 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Dynamic Gaussian Splatting
Feb 03, 2026While Dynamic Gaussian Splatting enables high-fidelity 4D reconstruction, its deployment is severely hindered by a fundamental dilemma: unconstrained densification leads to excessive memory consumption incompatible with edge devices, whereas heuristic pruning fails to achieve optimal rendering quality under preset Gaussian budgets. In this work, we propose Constrained Dynamic Gaussian Splatting (CDGS), a novel framework that formulates dynamic scene reconstruction as a budget-constrained optimization problem to enforce a strict, user-defined Gaussian budget during training. Our key insight is to introduce a differentiable budget controller as the core optimization driver. Guided by a multi-modal unified importance score, this controller fuses geometric, motion, and perceptual cues for precise capacity regulation. To maximize the utility of this fixed budget, we further decouple the optimization of static and dynamic elements, employing an adaptive allocation mechanism that dynamically distributes capacity based on motion complexity. Furthermore, we implement a three-phase training strategy to seamlessly integrate these constraints, ensuring precise adherence to the target count. Coupled with a dual-mode hybrid compression scheme, CDGS not only strictly adheres to hardware constraints (error < 2%}) but also pushes the Pareto frontier of rate-distortion performance. Extensive experiments demonstrate that CDGS delivers optimal rendering quality under varying capacity limits, achieving over 3x compression compared to state-of-the-art methods.
MultiEgo: A Multi-View Egocentric Video Dataset for 4D Scene Reconstruction
Dec 12, 2025Multi-view egocentric dynamic scene reconstruction holds significant research value for applications in holographic documentation of social interactions. However, existing reconstruction datasets focus on static multi-view or single-egocentric view setups, lacking multi-view egocentric datasets for dynamic scene reconstruction. Therefore, we present MultiEgo, the first multi-view egocentric dataset for 4D dynamic scene reconstruction. The dataset comprises five canonical social interaction scenes: meetings, performances, and a presentation. Each scene provides five authentic egocentric videos captured by participants wearing AR glasses. We design a hardware-based data acquisition system and processing pipeline, achieving sub-millisecond temporal synchronization across views, coupled with accurate pose annotations. Experiment validation demonstrates the practical utility and effectiveness of our dataset for free-viewpoint video (FVV) applications, establishing MultiEgo as a foundational resource for advancing multi-view egocentric dynamic scene reconstruction research.
AlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views
Oct 09, 2025



The demand for semantically rich 3D models of indoor scenes is rapidly growing, driven by applications in augmented reality, virtual reality, and robotics. However, creating them from sparse views remains a challenge due to geometric ambiguity. Existing methods often treat semantics as a passive feature painted on an already-formed, and potentially flawed, geometry. We posit that for robust sparse-view reconstruction, semantic understanding instead be an active, guiding force. This paper introduces AlignGS, a novel framework that actualizes this vision by pioneering a synergistic, end-to-end optimization of geometry and semantics. Our method distills rich priors from 2D foundation models and uses them to directly regularize the 3D representation through a set of novel semantic-to-geometry guidance mechanisms, including depth consistency and multi-faceted normal regularization. Extensive evaluations on standard benchmarks demonstrate that our approach achieves state-of-the-art results in novel view synthesis and produces reconstructions with superior geometric accuracy. The results validate that leveraging semantic priors as a geometric regularizer leads to more coherent and complete 3D models from limited input views. Our code is avaliable at https://github.com/MediaX-SJTU/AlignGS .
PrismGS: Physically-Grounded Anti-Aliasing for High-Fidelity Large-Scale 3D Gaussian Splatting
Oct 09, 20253D Gaussian Splatting (3DGS) has recently enabled real-time photorealistic rendering in compact scenes, but scaling to large urban environments introduces severe aliasing artifacts and optimization instability, especially under high-resolution (e.g., 4K) rendering. These artifacts, manifesting as flickering textures and jagged edges, arise from the mismatch between Gaussian primitives and the multi-scale nature of urban geometry. While existing ``divide-and-conquer'' pipelines address scalability, they fail to resolve this fidelity gap. In this paper, we propose PrismGS, a physically-grounded regularization framework that improves the intrinsic rendering behavior of 3D Gaussians. PrismGS integrates two synergistic regularizers. The first is pyramidal multi-scale supervision, which enforces consistency by supervising the rendering against a pre-filtered image pyramid. This compels the model to learn an inherently anti-aliased representation that remains coherent across different viewing scales, directly mitigating flickering textures. This is complemented by an explicit size regularization that imposes a physically-grounded lower bound on the dimensions of the 3D Gaussians. This prevents the formation of degenerate, view-dependent primitives, leading to more stable and plausible geometric surfaces and reducing jagged edges. Our method is plug-and-play and compatible with existing pipelines. Extensive experiments on MatrixCity, Mill-19, and UrbanScene3D demonstrate that PrismGS achieves state-of-the-art performance, yielding significant PSNR gains around 1.5 dB against CityGaussian, while maintaining its superior quality and robustness under demanding 4K rendering.
VRVVC: Variable-Rate NeRF-Based Volumetric Video Compression
Dec 16, 2024



