 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyJudge: Automated Copyright Infringement Identification and Mitigation in Text-to-Image Diffusion Models
Paper and Code
Feb 21, 2025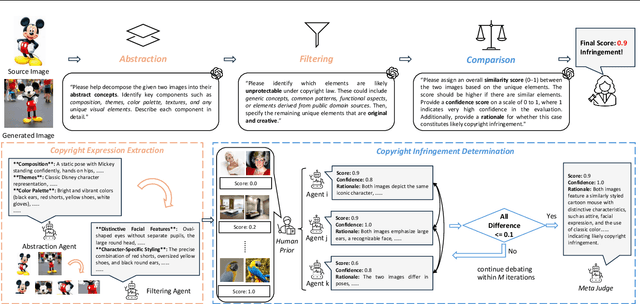
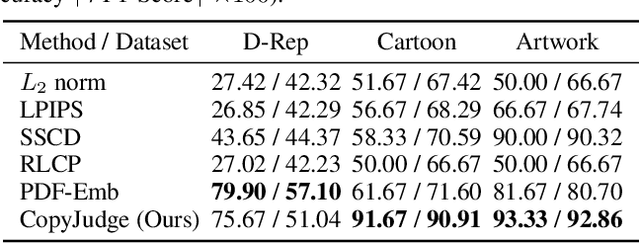
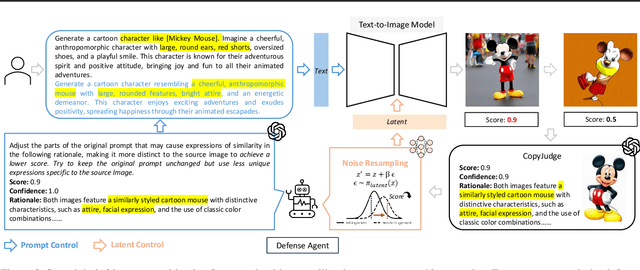
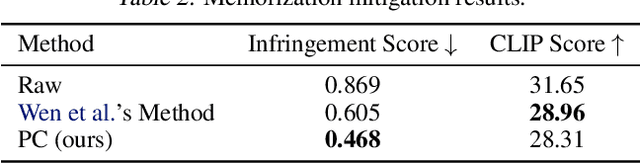
Assessing whether AI-generated images are substantially similar to copyrighted works is a crucial step in resolving copyright disputes. In this paper, we propose CopyJudge, an automated copyright infringement identification framework that leverages large vision-language models (LVLMs) to simulate practical court processes for determining substantial similarity between copyrighted images and those generated by text-to-image diffusion models. Specifically, we employ an abstraction-filtration-comparison test framework with multi-LVLM debate to assess the likelihood of infringement and provide detailed judgment rationales. Based on the judgments, we further introduce a general LVLM-based mitigation strategy that automatically optimizes infringing prompts by avoiding sensitive expressions while preserving the non-infringing content. Besides, our approach can be enhanced by exploring non-infringing noise vectors within the diffusion latent space via reinforcement learning, even without modifying the original prompts. Experimental results show that our identification method achieves comparable state-of-the-art performance, while offering superior generalization and interpretability across various forms of infringement, and that our mitigation method could more effectively mitigate memorization and IP infringement without losing non-infringing expressions.