 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiERO-StepG @ Ego4D Step Grounding Challenge: hierarchical activity understanding enables zero-shot step grounding
May 29, 2026Procedural activities follow well-defined structures: whether we consider a cooking recipe or a mechanic repairing a car, these activities naturally decompose in a hierarchy of steps and sub-steps. Traditional approaches for step grounding require extensive annotations and scale poorly. Instead, we argue that such hierarchical structure can emerge naturally from uncurated videos of human activities through recurring patterns of co-occurring actions and activities. Our approach builds on HiERO, a weakly-supervised representation learning approach that maps close in the feature space actions that are functionally related to each other, leveraging only fine-grained action-level narrations. In this feature space, procedure steps can be detected by a simple clustering, with no additional task-specific fine-tuning. For the Ego4D Step Grounding challenge, we augment this approach by ensuring fine and coarse level agreement in step assignments, enforcing strict temporal monotonicity of the grounded steps and post-processing the detected steps to reduce the impact of noisy predictions. We call this approach HiERO-StepG and it achieves 56.27 % on the R@1 (IoU = 0.3) metric on the global leaderboard at submission time, ranking second while being completely zero-shot and not requiring procedure-specific annotations. Project page: https://github.com/andreazenotto/HiERO-StepG.
Learning reusable concepts across different egocentric video understanding tasks
May 30, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. In this paper, we introduce Hier-EgoPack, a unified framework able to create a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed.
HiERO: understanding the hierarchy of human behavior enhances reasoning on egocentric videos
May 19, 2025Human activities are particularly complex and variable, and this makes challenging for deep learning models to reason about them. However, we note that such variability does have an underlying structure, composed of a hierarchy of patterns of related actions. We argue that such structure can emerge naturally from unscripted videos of human activities, and can be leveraged to better reason about their content. We present HiERO, a weakly-supervised method