 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-HOI: A Physics-Aware Human and Object Interaction Dataset
Aug 08, 2025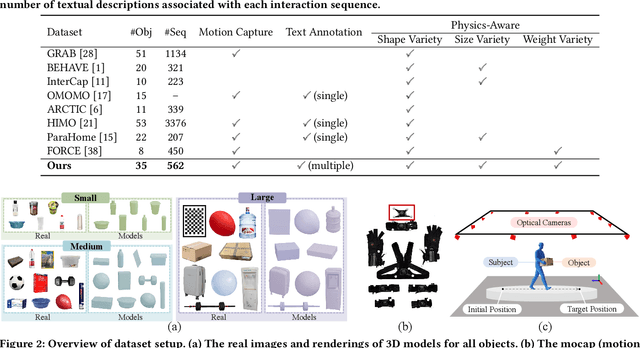
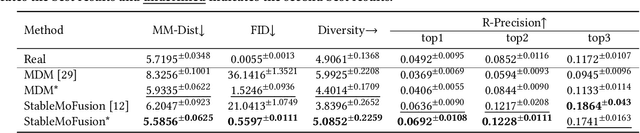
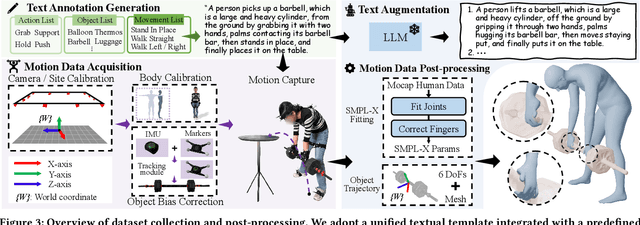
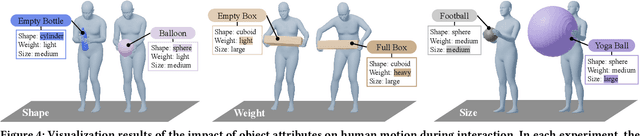
The Human-Object Interaction (HOI) task explores the dynamic interactions between humans and objects in physical environments, providing essential biomechanical and cognitive-behavioral foundations for fields such as robotics, virtual reality, and human-computer interaction. However, existing HOI data sets focus on details of affordance, often neglecting the influence of physical properties of objects on human long-term motion. To bridge this gap, we introduce the PA-HOI Motion Capture dataset, which highlights the impact of objects' physical attributes on human motion dynamics, including human posture, moving velocity, and other motion characteristics. The dataset comprises 562 motion sequences of human-object interactions, with each sequence performed by subjects of different genders interacting with 35 3D objects that vary in size, shape, and weight. This dataset stands out by significantly extending the scope of existing ones for understanding how the physical attributes of different objects influence human posture, speed, motion scale, and interacting strategies. We further demonstrate the applicability of the PA-HOI dataset by integrating it with existing motion generation methods, validating its capacity to transfer realistic physical awareness.
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Sep 04, 2024
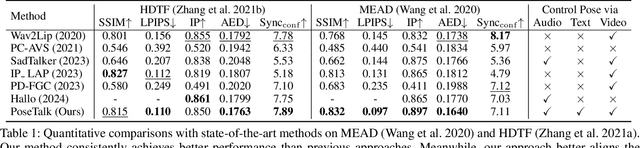
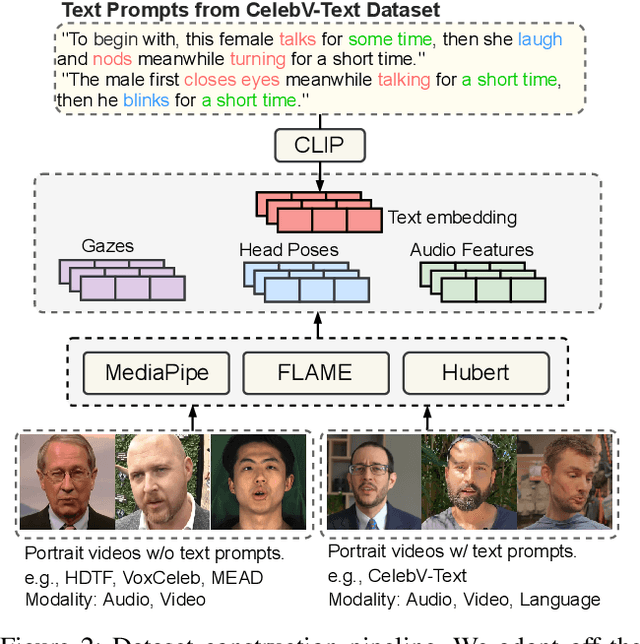
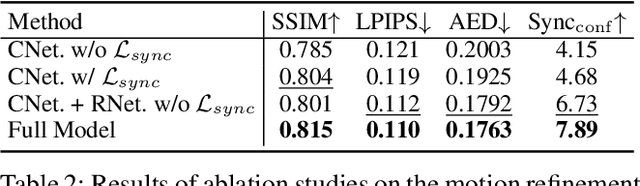
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose \textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4\% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.
