 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language Foundation Model for Zero-shot Clinical Collaboration and Automated Concept Discovery in Dermatology
Feb 11, 2026Medical foundation models have shown promise in controlled benchmarks, yet widespread deployment remains hindered by reliance on task-specific fine-tuning. Here, we introduce DermFM-Zero, a dermatology vision-language foundation model trained via masked latent modelling and contrastive learning on over 4 million multimodal data points. We evaluated DermFM-Zero across 20 benchmarks spanning zero-shot diagnosis and multimodal retrieval, achieving state-of-the-art performance without task-specific adaptation. We further evaluated its zero-shot capabilities in three multinational reader studies involving over 1,100 clinicians. In primary care settings, AI assistance enabled general practitioners to nearly double their differential diagnostic accuracy across 98 skin conditions. In specialist settings, the model significantly outperformed board-certified dermatologists in multimodal skin cancer assessment. In collaborative workflows, AI assistance enabled non-experts to surpass unassisted experts while improving management appropriateness. Finally, we show that DermFM-Zero's latent representations are interpretable: sparse autoencoders unsupervisedly disentangle clinically meaningful concepts that outperform predefined-vocabulary approaches and enable targeted suppression of artifact-induced biases, enhancing robustness without retraining. These findings demonstrate that a foundation model can provide effective, safe, and transparent zero-shot clinical decision support.
Supporting Data-Frame Dynamics in AI-assisted Decision Making
Apr 22, 2025High stakes decision-making often requires a continuous interplay between evolving evidence and shifting hypotheses, a dynamic that is not well supported by current AI decision support systems. In this paper, we introduce a mixed-initiative framework for AI assisted decision making that is grounded in the data-frame theory of sensemaking and the evaluative AI paradigm. Our approach enables both humans and AI to collaboratively construct, validate, and adapt hypotheses. We demonstrate our framework with an AI-assisted skin cancer diagnosis prototype that leverages a concept bottleneck model to facilitate interpretable interactions and dynamic updates to diagnostic hypotheses.
* Presented at the 2025 ACM Workshop on Human-AI Interaction for Augmented Reasoning, Report Number: CHI25-WS-AUGMENTED-REASONING
A General-Purpose Multimodal Foundation Model for Dermatology
Oct 19, 2024



Diagnosing and treating skin diseases require advanced visual skills across multiple domains and the ability to synthesize information from various imaging modalities. Current deep learning models, while effective at specific tasks such as diagnosing skin cancer from dermoscopic images, fall short in addressing the complex, multimodal demands of clinical practice. Here, we introduce PanDerm, a multimodal dermatology foundation model pretrained through self-supervised learning on a dataset of over 2 million real-world images of skin diseases, sourced from 11 clinical institutions across 4 imaging modalities. We evaluated PanDerm on 28 diverse datasets covering a range of clinical tasks, including skin cancer screening, phenotype assessment and risk stratification, diagnosis of neoplastic and inflammatory skin diseases, skin lesion segmentation, change monitoring, and metastasis prediction and prognosis. PanDerm achieved state-of-the-art performance across all evaluated tasks, often outperforming existing models even when using only 5-10% of labeled data. PanDerm's clinical utility was demonstrated through reader studies in real-world clinical settings across multiple imaging modalities. It outperformed clinicians by 10.2% in early-stage melanoma detection accuracy and enhanced clinicians' multiclass skin cancer diagnostic accuracy by 11% in a collaborative human-AI setting. Additionally, PanDerm demonstrated robust performance across diverse demographic factors, including different body locations, age groups, genders, and skin tones. The strong results in benchmark evaluations and real-world clinical scenarios suggest that PanDerm could enhance the management of skin diseases and serve as a model for developing multimodal foundation models in other medical specialties, potentially accelerating the integration of AI support in healthcare.
