 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyondFacial: Identity-Preserving Personalized Generation Beyond Facial Close-ups
Nov 15, 2025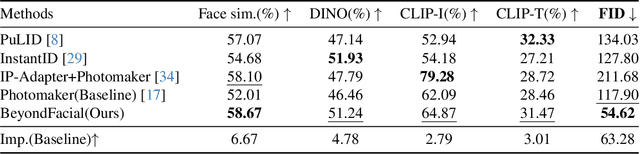
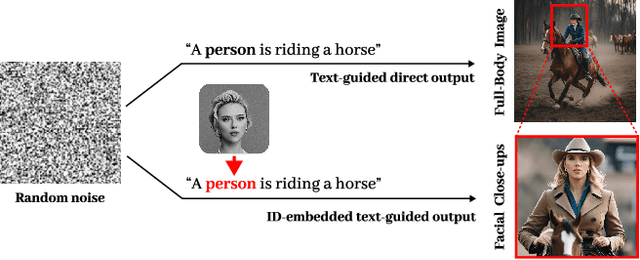
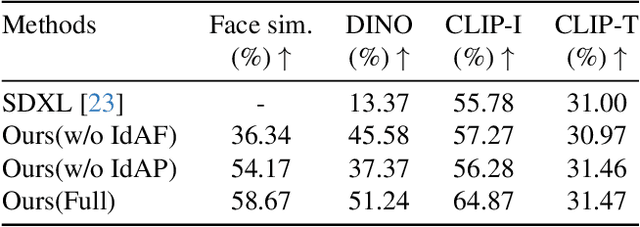
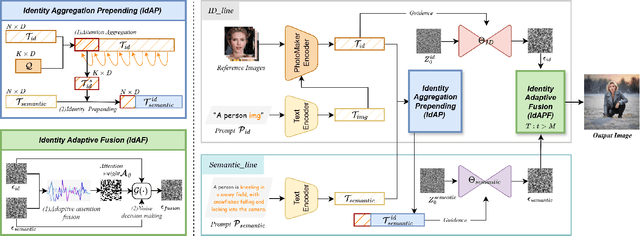
Identity-Preserving Personalized Generation (IPPG) has advanced film production and artistic creation, yet existing approaches overemphasize facial regions, resulting in outputs dominated by facial close-ups.These methods suffer from weak visual narrativity and poor semantic consistency under complex text prompts, with the core limitation rooted in identity (ID) feature embeddings undermining the semantic expressiveness of generative models. To address these issues, this paper presents an IPPG method that breaks the constraint of facial close-ups, achieving synergistic optimization of identity fidelity and scene semantic creation. Specifically, we design a Dual-Line Inference (DLI) pipeline with identity-semantic separation, resolving the representation conflict between ID and semantics inherent in traditional single-path architectures. Further, we propose an Identity Adaptive Fusion (IdAF) strategy that defers ID-semantic fusion to the noise prediction stage, integrating adaptive attention fusion and noise decision masking to avoid ID embedding interference on semantics without manual masking. Finally, an Identity Aggregation Prepending (IdAP) module is introduced to aggregate ID information and replace random initializations, further enhancing identity preservation. Experimental results validate that our method achieves stable and effective performance in IPPG tasks beyond facial close-ups, enabling efficient generation without manual masking or fine-tuning. As a plug-and-play component, it can be rapidly deployed in existing IPPG frameworks, addressing the over-reliance on facial close-ups, facilitating film-level character-scene creation, and providing richer personalized generation capabilities for related domains.
Retrieval Feedback Memory Enhancement Large Model Retrieval Generation Method
Aug 25, 2025Large Language Models (LLMs) have shown remarkable capabilities across diverse tasks, yet they face inherent limitations such as constrained parametric knowledge and high retraining costs. Retrieval-Augmented Generation (RAG) augments the generation process by retrieving externally stored knowledge absent from the models internal parameters. However, RAG methods face challenges such as information loss and redundant retrievals during multi-round queries, accompanying the difficulties in precisely characterizing knowledge gaps for complex tasks. To address these problems, we propose Retrieval Feedback and Memory Retrieval Augmented Generation(RFM-RAG), which transforms the stateless retrieval of previous methods into stateful continuous knowledge management by constructing a dynamic evidence pool. Specifically, our method generates refined queries describing the models knowledge gaps using relational triples from questions and evidence from the dynamic evidence pool; Retrieves critical external knowledge to iteratively update this evidence pool; Employs a R-Feedback Model to evaluate evidence completeness until convergence. Compared to traditional RAG methods, our approach enables persistent storage of retrieved passages and effectively distills key information from passages to construct clearly new queries. Experiments on three public QA benchmarks demonstrate that RFM-RAG outperforms previous methods and improves overall system accuracy.
