 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views
Oct 09, 2025



The demand for semantically rich 3D models of indoor scenes is rapidly growing, driven by applications in augmented reality, virtual reality, and robotics. However, creating them from sparse views remains a challenge due to geometric ambiguity. Existing methods often treat semantics as a passive feature painted on an already-formed, and potentially flawed, geometry. We posit that for robust sparse-view reconstruction, semantic understanding instead be an active, guiding force. This paper introduces AlignGS, a novel framework that actualizes this vision by pioneering a synergistic, end-to-end optimization of geometry and semantics. Our method distills rich priors from 2D foundation models and uses them to directly regularize the 3D representation through a set of novel semantic-to-geometry guidance mechanisms, including depth consistency and multi-faceted normal regularization. Extensive evaluations on standard benchmarks demonstrate that our approach achieves state-of-the-art results in novel view synthesis and produces reconstructions with superior geometric accuracy. The results validate that leveraging semantic priors as a geometric regularizer leads to more coherent and complete 3D models from limited input views. Our code is avaliable at https://github.com/MediaX-SJTU/AlignGS .
Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views
Mar 04, 2024



Novel-view synthesis with sparse input views is important for real-world applications like AR/VR and autonomous driving. Recent methods have integrated depth information into NeRFs for sparse input synthesis, leveraging depth prior for geometric and spatial understanding. However, most existing works tend to overlook inaccuracies within depth maps and have low time efficiency. To address these issues, we propose a depth-guided robust and fast point cloud fusion NeRF for sparse inputs. We perceive radiance fields as an explicit voxel grid of features. A point cloud is constructed for each input view, characterized within the voxel grid using matrices and vectors. We accumulate the point cloud of each input view to construct the fused point cloud of the entire scene. Each voxel determines its density and appearance by referring to the point cloud of the entire scene. Through point cloud fusion and voxel grid fine-tuning, inaccuracies in depth values are refined or substituted by those from other views. Moreover, our method can achieve faster reconstruction and greater compactness through effective vector-matrix decomposition. Experimental results underline the superior performance and time efficiency of our approach compared to state-of-the-art baselines.
Label Smoothing for Enhanced Text Sentiment Classification
Dec 11, 2023



Label smoothing is a widely used technique in various domains, such as image classification and speech recognition, known for effectively combating model overfitting. However, there is few research on its application to text sentiment classification. To fill in the gap, this study investigates the implementation of label smoothing for sentiment classification by utilizing different levels of smoothing. The primary objective is to enhance sentiment classification accuracy by transforming discrete labels into smoothed label distributions. Through extensive experiments, we demonstrate the superior performance of label smoothing in text sentiment classification tasks across eight diverse datasets and deep learning architectures: TextCNN, BERT, and RoBERTa, under two learning schemes: training from scratch and fine-tuning.
Harnessing Perceptual Adversarial Patches for Crowd Counting
Sep 16, 2021
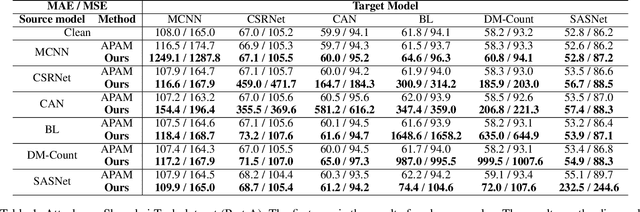
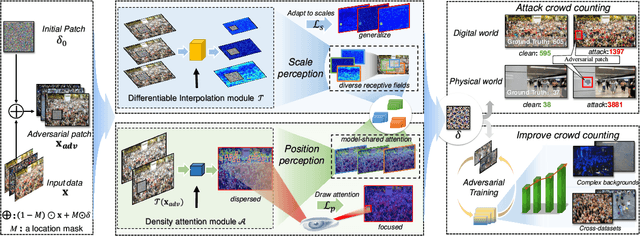
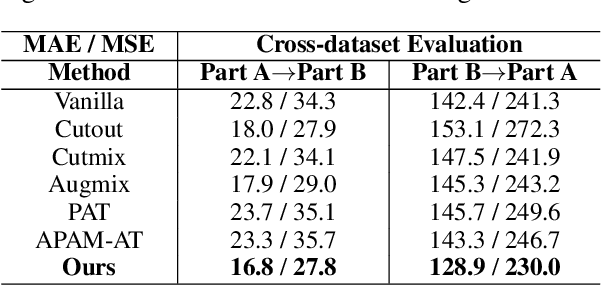
Crowd counting, which is significantly important for estimating the number of people in safety-critical scenes, has been shown to be vulnerable to adversarial examples in the physical world (e.g., adversarial patches). Though harmful, adversarial examples are also valuable for assessing and better understanding model robustness. However, existing adversarial example generation methods in crowd counting scenarios lack strong transferability among different black-box models. Motivated by the fact that transferability is positively correlated to the model-invariant characteristics, this paper proposes the Perceptual Adversarial Patch (PAP) generation framework to learn the shared perceptual features between models by exploiting both the model scale perception and position perception. Specifically, PAP exploits differentiable interpolation and density attention to help learn the invariance between models during training, leading to better transferability. In addition, we surprisingly found that our adversarial patches could also be utilized to benefit the performance of vanilla models for alleviating several challenges including cross datasets and complex backgrounds. Extensive experiments under both digital and physical world scenarios demonstrate the effectiveness of our PAP.