 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
From Gallery to Wrist: Realistic 3D Bracelet Insertion in Videos
Jul 27, 2025Inserting 3D objects into videos is a longstanding challenge in computer graphics with applications in augmented reality, virtual try-on, and video composition. Achieving both temporal consistency, or realistic lighting remains difficult, particularly in dynamic scenarios with complex object motion, perspective changes, and varying illumination. While 2D diffusion models have shown promise for producing photorealistic edits, they often struggle with maintaining temporal coherence across frames. Conversely, traditional 3D rendering methods excel in spatial and temporal consistency but fall short in achieving photorealistic lighting. In this work, we propose a hybrid object insertion pipeline that combines the strengths of both paradigms. Specifically, we focus on inserting bracelets into dynamic wrist scenes, leveraging the high temporal consistency of 3D Gaussian Splatting (3DGS) for initial rendering and refining the results using a 2D diffusion-based enhancement model to ensure realistic lighting interactions. Our method introduces a shading-driven pipeline that separates intrinsic object properties (albedo, shading, reflectance) and refines both shading and sRGB images for photorealism. To maintain temporal coherence, we optimize the 3DGS model with multi-frame weighted adjustments. This is the first approach to synergize 3D rendering and 2D diffusion for video object insertion, offering a robust solution for realistic and consistent video editing. Project Page: https://cjeen.github.io/BraceletPaper/
LoRA-Edit: Controllable First-Frame-Guided Video Editing via Mask-Aware LoRA Fine-Tuning
Jun 11, 2025Video editing using diffusion models has achieved remarkable results in generating high-quality edits for videos. However, current methods often rely on large-scale pretraining, limiting flexibility for specific edits. First-frame-guided editing provides control over the first frame, but lacks flexibility over subsequent frames. To address this, we propose a mask-based LoRA (Low-Rank Adaptation) tuning method that adapts pretrained Image-to-Video (I2V) models for flexible video editing. Our approach preserves background regions while enabling controllable edits propagation. This solution offers efficient and adaptable video editing without altering the model architecture. To better steer this process, we incorporate additional references, such as alternate viewpoints or representative scene states, which serve as visual anchors for how content should unfold. We address the control challenge using a mask-driven LoRA tuning strategy that adapts a pre-trained image-to-video model to the editing context. The model must learn from two distinct sources: the input video provides spatial structure and motion cues, while reference images offer appearance guidance. A spatial mask enables region-specific learning by dynamically modulating what the model attends to, ensuring that each area draws from the appropriate source. Experimental results show our method achieves superior video editing performance compared to state-of-the-art methods.
GenesisTex: Adapting Image Denoising Diffusion to Texture Space
Mar 26, 2024



We present GenesisTex, a novel method for synthesizing textures for 3D geometries from text descriptions. GenesisTex adapts the pretrained image diffusion model to texture space by texture space sampling. Specifically, we maintain a latent texture map for each viewpoint, which is updated with predicted noise on the rendering of the corresponding viewpoint. The sampled latent texture maps are then decoded into a final texture map. During the sampling process, we focus on both global and local consistency across multiple viewpoints: global consistency is achieved through the integration of style consistency mechanisms within the noise prediction network, and low-level consistency is achieved by dynamically aligning latent textures. Finally, we apply reference-based inpainting and img2img on denser views for texture refinement. Our approach overcomes the limitations of slow optimization in distillation-based methods and instability in inpainting-based methods. Experiments on meshes from various sources demonstrate that our method surpasses the baseline methods quantitatively and qualitatively.
