 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyJudge: Automated Copyright Infringement Identification and Mitigation in Text-to-Image Diffusion Models
Feb 21, 2025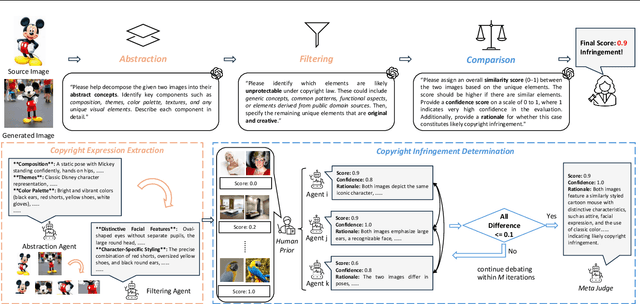
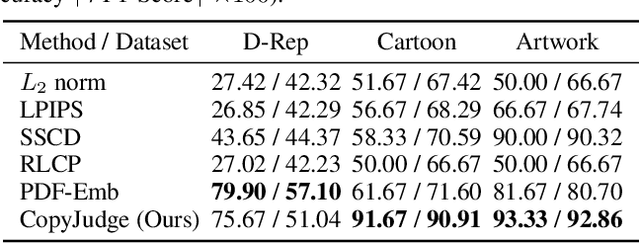
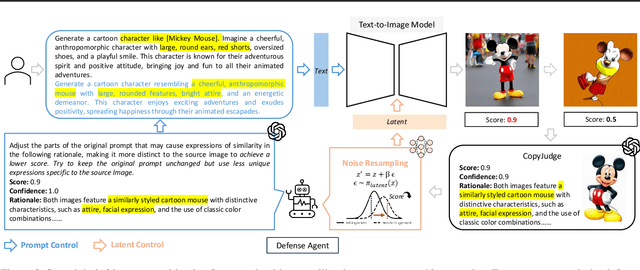
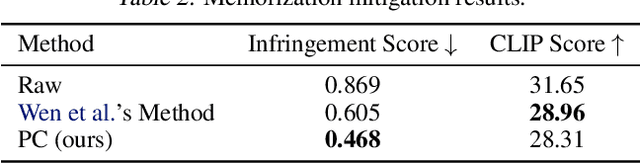
Assessing whether AI-generated images are substantially similar to copyrighted works is a crucial step in resolving copyright disputes. In this paper, we propose CopyJudge, an automated copyright infringement identification framework that leverages large vision-language models (LVLMs) to simulate practical court processes for determining substantial similarity between copyrighted images and those generated by text-to-image diffusion models. Specifically, we employ an abstraction-filtration-comparison test framework with multi-LVLM debate to assess the likelihood of infringement and provide detailed judgment rationales. Based on the judgments, we further introduce a general LVLM-based mitigation strategy that automatically optimizes infringing prompts by avoiding sensitive expressions while preserving the non-infringing content. Besides, our approach can be enhanced by exploring non-infringing noise vectors within the diffusion latent space via reinforcement learning, even without modifying the original prompts. Experimental results show that our identification method achieves comparable state-of-the-art performance, while offering superior generalization and interpretability across various forms of infringement, and that our mitigation method could more effectively mitigate memorization and IP infringement without losing non-infringing expressions.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023

The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Benchmarking the Robustness of Quantized Models
Apr 08, 2023Quantization has emerged as an essential technique for deploying deep neural networks (DNNs) on devices with limited resources. However, quantized models exhibit vulnerabilities when exposed to various noises in real-world applications. Despite the importance of evaluating the impact of quantization on robustness, existing research on this topic is limited and often disregards established principles of robustness evaluation, resulting in incomplete and inconclusive findings. To address this gap, we thoroughly evaluated the robustness of quantized models against various noises (adversarial attacks, natural corruptions, and systematic noises) on ImageNet. Extensive experiments demonstrate that lower-bit quantization is more resilient to adversarial attacks but is more susceptible to natural corruptions and systematic noises. Notably, our investigation reveals that impulse noise (in natural corruptions) and the nearest neighbor interpolation (in systematic noises) have the most significant impact on quantized models. Our research contributes to advancing the robust quantization of models and their deployment in real-world scenarios.