Prompt-driven Latent Domain Generalization for Medical Image Classification
Jan 05, 2024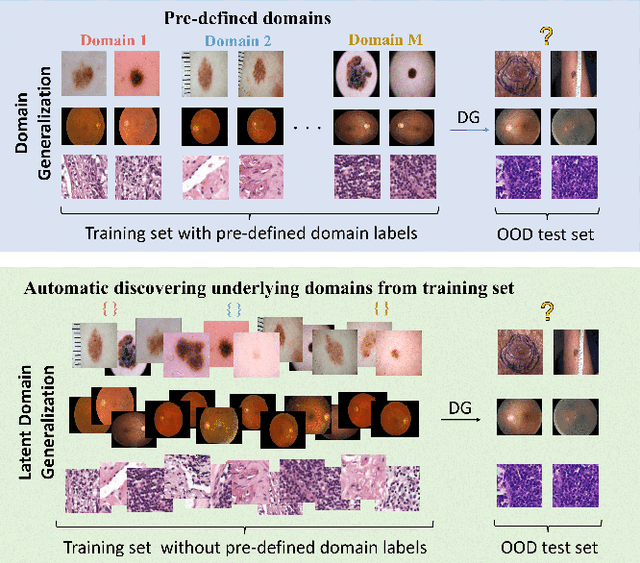
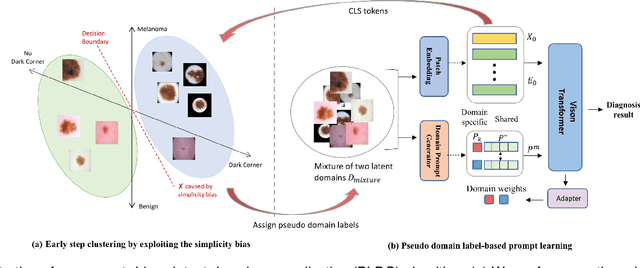
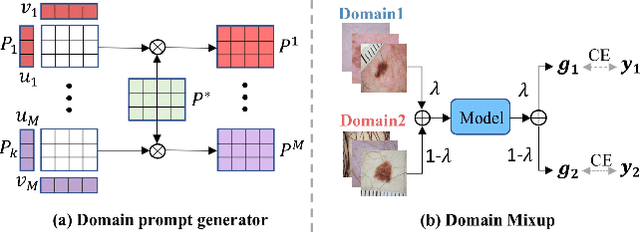

Deep learning models for medical image analysis easily suffer from distribution shifts caused by dataset artifacts bias, camera variations, differences in the imaging station, etc., leading to unreliable diagnoses in real-world clinical settings. Domain generalization (DG) methods, which aim to train models on multiple domains to perform well on unseen domains, offer a promising direction to solve the problem. However, existing DG methods assume domain labels of each image are available and accurate, which is typically feasible for only a limited number of medical datasets. To address these challenges, we propose a novel DG framework for medical image classification without relying on domain labels, called Prompt-driven Latent Domain Generalization (PLDG). PLDG consists of unsupervised domain discovery and prompt learning. This framework first discovers pseudo domain labels by clustering the bias-associated style features, then leverages collaborative domain prompts to guide a Vision Transformer to learn knowledge from discovered diverse domains. To facilitate cross-domain knowledge learning between different prompts, we introduce a domain prompt generator that enables knowledge sharing between domain prompts and a shared prompt. A domain mixup strategy is additionally employed for more flexible decision margins and mitigates the risk of incorrect domain assignments. Extensive experiments on three medical image classification tasks and one debiasing task demonstrate that our method can achieve comparable or even superior performance than conventional DG algorithms without relying on domain labels. Our code will be publicly available upon the paper is accepted.
Application of Machine Learning in Melanoma Detection and the Identification of 'Ugly Duckling' and Suspicious Naevi: A Review
Sep 05, 2023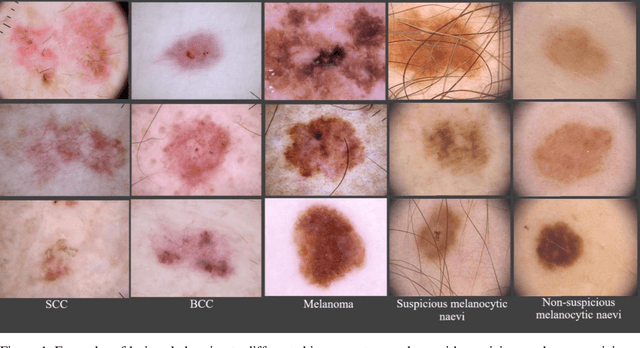
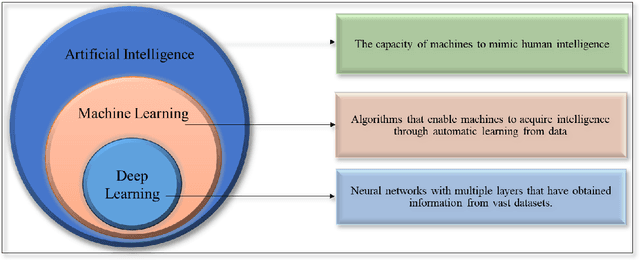

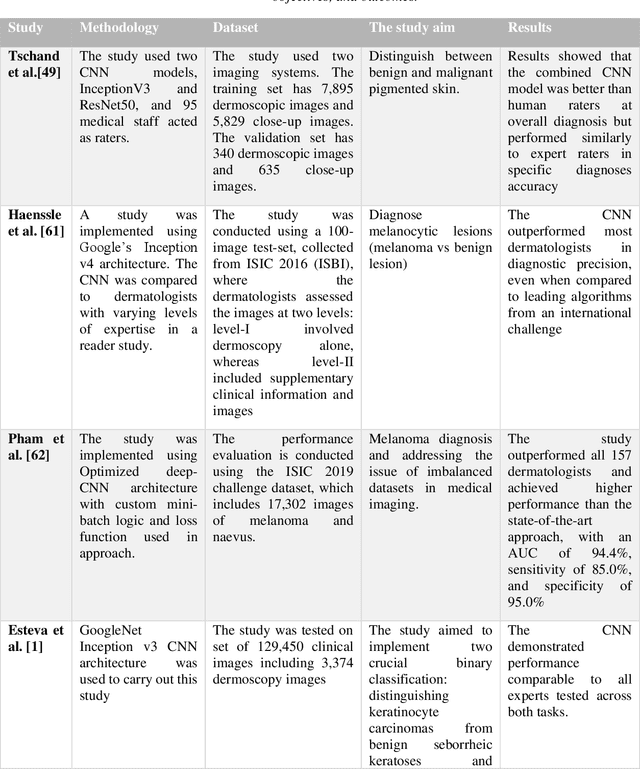
Skin lesions known as naevi exhibit diverse characteristics such as size, shape, and colouration. The concept of an "Ugly Duckling Naevus" comes into play when monitoring for melanoma, referring to a lesion with distinctive features that sets it apart from other lesions in the vicinity. As lesions within the same individual typically share similarities and follow a predictable pattern, an ugly duckling naevus stands out as unusual and may indicate the presence of a cancerous melanoma. Computer-aided diagnosis (CAD) has become a significant player in the research and development field, as it combines machine learning techniques with a variety of patient analysis methods. Its aim is to increase accuracy and simplify decision-making, all while