CEIDM: A Controlled Entity and Interaction Diffusion Model for Enhanced Text-to-Image Generation
Aug 25, 2025In Text-to-Image (T2I) generation, the complexity of entities and their intricate interactions pose a significant challenge for T2I method based on diffusion model: how to effectively control entity and their interactions to produce high-quality images. To address this, we propose CEIDM, a image generation method based on diffusion model with dual controls for entity and interaction. First, we propose an entity interactive relationships mining approach based on Large Language Models (LLMs), extracting reasonable and rich implicit interactive relationships through chain of thought to guide diffusion models to generate high-quality images that are closer to realistic logic and have more reasonable interactive relationships. Furthermore, We propose an interactive action clustering and offset method to cluster and offset the interactive action features contained in each text prompts. By constructing global and local bidirectional offsets, we enhance semantic understanding and detail supplementation of original actions, making the model's understanding of the concept of interactive "actions" more accurate and generating images with more accurate interactive actions. Finally, we design an entity control network which generates masks with entity semantic guidance, then leveraging multi-scale convolutional network to enhance entity feature and dynamic network to fuse feature. It effectively controls entities and significantly improves image quality. Experiments show that the proposed CEIDM method is better than the most representative existing methods in both entity control and their interaction control.
Separation and Collaboration: Two-Level Routing Grouped Mixture-of-Experts for Multi-Domain Continual Learning
Aug 11, 2025Multi-Domain Continual Learning (MDCL) acquires knowledge from sequential tasks with shifting class sets and distribution. Despite the Parameter-Efficient Fine-Tuning (PEFT) methods can adapt for this dual heterogeneity, they still suffer from catastrophic forgetting and forward forgetting. To address these challenges, we propose a Two-Level Routing Grouped Mixture-of-Experts (TRGE) method. Firstly, TRGE dynamically expands the pre-trained CLIP model, assigning specific expert group for each task to mitigate catastrophic forgetting. With the number of experts continually grows in this process, TRGE maintains the static experts count within the group and introduces the intra-group router to alleviate routing overfitting caused by the increasing routing complexity. Meanwhile, we design an inter-group routing policy based on task identifiers and task prototype distance, which dynamically selects relevant expert groups and combines their outputs to enhance inter-task collaboration. Secondly, to get the correct task identifiers, we leverage Multimodal Large Language Models (MLLMs) which own powerful multimodal comprehension capabilities to generate semantic task descriptions and recognize the correct task identifier. Finally, to mitigate forward forgetting, we dynamically fuse outputs for unseen samples from the frozen CLIP model and TRGE adapter based on training progress, leveraging both pre-trained and learned knowledge. Through extensive experiments across various settings, our method outperforms other advanced methods with fewer trainable parameters.
D3HRL: A Distributed Hierarchical Reinforcement Learning Approach Based on Causal Discovery and Spurious Correlation Detection
May 04, 2025



Current Hierarchical Reinforcement Learning (HRL) algorithms excel in long-horizon sequential decision-making tasks but still face two challenges: delay effects and spurious correlations. To address them, we propose a causal HRL approach called D3HRL. First, D3HRL models delayed effects as causal relationships across different time spans and employs distributed causal discovery to learn these relationships. Second, it employs conditional independence testing to eliminate spurious correlations. Finally, D3HRL constructs and trains hierarchical policies based on the identified true causal relationships. These three steps are iteratively executed, gradually exploring the complete causal chain of the task. Experiments conducted in 2D-MineCraft and MiniGrid show that D3HRL demonstrates superior sensitivity to delay effects and accurately identifies causal relationships, leading to reliable decision-making in complex environments.