Multi-Sample Training for Neural Image Compression
Sep 28, 2022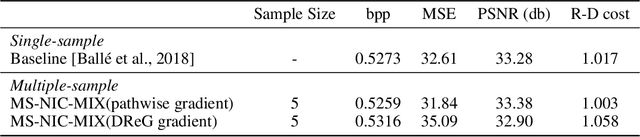
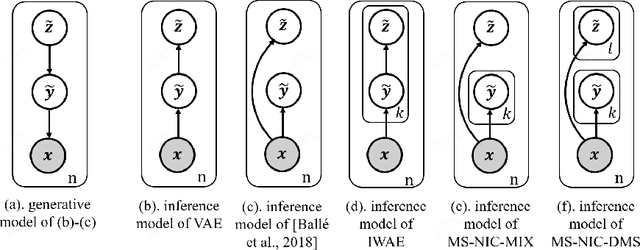

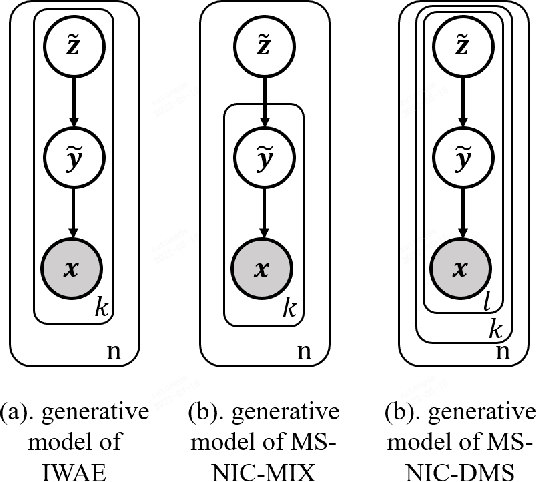
This paper considers the problem of lossy neural image compression (NIC). Current state-of-the-art (sota) methods adopt uniform posterior to approximate quantization noise, and single-sample pathwise estimator to approximate the gradient of evidence lower bound (ELBO). In this paper, we propose to train NIC with multiple-sample importance weighted autoencoder (IWAE) target, which is tighter than ELBO and converges to log likelihood as sample size increases. First, we identify that the uniform posterior of NIC has special properties, which affect the variance and bias of pathwise and score function estimators of the IWAE target. Moreover, we provide insights on a commonly adopted trick in NIC from gradient variance perspective. Based on those analysis, we further propose multiple-sample NIC (MS-NIC), an enhanced IWAE target for NIC. Experimental results demonstrate that it improves sota NIC methods. Our MS-NIC is plug-and-play, and can be easily extended to other neural compression tasks.
Bit Allocation using Optimization
Sep 20, 2022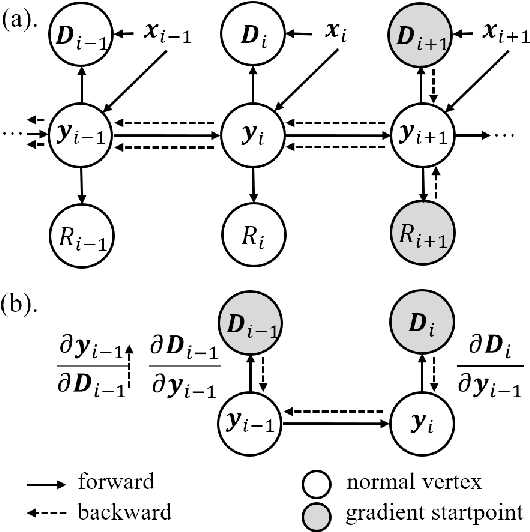
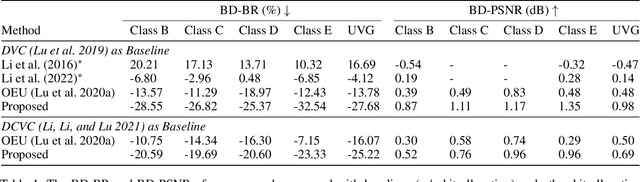


In this paper, we consider the problem of bit allocation in neural video compression (NVC). Due to the frame reference structure, current NVC methods using the same R-D (Rate-Distortion) trade-off parameter $\lambda$ for all frames are suboptimal, which brings the need for bit allocation. Unlike previous methods based on heuristic and empirical R-D models, we propose to solve this problem by gradient-based optimization. Specifically, we first propose a continuous bit implementation method based on Semi-Amortized Variational Inference (SAVI). Then, we propose a pixel-level implicit bit allocation method using iterative optimization by changing the SAVI target. Moreover, we derive the precise R-D model based on the differentiable trait of NVC. And we show the optimality of our method by proofing its equivalence to the bit allocation with precise R-D model. Experimental results show that our approach significantly improves NVC methods and outperforms existing bit allocation methods. Our approach is plug-and-play for all differentiable NVC methods, and it can be directly adopted on existing pre-trained models.