360-Degree Panorama Generation from Few Unregistered NFoV Images
Aug 28, 2023



360$^\circ$ panoramas are extensively utilized as environmental light sources in computer graphics. However, capturing a 360$^\circ$ $\times$ 180$^\circ$ panorama poses challenges due to the necessity of specialized and costly equipment, and additional human resources. Prior studies develop various learning-based generative methods to synthesize panoramas from a single Narrow Field-of-View (NFoV) image, but they are limited in alterable input patterns, generation quality, and controllability. To address these issues, we propose a novel pipeline called PanoDiff, which efficiently generates complete 360$^\circ$ panoramas using one or more unregistered NFoV images captured from arbitrary angles. Our approach has two primary components to overcome the limitations. Firstly, a two-stage angle prediction module to handle various numbers of NFoV inputs. Secondly, a novel latent diffusion-based panorama generation model uses incomplete panorama and text prompts as control signals and utilizes several geometric augmentation schemes to ensure geometric properties in generated panoramas. Experiments show that PanoDiff achieves state-of-the-art panoramic generation quality and high controllability, making it suitable for applications such as content editing.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023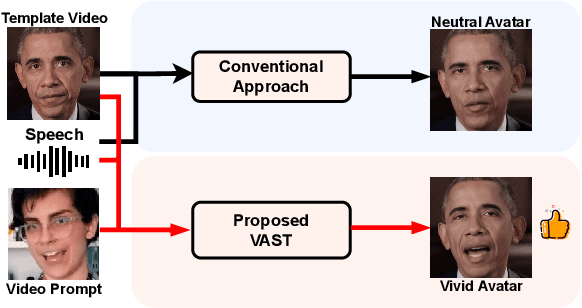

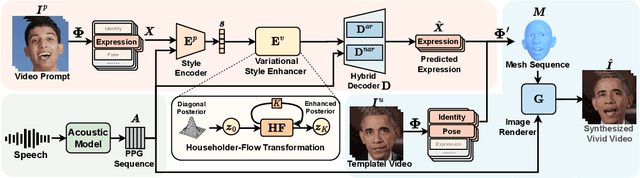

Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Learning Dense UV Completion for Human Mesh Recovery
Aug 10, 2023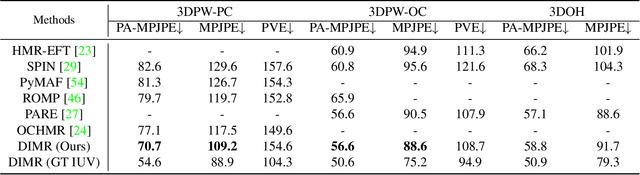
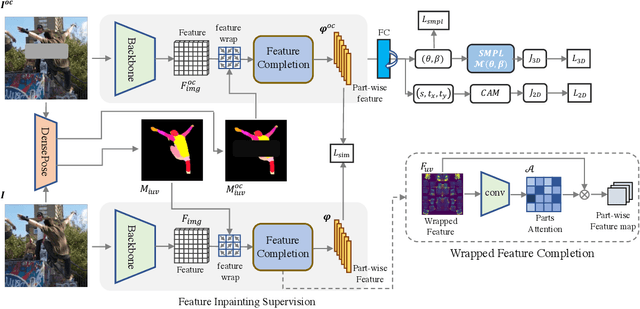
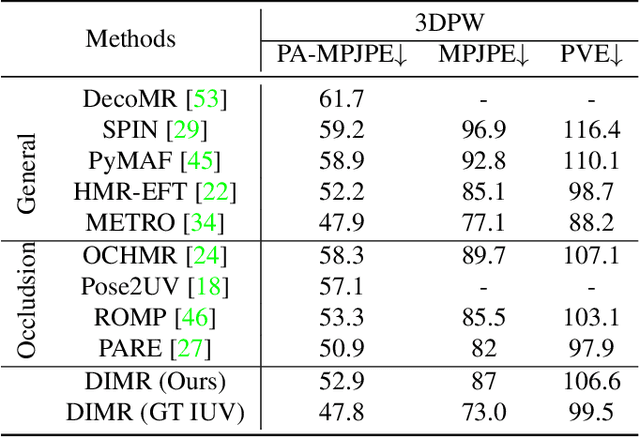

Human mesh reconstruction from a single image is challenging in the presence of occlusion, which can be caused by self, objects, or other humans. Existing methods either fail to separate human features accurately or lack proper supervision for feature completion. In this paper, we propose Dense Inpainting