Pairwise Similarity Regularization for Semi-supervised Graph Medical Image Segmentation
Mar 17, 2025



With fully leveraging the value of unlabeled data, semi-supervised medical image segmentation algorithms significantly reduces the limitation of limited labeled data, achieving a significant improvement in accuracy. However, the distributional shift between labeled and unlabeled data weakens the utilization of information from the labeled data. To alleviate the problem, we propose a graph network feature alignment method based on pairwise similarity regularization (PaSR) for semi-supervised medical image segmentation. PaSR aligns the graph structure of images in different domains by maintaining consistency in the pairwise structural similarity of feature graphs between the target domain and the source domain, reducing distribution shift issues in medical images. Meanwhile, further improving the accuracy of pseudo-labels in the teacher network by aligning graph clustering information to enhance the semi-supervised efficiency of the model. The experimental part was verified on three medical image segmentation benchmark datasets, with results showing improvements over advanced methods in various metrics. On the ACDC dataset, it achieved an average improvement of more than 10.66%.
Task2Morph: Differentiable Task-inspired Framework for Contact-Aware Robot Design
Mar 28, 2024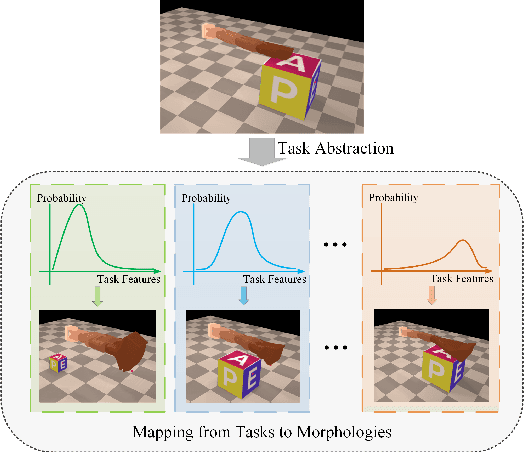
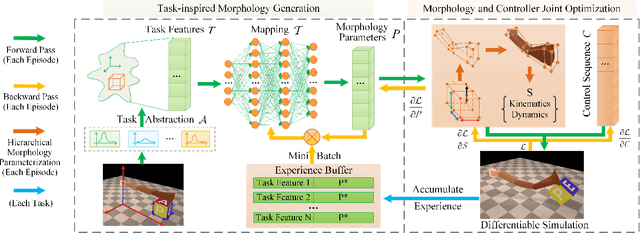
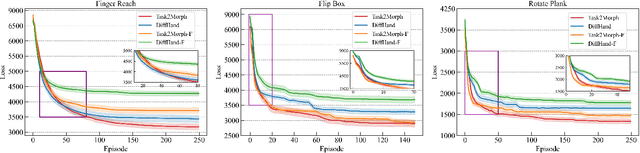

Optimizing the morphologies and the controllers that adapt to various tasks is a critical issue in the field of robot design, aka. embodied intelligence. Previous works typically model it as a joint optimization problem and use search-based methods to find the optimal solution in the morphology space. However, they ignore the implicit knowledge of task-to-morphology mapping which can directly inspire robot design. For example, flipping heavier boxes tends to require more muscular robot arms. This paper proposes a novel and general differentiable task-inspired framework for contact-aware robot design called Task2Morph. We abstract task features highly related to task performance and use them to build a task-to-morphology mapping. Further, we embed the mapping into a differentiable robot design process, where the gradient information is leveraged for both the mapping learning and the whole optimization. The experiments are conducted on three scenarios, and the results validate that Task2Morph outperforms DiffHand, which lacks a task-inspired morphology module, in terms of efficiency and effectiveness.
* 9 pages, 10 figures, published to IROS
EAFP-Med: An Efficient Adaptive Feature Processing Module Based on Prompts for Medical Image Detection
Nov 27, 2023



In the face of rapid advances in medical imaging, cross-domain adaptive medical image detection is challenging due to the differences in lesion representations across various medical imaging technologies. To address this issue, we draw inspiration from large language models to propose EAFP-Med, an efficient adaptive feature processing module based on prompts for medical image detection. EAFP-Med can efficiently extract lesion features of different scales from a diverse range of medical images based on prompts while being flexible and not limited by specific imaging techniques. Furthermore, it serves as a feature preprocessing module that can be connected to any model front-end to enhance the lesion features in input images. Moreover, we propose a novel adaptive disease detection model named EAFP-Med ST, which utilizes the Swin Transformer V2 - Tiny (SwinV2-T) as its backbone and connects it to EAFP-Med. We have compared our method to nine state-of-the-art methods. Experimental results demonstrate that EAFP-Med ST achieves the best performance on all three datasets (chest X-ray images, cranial magnetic resonance imaging images, and skin images). EAFP-Med can efficiently extract lesion features from various medical images based on prompts, enhancing the model's performance. This holds significant potential for improving medical image analysis and diagnosis.
