that imposes prompt-based organization structures on LLM agents to mitigate these problems. Through a series of experiments with embodied LLM agents and human-agent collaboration, our results highlight the impact of designated leadership on team efficiency, shedding light on the leadership qualities displayed by LLM agents and their spontaneous cooperative behaviors. Further, we harness the potential of LLMs to propose enhanced organizational prompts, via a Criticize-Reflect process, resulting in novel organization structures that reduce communication costs and enhance team efficiency.
Scalable Communication for Multi-Agent Reinforcement Learning via Transformer-Based Email Mechanism
Jan 05, 2023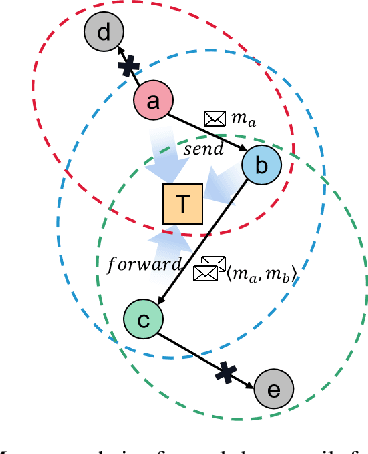
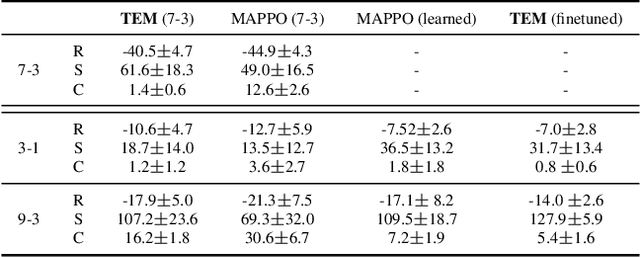
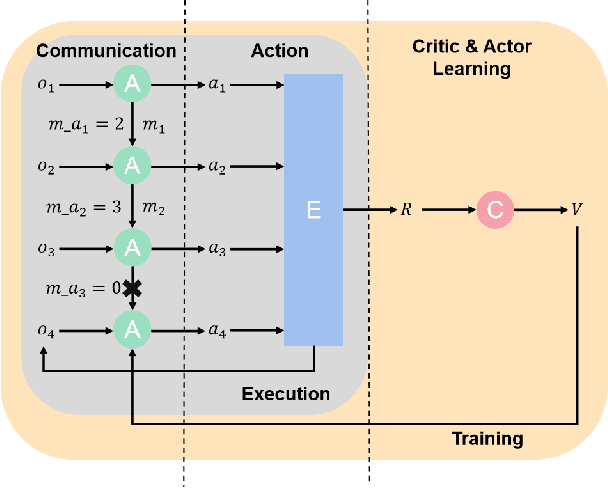
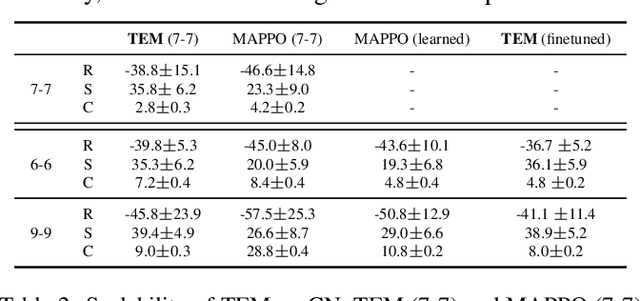
Communication can impressively improve cooperation in multi-agent reinforcement learning (MARL), especially for partially-observed tasks. However, existing works either broadcast the messages leading to information redundancy, or learn targeted communication by modeling all the other agents as targets, which is not scalable when the number of agents varies. In this work, to tackle the scalability problem of MARL communication for partially-observed tasks, we propose a novel framework Transformer-based Email Mechanism (TEM). The agents adopt local communication to send messages only to the ones that can be observed without modeling all the agents. Inspired by human cooperation with email forwarding, we design message chains to forward information to cooperate with the agents outside the observation range. We introduce Transformer to encode and decode the message chain to choose the next receiver selectively. Empirically, TEM outperforms the baselines on multiple cooperative MARL benchmarks. When the number of agents varies, TEM maintains superior performance without further training.
SSAN: Separable Self-Attention Network for Video Representation Learning
May 27, 2021
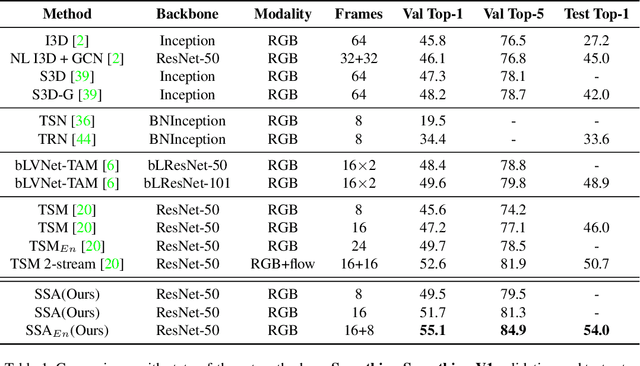
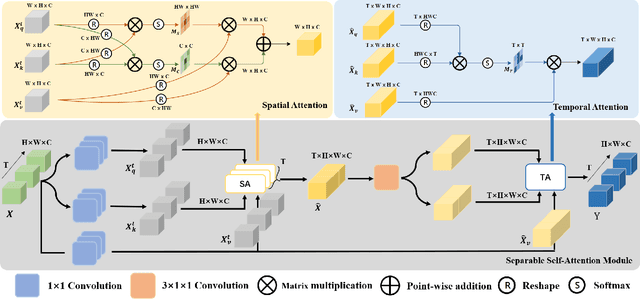
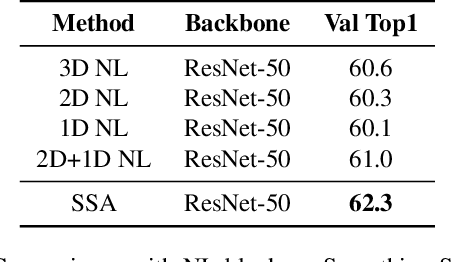
Self-attention has been successfully applied to video representation learning due to the effectiveness of modeling long range dependencies. Existing approaches build the dependencies merely by computing the pairwise correlations along spatial and temporal dimensions simultaneously. However, spatial correlations and temporal correlations represent different contextual information of scenes and temporal reasoning. Intuitively, learning spatial contextual information first will benefit temporal modeling. In this paper, we propose a separable self-attention (SSA) module, which models spatial and temporal correlations sequentially, so that spatial contexts can be efficiently used in temporal modeling. By adding SSA module into 2D CNN, we build a SSA network (SSAN) for video representation learning. On the task of video action recognition, our approach outperforms state-of-the-art methods on Something-Something and Kinetics-400 datasets. Our models often outperform counterparts with shallower network and fewer modalities. We further verify the semantic learning ability of our method in visual-language task of video retrieval, which showcases the homogeneity of video representations and text embeddings. On MSR-VTT and Youcook2 datasets, video representations learnt by SSA significantly improve the state-of-the-art performance.