Human Mesh Recovery (DIMR), a two-stage method that leverages dense correspondence maps to handle occlusion. Our method utilizes a dense correspondence map to separate visible human features and completes human features on a structured UV map dense human with an attention-based feature completion module. We also design a feature inpainting training procedure that guides the network to learn from unoccluded features. We evaluate our method on several datasets and demonstrate its superior performance under heavily occluded scenarios compared to other methods. Extensive experiments show that our method obviously outperforms prior SOTA methods on heavily occluded images and achieves comparable results on the standard benchmarks (3DPW).
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 12, 2022
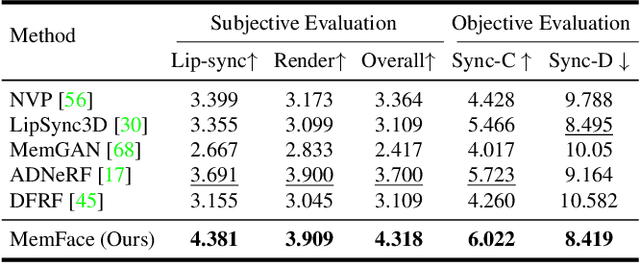
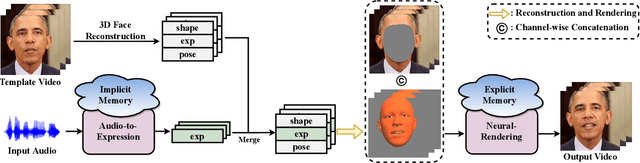
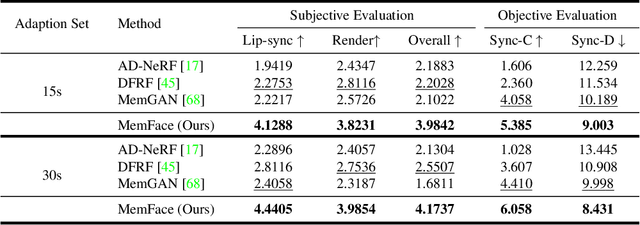
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
StableFace: Analyzing and Improving Motion Stability for Talking Face Generation
Aug 29, 2022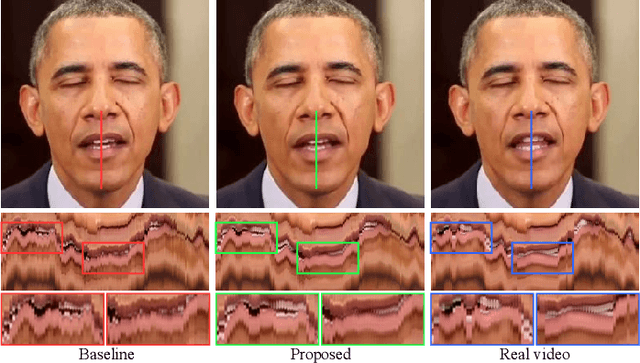
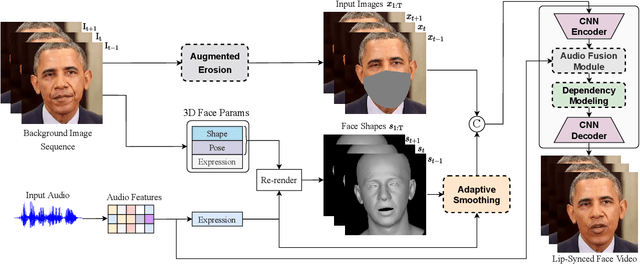
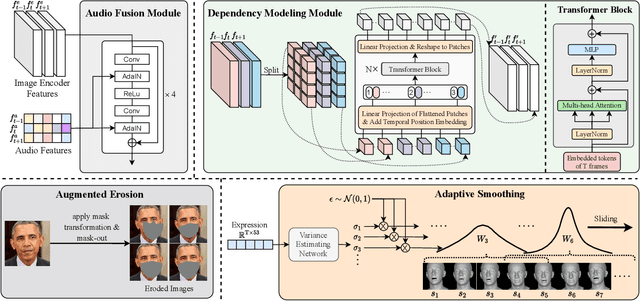

While previous speech-driven talking face generation methods have made significant progress in improving the visual quality and lip-sync quality of the synthesized videos, they pay less attention to lip motion jitters which greatly undermine the realness of talking face videos. What causes motion jitters, and how to mitigate the problem? In this paper, we conduct systematic analyses on the motion jittering problem based on a state-of-the-art pipeline that uses 3D face representations to bridge the input audio and output video, and improve the motion stability with a series of effective designs. We find that several issues can lead to jitters in synthesized talking face video: 1) jitters from the input 3D face representations; 2) training-inference mismatch; 3) lack of dependency modeling among video frames. Accordingly, we