responding to the shortage of specialized professionals. These automated systems are especially important in skin cancer diagnosis where specialist availability is limited. As a result, their use could lead to life-saving benefits and cost reductions within healthcare. Given the drastic change in survival when comparing early stage to late-stage melanoma, early detection is vital for effective treatment and patient outcomes. Machine learning (ML) and deep learning (DL) techniques have gained popularity in skin cancer classification, effectively addressing challenges, and providing results equivalent to that of specialists. This article extensively covers modern Machine Learning and Deep Learning algorithms for detecting melanoma and suspicious naevi. It begins with general information on skin cancer and different types of naevi, then introduces AI, ML, DL, and CAD. The article then discusses the successful applications of various ML techniques like convolutional neural networks (CNN) for melanoma detection compared to dermatologists' performance. Lastly, it examines ML methods for UD naevus detection and identifying suspicious naevi.
EPVT: Environment-aware Prompt Vision Transformer for Domain Generalization in Skin Lesion Recognition
Apr 09, 2023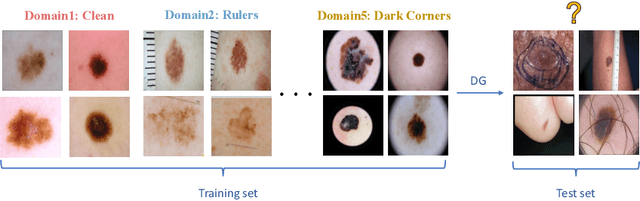
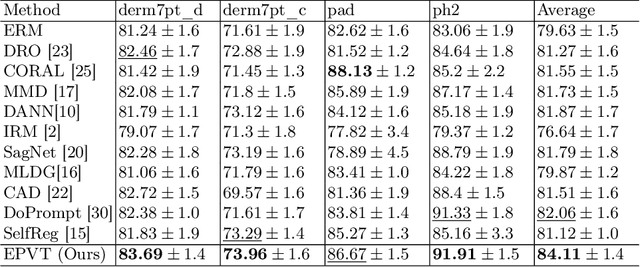
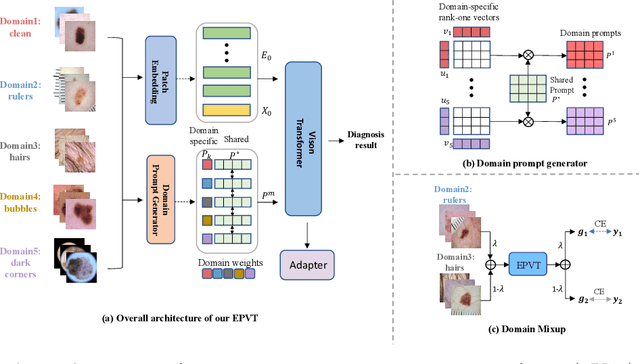
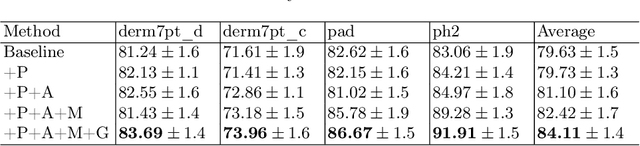
Skin lesion recognition using deep learning has made remarkable progress, and there is an increasing need for deploying these systems in real-world scenarios. However, recent research has revealed that deep neural networks for skin lesion recognition may overly depend on disease-irrelevant image artifacts (i.e. dark corners, dense hairs), leading to poor generalization in unseen environments. To address this issue, we propose a novel domain generalization method called EPVT, which involves embedding prompts into the vision transformer to collaboratively learn knowledge from diverse domains. Concretely, EPVT leverages a set of domain prompts, each of which plays as a domain expert, to capture domain-specific knowledge; and a shared prompt for general knowledge over the entire dataset. To facilitate knowledge sharing and the interaction of different prompts, we introduce a domain prompt generator that enables low-rank multiplicative updates between domain prompts and the shared prompt. A domain mixup strategy is additionally devised to reduce the co-occurring artifacts in each domain, which allows for more flexible decision margins and mitigates the issue of incorrectly assigned domain labels. Experiments on four out-of-distribution datasets and six different biased ISIC datasets demonstrate the superior generalization ability of EPVT in skin lesion recognition across various environments. Our code and dataset will be released at https://github.com/SiyuanYan1/EPVT.
