 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthFormer: Multimodal Positional Encodings and Cross-Input Attention for Transformer-Based Segmentation Networks
Paper and Code
Nov 08, 2022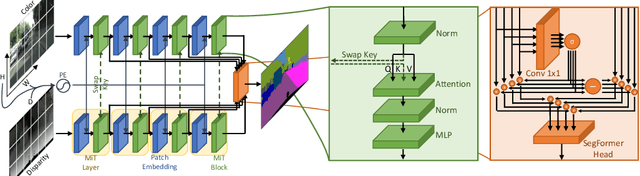


Most approaches for semantic segmentation use only information from color cameras to parse the scenes, yet recent advancements show that using depth data allows to further improve performances. In this work, we focus on transformer-based deep learning architectures, that have achieved state-of-the-art performances on the segmentation task, and we propose to employ depth information by embedding it in the positional encoding. Effectively, we extend the network to multimodal data without adding any parameters and in a natural way that makes use of the strength of transformers' self-attention modules. We also investigate the idea of performing cross-modality operations inside the attention module, swapping the key inputs between the depth and color branches. Our approach consistently improves performances on the Cityscapes benchmark.