propose three effective solutions to address this issue: 1) we propose a gaussian-based adaptive smoothing module to smooth the 3D face representations to eliminate jitters in the input; 2) we add augmented erosions on the input data of the neural renderer in training to simulate the distortion in inference to reduce mismatch; 3) we develop an audio-fused transformer generator to model dependency among video frames. Besides, considering there is no off-the-shelf metric for measuring motion jitters in talking face video, we devise an objective metric (Motion Stability Index, MSI), to quantitatively measure the motion jitters by calculating the reciprocal of variance acceleration. Extensive experimental results show the superiority of our method on motion-stable face video generation, with better quality than previous systems.
Generative Compression for Face Video: A Hybrid Scheme
Apr 26, 2022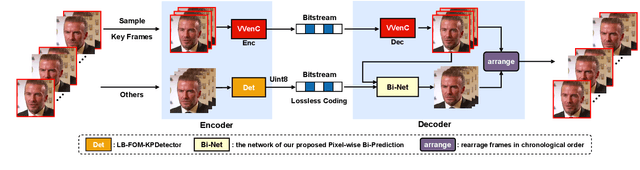

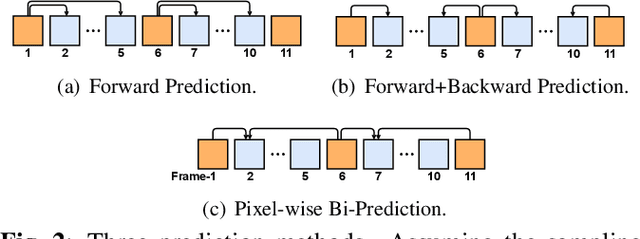
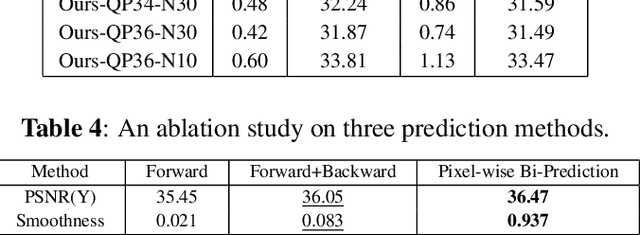
As the latest video coding standard, versatile video coding (VVC) has shown its ability in retaining pixel quality. To excavate more compression potential for video conference scenarios under ultra-low bitrate, this paper proposes a bitrate adjustable hybrid compression scheme for face video. This hybrid scheme combines the pixel-level precise recovery capability of traditional coding with the generation capability of deep learning based on abridged information, where Pixel wise Bi-Prediction, Low-Bitrate-FOM and Lossless Keypoint Encoder collaborate to achieve PSNR up to 36.23 dB at a low bitrate of 1.47 KB/s. Without introducing any additional bitrate, our method has a clear advantage over VVC under a completely fair comparative experiment, which proves the effectiveness of our proposed scheme. Moreover, our scheme can adapt to any existing encoder / configuration to deal with different encoding requirements, and the bitrate can be dynamically adjusted according to the network condition.