Harnessing Perceptual Adversarial Patches for Crowd Counting
Sep 16, 2021
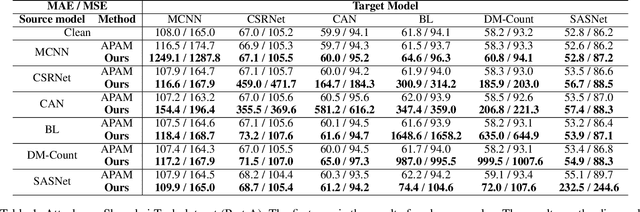
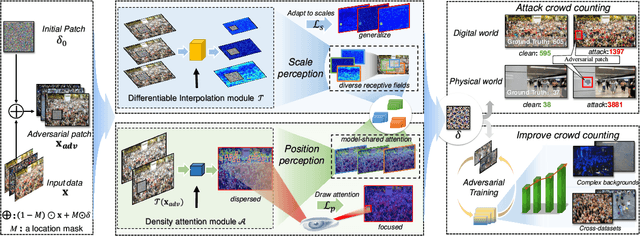
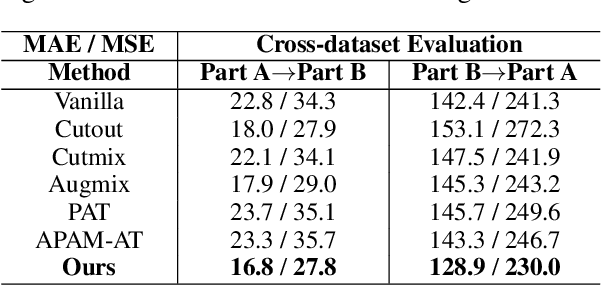
Crowd counting, which is significantly important for estimating the number of people in safety-critical scenes, has been shown to be vulnerable to adversarial examples in the physical world (e.g., adversarial patches). Though harmful, adversarial examples are also valuable for assessing and better understanding model robustness. However, existing adversarial example generation methods in crowd counting scenarios lack strong transferability among different black-box models. Motivated by the fact that transferability is positively correlated to the model-invariant characteristics, this paper proposes the Perceptual Adversarial Patch (PAP) generation framework to learn the shared perceptual features between models by exploiting both the model scale perception and position perception. Specifically, PAP exploits differentiable interpolation and density attention to help learn the invariance between models during training, leading to better transferability. In addition, we surprisingly found that our adversarial patches could also be utilized to benefit the performance of vanilla models for alleviating several challenges including cross datasets and complex backgrounds. Extensive experiments under both digital and physical world scenarios demonstrate the effectiveness of our PAP.
Dual Attention Suppression Attack: Generate Adversarial Camouflage in Physical World
Mar 01, 2021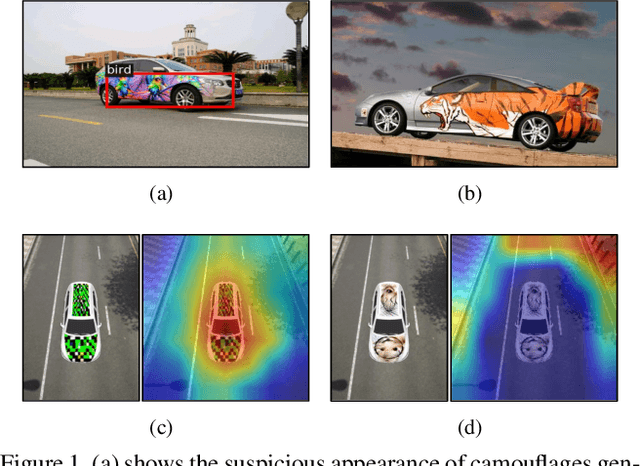
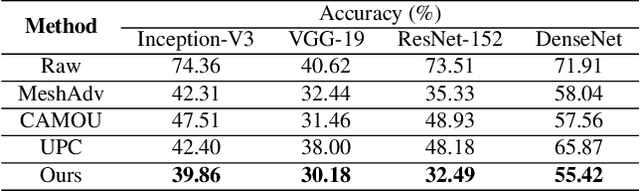
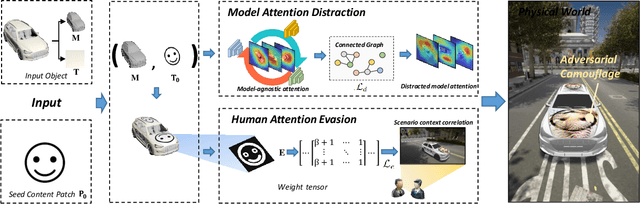
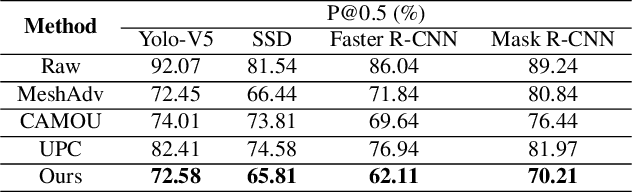
Deep learning models are vulnerable to adversarial examples. As a more threatening type for practical deep learning systems, physical adversarial examples have received extensive research attention in recent years. However, without exploiting the intrinsic characteristics such as model-agnostic and human-specific patterns, existing works generate weak adversarial perturbations in the physical world, which fall short of attacking across different models and show visually suspicious appearance. Motivated by the viewpoint that attention reflects the intrinsic characteristics of the recognition process, this paper proposes the Dual Attention Suppression (DAS) attack to generate visually-natural physical adversarial camouflages with strong transferability by suppressing both model and human attention. As for attacking, we generate transferable adversarial camouflages by distracting the model-shared similar attention patterns from the target to non-target regions. Meanwhile, based on the fact that human visual attention always focuses on salient items (e.g., suspicious distortions), we evade the human-specific bottom-up attention to generate visually-natural camouflages which are correlated to the scenario context. We conduct extensive experiments in both the digital and physical world for classification and detection tasks on up-to-date models (e.g., Yolo-V5) and significantly demonstrate that our method outperforms state-of-the-art methods.