NeRF-Pose: A First-Reconstruct-Then-Regress Approach for Weakly-supervised 6D Object Pose Estimation
Mar 09, 2022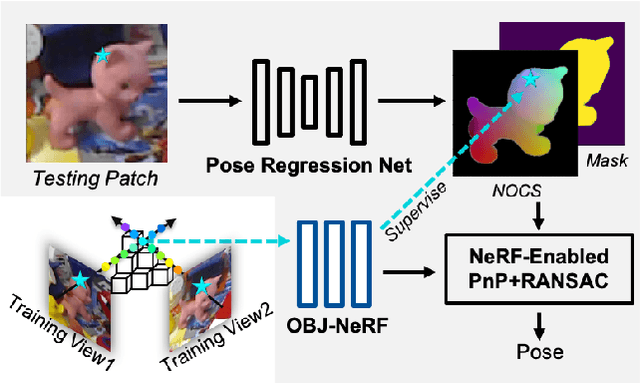
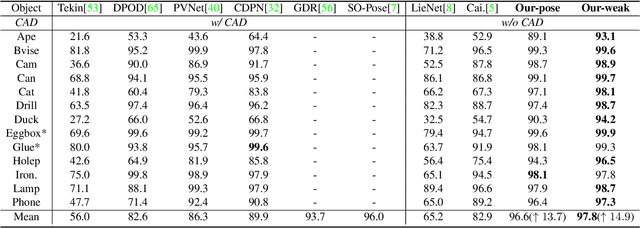
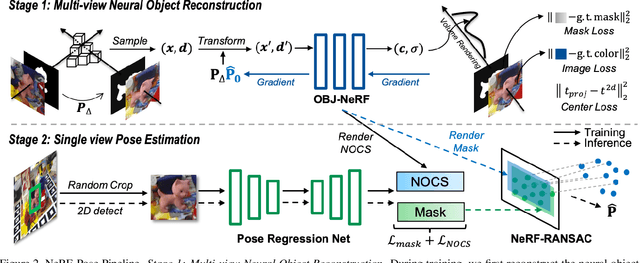
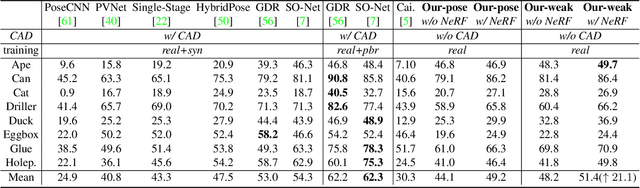
Pose estimation of 3D objects in monocular images is a fundamental and long-standing problem in computer vision. Existing deep learning approaches for 6D pose estimation typically rely on the assumption of availability of 3D object models and 6D pose annotations. However, precise annotation of 6D poses in real data is intricate, time-consuming and not scalable, while synthetic data scales well but lacks realism. To avoid these problems, we present a weakly-supervised reconstruction-based pipeline, named NeRF-Pose, which needs only 2D object segmentation and known relative camera poses during training. Following the first-reconstruct-then-regress idea, we first reconstruct the objects from multiple views in the form of an implicit neural representation. Then, we train a pose regression network to predict pixel-wise 2D-3D correspondences between images and the reconstructed model. At inference, the approach only needs a single image as input. A NeRF-enabled PnP+RANSAC algorithm is used to estimate stable and accurate pose from the predicted correspondences. Experiments on LineMod and LineMod-Occlusion show that the proposed method has state-of-the-art accuracy in comparison to the best 6D pose estimation methods in spite of being trained only with weak labels. Besides, we extend the Homebrewed DB dataset with more real training images to support the weakly supervised task and achieve compelling results on this dataset. The extended dataset and code will be released soon.