 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Mesh Refiner for 6-DoF Pose Estimation
Mar 26, 2020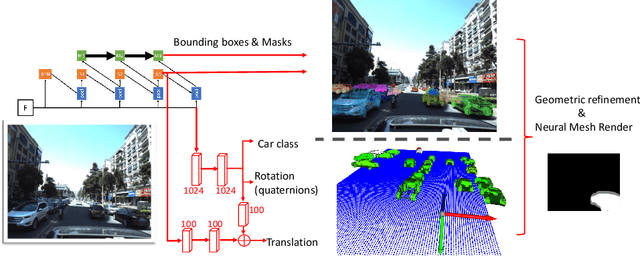
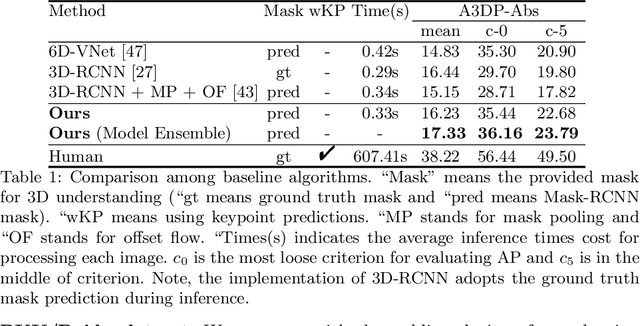
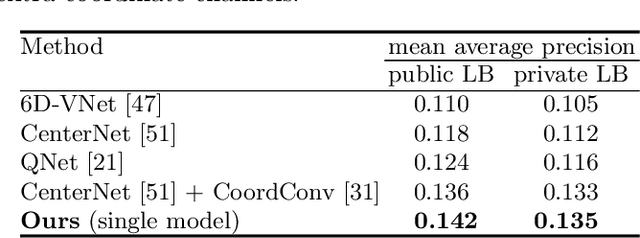
How can we effectively utilise the 2D monocular image information for recovering the 6D pose (6-DoF) of the visual objects? Deep learning has shown to be effective for robust and real-time monocular pose estimation. Oftentimes, the network learns to regress the 6-DoF pose using a naive loss function. However, due to a lack of geometrical scene understanding from the directly regressed pose estimation, there are misalignments between the rendered mesh from the 3D object and the 2D instance segmentation result, e.g., bounding boxes and masks prediction. This paper bridges the gap between 2D mask generation and 3D location prediction via a differentiable neural mesh renderer. We utilise the overlay between the accurate mask prediction and less accurate mesh prediction to iteratively optimise the direct regressed 6D pose information with a focus on translation estimation. By leveraging geometry, we demonstrate that our technique significantly improves direct regression performance on the difficult task of translation estimation and achieve the state of the art results on Peking University/Baidu - Autonomous Driving dataset and the ApolloScape 3D Car Instance dataset. The code can be found at \url{https://bit.ly/2IRihfU}.