to enrich video segments features with the corresponding hierarchical activity threads. By aligning video clips with their narrated descriptions, HiERO infers contextual, semantic and temporal reasoning with an hierarchical architecture. We prove the potential of our enriched features with multiple video-text alignment benchmarks (EgoMCQ, EgoNLQ) with minimal additional training, and in zero-shot for procedure learning tasks (EgoProceL and Ego4D Goal-Step). Notably, HiERO achieves state-of-the-art performance in all the benchmarks, and for procedure learning tasks it outperforms fully-supervised methods by a large margin (+12.5% F1 on EgoProceL) in zero shot. Our results prove the relevance of using knowledge of the hierarchy of human activities for multiple reasoning tasks in egocentric vision.
FORESCENE: FOREcasting human activity via latent SCENE graphs diffusion
Mar 08, 2025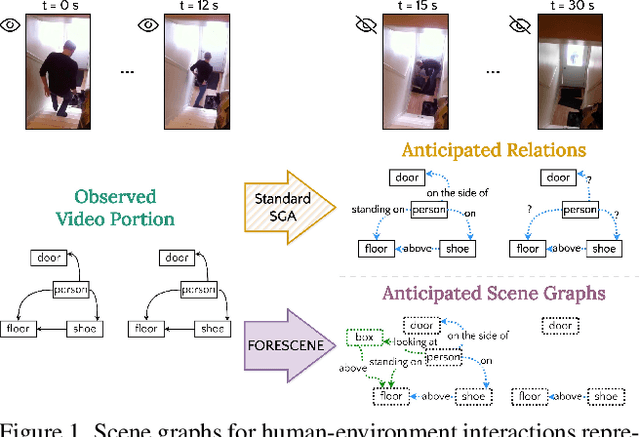
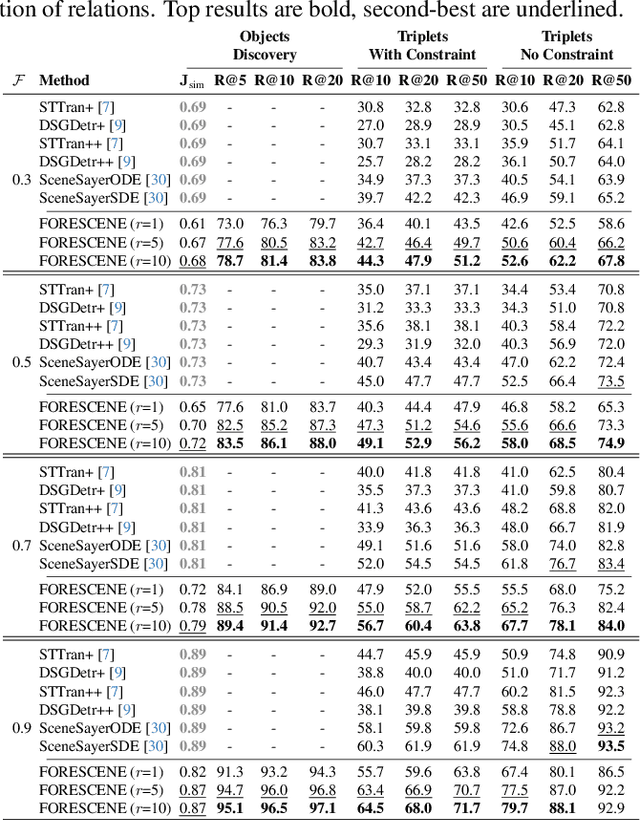
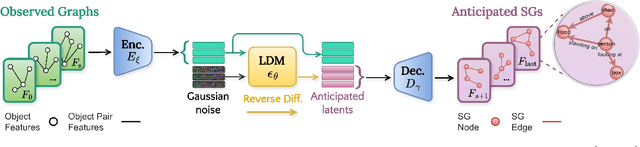
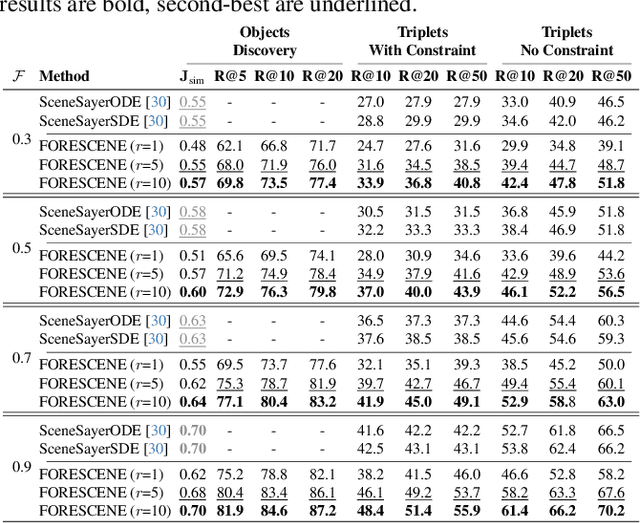
Forecasting human-environment interactions in daily activities is challenging due to the high variability of human behavior. While predicting directly from videos is possible, it is limited by confounding factors like irrelevant objects or background noise that do not contribute to the interaction. A promising alternative is using Scene Graphs (SGs) to track only the relevant elements. However, current methods for forecasting future SGs face significant challenges and often rely on unrealistic assumptions, such as fixed objects over time, limiting their applicability to long-term activities where interacted objects may appear or disappear. In this paper, we introduce FORESCENE, a novel framework for Scene Graph Anticipation (SGA) that predicts both object and relationship evolution over time. FORESCENE encodes observed video segments into a latent representation using a tailored Graph Auto-Encoder and forecasts future SGs using a Latent Diffusion Model (LDM). Our approach enables continuous prediction of interaction dynamics without making assumptions on the graph's content or structure. We evaluate FORESCENE on the Action Genome dataset, where it outperforms existing SGA methods while solving a significantly more complex task.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025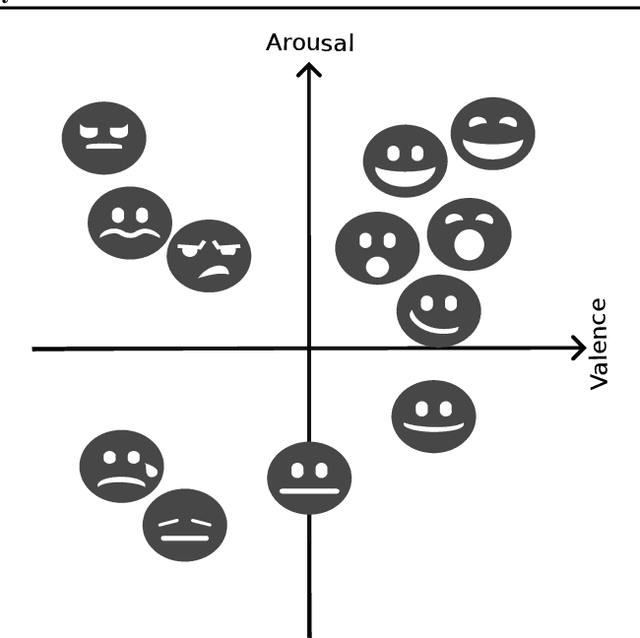