Transformer-S2A: Robust and Efficient Speech-to-Animation
Nov 18, 2021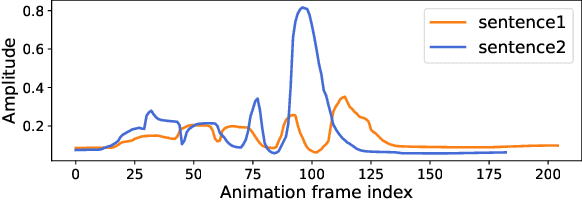
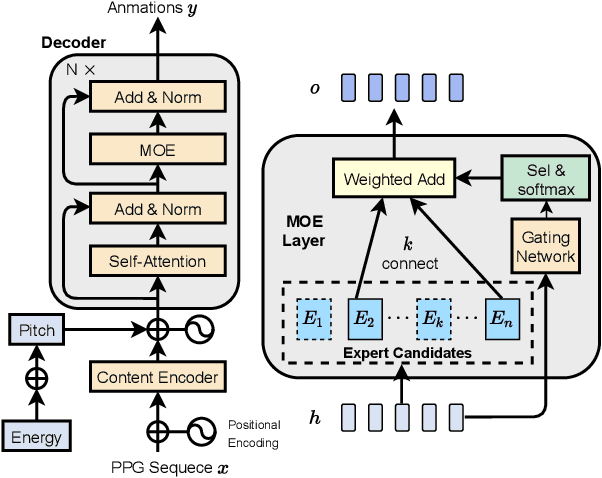
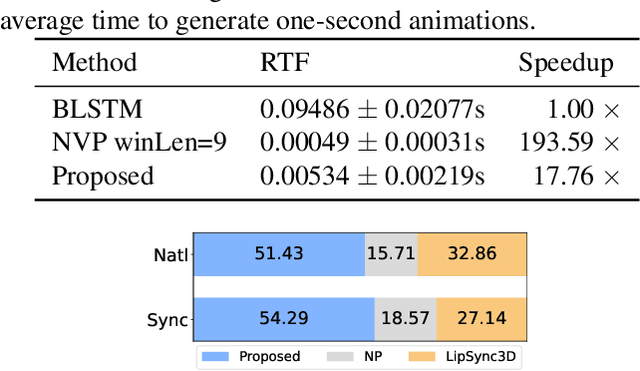

We propose a novel robust and efficient Speech-to-Animation (S2A) approach for synchronized facial animation generation in human-computer interaction. Compared with conventional approaches, the proposed approach utilize phonetic posteriorgrams (PPGs) of spoken phonemes as input to ensure the cross-language and cross-speaker ability, and introduce corresponding prosody features (i.e. pitch and energy) to further enhance the expression of generated animation. Mixtureof-experts (MOE)-based Transformer is employed to better model contextual information while provide significant optimization on computation efficiency. Experiments demonstrate the effectiveness of the proposed approach on both objective and subjective evaluation with 17x inference speedup compared with the state-of-the-art approach.
Region-aware Adaptive Instance Normalization for Image Harmonization
Jun 05, 2021


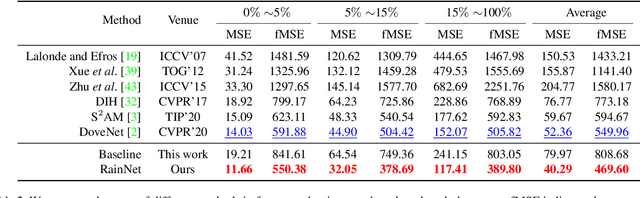
Image composition plays a common but important role in photo editing. To acquire photo-realistic composite images, one must adjust the appearance and visual style of the foreground to be compatible with the background. Existing deep learning methods for harmonizing composite images directly learn an image mapping network from the composite to the real one, without explicit exploration on visual style consistency between the background and the foreground images. To ensure the visual style consistency between the foreground and the background, in this paper, we treat image harmonization as a style transfer problem. In particular, we propose a simple yet effective Region-aware Adaptive Instance Normalization (RAIN) module, which explicitly formulates the visual style from the background and adaptively applies them to the foreground. With our settings, our RAIN module can be used as a drop-in module for existing image harmonization networks and is able to bring significant improvements. Extensive experiments on the existing image harmonization benchmark datasets show the superior capability of the proposed method. Code is available at {https://github.com/junleen/RainNet}.