Neural Radiance Field (NeRF)-based volumetric video has revolutionized visual media by delivering photorealistic Free-Viewpoint Video (FVV) experiences that provide audiences with unprecedented immersion and interactivity. However, the substantial data volumes pose significant challenges for storage and transmission. Existing solutions typically optimize NeRF representation and compression independently or focus on a single fixed rate-distortion (RD) tradeoff. In this paper, we propose VRVVC, a novel end-to-end joint optimization variable-rate framework for volumetric video compression that achieves variable bitrates using a single model while maintaining superior RD performance. Specifically, VRVVC introduces a compact tri-plane implicit residual representation for inter-frame modeling of long-duration dynamic scenes, effectively reducing temporal redundancy. We further propose a variable-rate residual representation compression scheme that leverages a learnable quantization and a tiny MLP-based entropy model. This approach enables variable bitrates through the utilization of predefined Lagrange multipliers to manage the quantization error of all latent representations. Finally, we present an end-to-end progressive training strategy combined with a multi-rate-distortion loss function to optimize the entire framework. Extensive experiments demonstrate that VRVVC achieves a wide range of variable bitrates within a single model and surpasses the RD performance of existing methods across various datasets.
HPC: Hierarchical Progressive Coding Framework for Volumetric Video
Jul 12, 2024


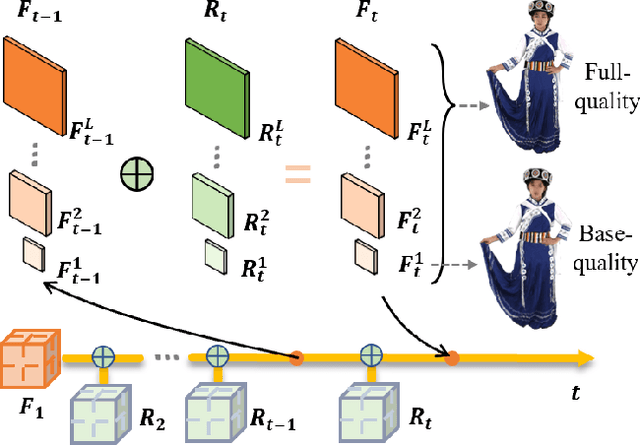
Volumetric video based on Neural Radiance Field (NeRF) holds vast potential for various 3D applications, but its substantial data volume poses significant challenges for compression and transmission. Current NeRF compression lacks the flexibility to adjust video quality and bitrate within a single model for various network and device capacities. To address these issues, we propose HPC, a novel hierarchical progressive volumetric video coding framework achieving variable bitrate using a single model. Specifically, HPC introduces a hierarchical representation with a multi-resolution residual radiance field to reduce temporal redundancy in long-duration sequences while simultaneously generating various levels of detail. Then, we propose an end-to-end progressive learning approach with a multi-rate-distortion loss function to jointly optimize both hierarchical representation and compression. Our HPC trained only once can realize multiple compression levels, while the current methods need to train multiple fixed-bitrate models for different rate-distortion (RD) tradeoffs. Extensive experiments demonstrate that HPC achieves flexible quality levels with variable bitrate by a single model and exhibits competitive RD performance, even outperforming fixed-bitrate models across various datasets.
JointRF: End-to-End Joint Optimization for Dynamic Neural Radiance Field Representation and Compression
May 23, 2024



Neural Radiance Field (NeRF) excels in photo-realistically static scenes, inspiring numerous efforts to facilitate volumetric videos. However, rendering dynamic and long-sequence radiance fields remains challenging due to the significant data required to represent volumetric videos. In this paper, we propose a novel end-to-end joint optimization scheme of dynamic NeRF representation and compression, called JointRF, thus achieving significantly improved quality and compression efficiency against the previous methods. Specifically, JointRF employs a compact residual feature grid and a coefficient feature grid to represent the dynamic NeRF. This representation handles large motions without compromising quality while concurrently diminishing temporal redundancy. We also introduce a sequential feature compression subnetwork to further reduce spatial-temporal redundancy. Finally, the representation and compression subnetworks are end-to-end trained combined within the JointRF. Extensive experiments demonstrate that JointRF can achieve superior compression performance across various datasets.