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task Perspectives
Feb 04, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such a holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. A significant step in this direction is EgoPack, a unified framework for understanding human activities across diverse tasks with minimal overhead. EgoPack promotes information sharing and collaboration among downstream tasks, essential for efficiently learning new skills. In this paper, we introduce Hier-EgoPack, which advances EgoPack by enabling reasoning also across diverse temporal granularities, which expands its applicability to a broader range of downstream tasks. To achieve this, we propose a novel hierarchical architecture for temporal reasoning equipped with a GNN layer specifically designed to tackle the challenges of multi-granularity reasoning effectively. We evaluate our approach on multiple Ego4d benchmarks involving both clip-level and frame-level reasoning, demonstrating how our hierarchical unified architecture effectively solves these diverse tasks simultaneously.
A Backpack Full of Skills: Egocentric Video Understanding with Diverse Task Perspectives
Mar 05, 2024



Human comprehension of a video stream is naturally broad: in a few instants, we are able to understand what is happening, the relevance and relationship of objects, and forecast what will follow in the near future, everything all at once. We believe that - to effectively transfer such an holistic perception to intelligent machines - an important role is played by learning to correlate concepts and to abstract knowledge coming from different tasks, to synergistically exploit them when learning novel skills. To accomplish this, we seek for a unified approach to video understanding which combines shared temporal modelling of human actions with minimal overhead, to support multiple downstream tasks and enable cooperation when learning novel skills. We then propose EgoPack, a solution that creates a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed. We demonstrate the effectiveness and efficiency of our approach on four Ego4D benchmarks, outperforming current state-of-the-art methods.
PEM: Prototype-based Efficient MaskFormer for Image Segmentation
Mar 01, 2024



Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.
Entropic Score metric: Decoupling Topology and Size in Training-free NAS
Oct 06, 2023



Neural Networks design is a complex and often daunting task, particularly for resource-constrained scenarios typical of mobile-sized models. Neural Architecture Search is a promising approach to automate this process, but existing competitive methods require large training time and computational resources to generate accurate models. To overcome these limits, this paper contributes with: i) a novel training-free metric, named Entropic Score, to estimate model expressivity through the aggregated element-wise entropy of its activations; ii) a cyclic search algorithm to separately yet synergistically search model size and topology. Entropic Score shows remarkable ability in searching for the topology of the network, and a proper combination with LogSynflow, to search for model size, yields superior capability to completely design high-performance Hybrid Transformers for edge applications in less than 1 GPU hour, resulting in the fastest and most accurate NAS method for ImageNet classification.
Graph learning in robotics: a survey
Oct 06, 2023



Deep neural networks for graphs have emerged as a powerful tool for learning on complex non-euclidean data, which is becoming increasingly common for a variety of different applications. Yet, although their potential has been widely recognised in the machine learning community, graph learning is largely unexplored for downstream tasks such as robotics applications. To fully unlock their potential, hence, we propose a review of graph neural architectures from a robotics perspective. The paper covers the fundamentals of graph-based models, including their architecture, training procedures, and applications. It also discusses recent advancements and challenges that arise in applied settings, related for example to the integration of perception, decision-making, and control. Finally, the paper provides an extensive review of various robotic applications that benefit from learning on graph structures, such as bodies and contacts modelling, robotic manipulation, action recognition, fleet motion planning, and many more. This survey aims to provide readers with a thorough understanding of the capabilities and limitations of graph neural architectures in robotics, and to highlight potential avenues for future research.