Towards Trustable Skin Cancer Diagnosis via Rewriting Model's Decision
Mar 02, 2023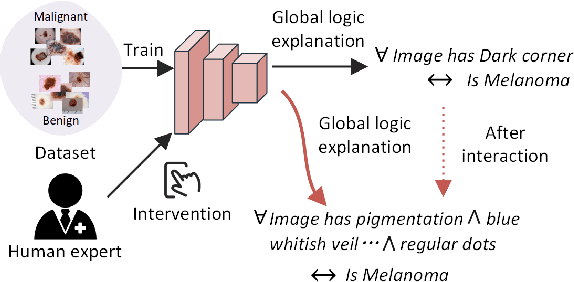
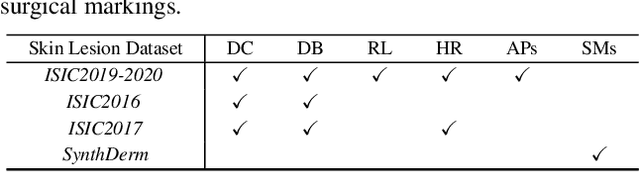
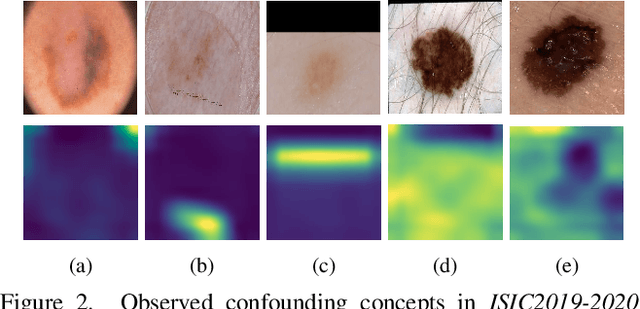
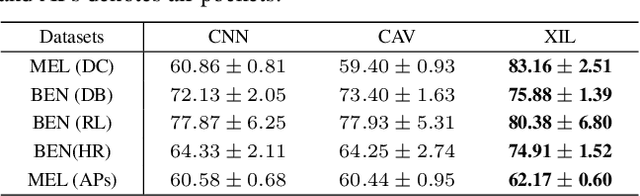
Deep neural networks have demonstrated promising performance on image recognition tasks. However, they may heavily rely on confounding factors, using irrelevant artifacts or bias within the dataset as the cue to improve performance. When a model performs decision-making based on these spurious correlations, it can become untrustable and lead to catastrophic outcomes when deployed in the real-world scene. In this paper, we explore and try to solve this problem in the context of skin cancer diagnosis. We introduce a human-in-the-loop framework in the model training process such that users can observe and correct the model's decision logic when confounding behaviors happen. Specifically, our method can automatically discover confounding factors by analyzing the co-occurrence behavior of the samples. It is capable of learning confounding concepts using easily obtained concept exemplars. By mapping the black-box model's feature representation onto an explainable concept space, human users can interpret the concept and intervene via first order-logic instruction. We systematically evaluate our method on our newly crafted, well-controlled skin lesion dataset and several public skin lesion datasets. Experiments show that our method can effectively detect and remove confounding factors from datasets without any prior knowledge about the category distribution and does not require fully annotated concept labels. We also show that our method enables the model to focus on clinical-related concepts, improving the model's performance and trustworthiness during model inference.