 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
From Gallery to Wrist: Realistic 3D Bracelet Insertion in Videos
Jul 27, 2025Inserting 3D objects into videos is a longstanding challenge in computer graphics with applications in augmented reality, virtual try-on, and video composition. Achieving both temporal consistency, or realistic lighting remains difficult, particularly in dynamic scenarios with complex object motion, perspective changes, and varying illumination. While 2D diffusion models have shown promise for producing photorealistic edits, they often struggle with maintaining temporal coherence across frames. Conversely, traditional 3D rendering methods excel in spatial and temporal consistency but fall short in achieving photorealistic lighting. In this work, we propose a hybrid object insertion pipeline that combines the strengths of both paradigms. Specifically, we focus on inserting bracelets into dynamic wrist scenes, leveraging the high temporal consistency of 3D Gaussian Splatting (3DGS) for initial rendering and refining the results using a 2D diffusion-based enhancement model to ensure realistic lighting interactions. Our method introduces a shading-driven pipeline that separates intrinsic object properties (albedo, shading, reflectance) and refines both shading and sRGB images for photorealism. To maintain temporal coherence, we optimize the 3DGS model with multi-frame weighted adjustments. This is the first approach to synergize 3D rendering and 2D diffusion for video object insertion, offering a robust solution for realistic and consistent video editing. Project Page: https://cjeen.github.io/BraceletPaper/
LoRA-Edit: Controllable First-Frame-Guided Video Editing via Mask-Aware LoRA Fine-Tuning
Jun 11, 2025Video editing using diffusion models has achieved remarkable results in generating high-quality edits for videos. However, current methods often rely on large-scale pretraining, limiting flexibility for specific edits. First-frame-guided editing provides control over the first frame, but lacks flexibility over subsequent frames. To address this, we propose a mask-based LoRA (Low-Rank Adaptation) tuning method that adapts pretrained Image-to-Video (I2V) models for flexible video editing. Our approach preserves background regions while enabling controllable edits propagation. This solution offers efficient and adaptable video editing without altering the model architecture. To better steer this process, we incorporate additional references, such as alternate viewpoints or representative scene states, which serve as visual anchors for how content should unfold. We address the control challenge using a mask-driven LoRA tuning strategy that adapts a pre-trained image-to-video model to the editing context. The model must learn from two distinct sources: the input video provides spatial structure and motion cues, while reference images offer appearance guidance. A spatial mask enables region-specific learning by dynamically modulating what the model attends to, ensuring that each area draws from the appropriate source. Experimental results show our method achieves superior video editing performance compared to state-of-the-art methods.
PvNeXt: Rethinking Network Design and Temporal Motion for Point Cloud Video Recognition
Apr 07, 2025Point cloud video perception has become an essential task for the realm of 3D vision. Current 4D representation learning techniques typically engage in iterative processing coupled with dense query operations. Although effective in capturing temporal features, this approach leads to substantial computational redundancy. In this work, we propose a framework, named as PvNeXt, for effective yet efficient point cloud video recognition, via personalized one-shot query operation. Specially, PvNeXt consists of two key modules, the Motion Imitator and the Single-Step Motion Encoder. The former module, the Motion Imitator, is designed to capture the temporal dynamics inherent in sequences of point clouds, thus generating the virtual motion corresponding to each frame. The Single-Step Motion Encoder performs a one-step query operation, associating point cloud of each frame with its corresponding virtual motion frame, thereby extracting motion cues from point cloud sequences and capturing temporal dynamics across the entire sequence. Through the integration of these two modules, {PvNeXt} enables personalized one-shot queries for each frame, effectively eliminating the need for frame-specific looping and intensive query processes. Extensive experiments on multiple benchmarks demonstrate the effectiveness of our method.
Target-Guided Adversarial Point Cloud Transformer Towards Recognition Against Real-world Corruptions
Nov 01, 2024Achieving robust 3D perception in the face of corrupted data presents an challenging hurdle within 3D vision research. Contemporary transformer-based point cloud recognition models, albeit advanced, tend to overfit to specific patterns, consequently undermining their robustness against corruption. In this work, we introduce the Target-Guided Adversarial Point Cloud Transformer, termed APCT, a novel architecture designed to augment global structure capture through an adversarial feature erasing mechanism predicated on patterns discerned at each step during training. Specifically, APCT integrates an Adversarial Significance Identifier and a Target-guided Promptor. The Adversarial Significance Identifier, is tasked with discerning token significance by integrating global contextual analysis, utilizing a structural salience index algorithm alongside an auxiliary supervisory mechanism. The Target-guided Promptor, is responsible for accentuating the propensity for token discard within the self-attention mechanism, utilizing the value derived above, consequently directing the model attention towards alternative segments in subsequent stages. By iteratively applying this strategy in multiple steps during training, the network progressively identifies and integrates an expanded array of object-associated patterns. Extensive experiments demonstrate that our method achieves state-of-the-art results on multiple corruption benchmarks.