Flexible Neural Image Compression via Code Editing
Sep 19, 2022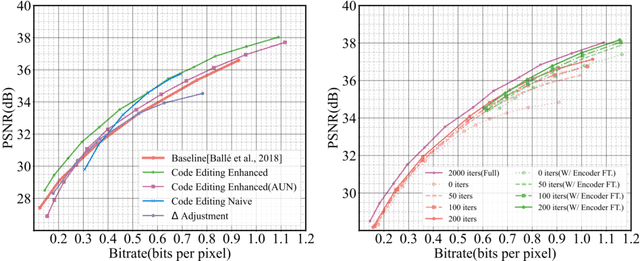
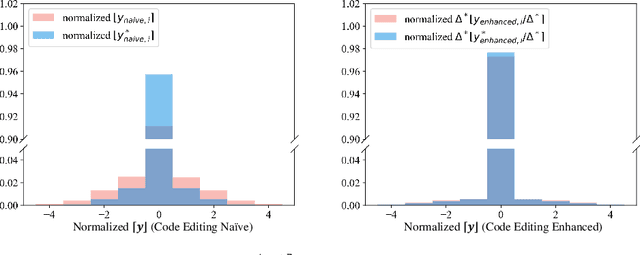
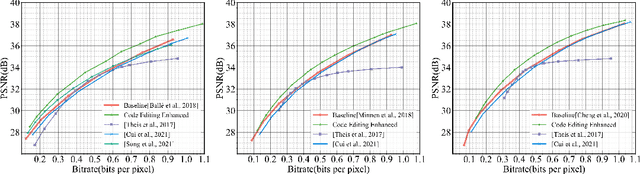
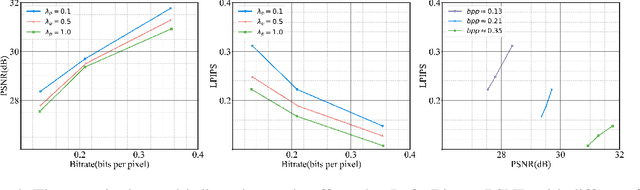
Neural image compression (NIC) has outperformed traditional image codecs in rate-distortion (R-D) performance. However, it usually requires a dedicated encoder-decoder pair for each point on R-D curve, which greatly hinders its practical deployment. While some recent works have enabled bitrate control via conditional coding, they impose strong prior during training and provide limited flexibility. In this paper we propose Code Editing, a highly flexible coding method for NIC based on semi-amortized inference and adaptive quantization. Our work is a new paradigm for variable bitrate NIC. Furthermore, experimental results show that our method surpasses existing variable-rate methods, and achieves ROI coding and multi-distortion trade-off with a single decoder.
SketchSampler: Sketch-based 3D Reconstruction via View-dependent Depth Sampling
Aug 14, 2022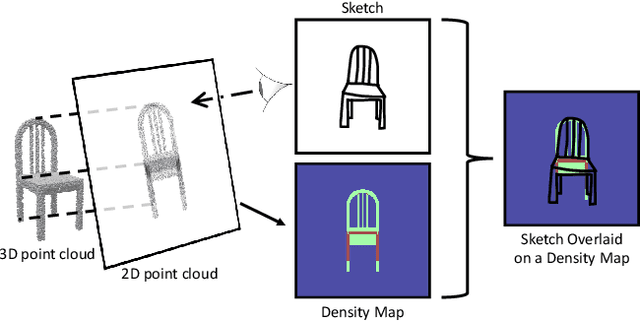
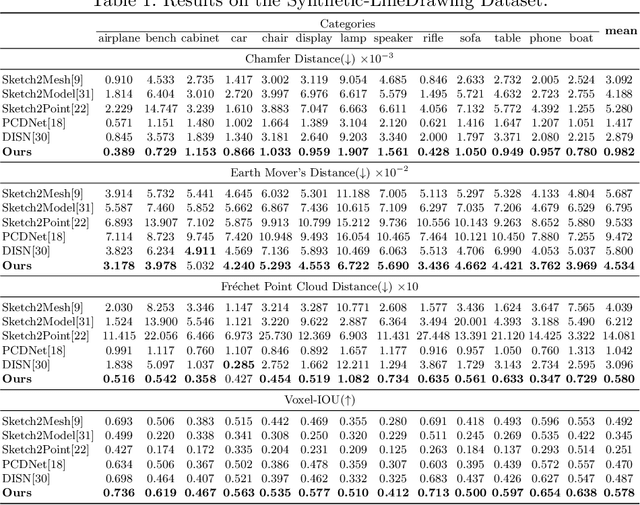
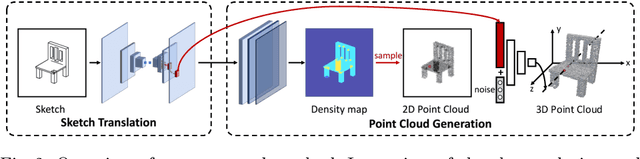
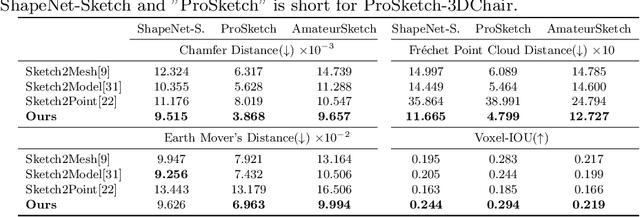
Reconstructing a 3D shape based on a single sketch image is challenging due to the large domain gap between a sparse, irregular sketch and a regular, dense 3D shape. Existing works try to employ the global feature extracted from sketch to directly predict the 3D coordinates, but they usually suffer from losing fine details that are not faithful to the input sketch. Through analyzing the 3D-to-2D projection process, we notice that the density map that characterizes the distribution of 2D point clouds (i.e., the probability of points projected at each location of the projection plane) can be used as a proxy to facilitate the reconstruction process. To this end, we first translate a sketch via an image translation network to a more informative 2D representation that can be used to generate a density map. Next, a 3D point cloud is reconstructed via a two-stage probabilistic sampling process: first recovering the 2D points (i.e., the x and y coordinates) by sampling the density map; and then predicting the depth (i.e., the z coordinate) by sampling the depth values at the ray determined by each 2D point. Extensive experiments are conducted, and both quantitative and qualitative results show that our proposed approach significantly outperforms other baseline methods.
PO-ELIC: Perception-Oriented Efficient Learned Image Coding
May 28, 2022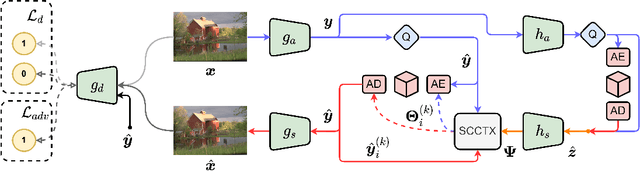

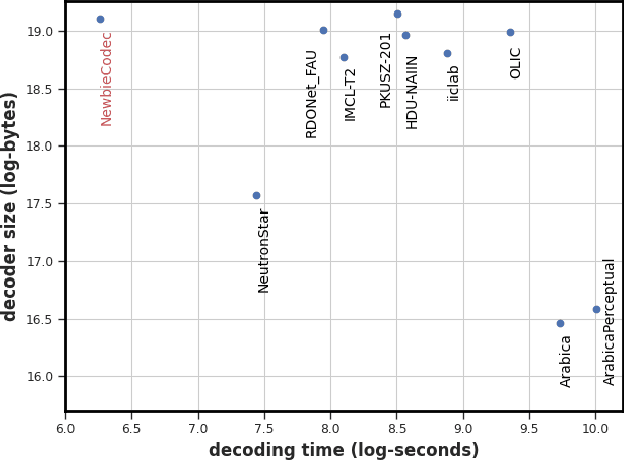

In the past years, learned image compression (LIC) has achieved remarkable performance. The recent LIC methods outperform VVC in both PSNR and MS-SSIM. However, the low bit-rate reconstructions of LIC suffer from artifacts such as blurring, color drifting and texture missing. Moreover, those varied artifacts make image quality metrics correlate badly with human perceptual quality. In this paper, we propose PO-ELIC, i.e., Perception-Oriented Efficient Learned Image Coding. To be specific, we adapt ELIC, one of the state-of-the-art LIC models, with adversarial training techniques. We apply a mixture of losses including hinge-form adversarial loss, Charbonnier loss, and style loss, to finetune the model towards better perceptual quality. Experimental results demonstrate that our method achieves comparable perceptual quality with HiFiC with much lower bitrate.