Interactive3D: Create What You Want by Interactive 3D Generation
Apr 25, 2024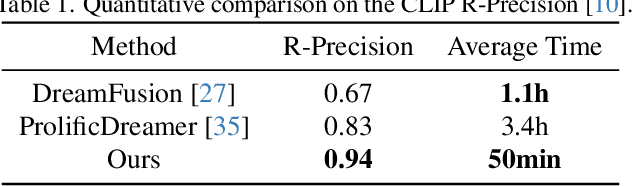


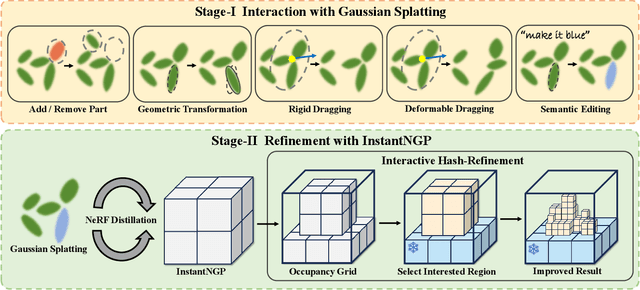
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at \url{https://interactive-3d.github.io/}.
MsSVT++: Mixed-scale Sparse Voxel Transformer with Center Voting for 3D Object Detection
Jan 22, 2024
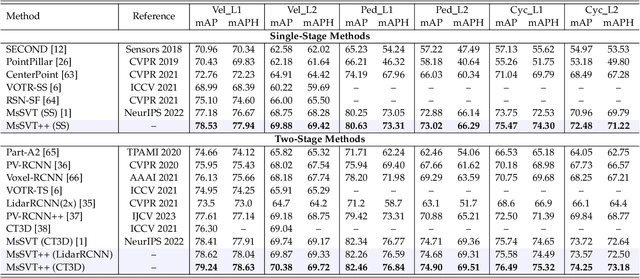
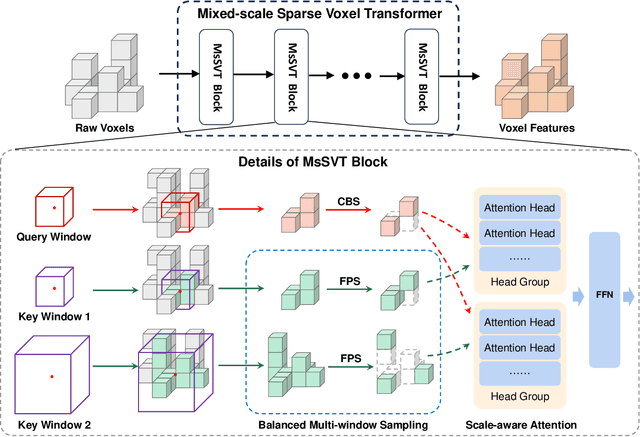
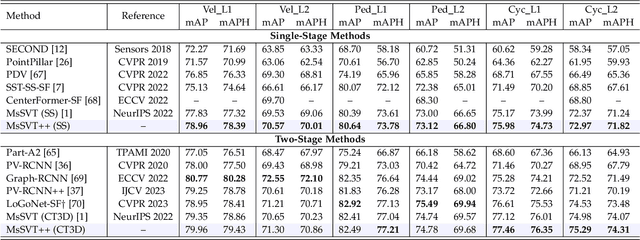
Accurate 3D object detection in large-scale outdoor scenes, characterized by considerable variations in object scales, necessitates features rich in both long-range and fine-grained information. While recent detectors have utilized window-based transformers to model long-range dependencies, they tend to overlook fine-grained details. To bridge this gap, we propose MsSVT++, an innovative Mixed-scale Sparse Voxel Transformer that simultaneously captures both types of information through a divide-and-conquer approach. This approach involves explicitly dividing attention heads into multiple groups, each responsible for attending to information within a specific range. The outputs of these groups are subsequently merged to obtain final mixed-scale features. To mitigate the computational complexity associated with applying a window-based transformer in 3D voxel space, we introduce a novel Chessboard Sampling strategy and implement voxel sampling and gathering operations sparsely using a hash map. Moreover, an important challenge stems from the observation that non-empty voxels are primarily located on the surface of objects, which impedes the accurate estimation of bounding boxes. To overcome this challenge, we introduce a Center Voting module that integrates newly voted voxels enriched with mixed-scale contextual information towards the centers of the objects, thereby improving precise object localization. Extensive experiments demonstrate that our single-stage detector, built upon the foundation of MsSVT++, consistently delivers exceptional performance across diverse datasets.
Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors
Dec 07, 2023



Most 3D generation research focuses on up-projecting 2D foundation models into the 3D space, either by minimizing 2D Score Distillation Sampling (SDS) loss or fine-tuning on multi-view datasets. Without explicit 3D priors, these methods often lead to geometric anomalies and multi-view inconsistency. Recently, researchers have attempted to improve the genuineness of 3D objects by directly training on 3D datasets, albeit at the cost of low-quality texture generation due to the limited texture diversity in 3D datasets. To harness the advantages of both approaches, we propose Bidirectional Diffusion(BiDiff), a unified framework that incorporates both a 3D and a 2D diffusion process, to preserve both 3D fidelity and 2D texture richness, respectively. Moreover, as a simple combination may yield inconsistent generation results, we further bridge them with novel bidirectional guidance. In addition, our method can be used as an initialization of optimization-based models to further improve the quality of 3D model and efficiency of optimization, reducing the generation process from 3.4 hours to 20 minutes. Experimental results have shown that our model achieves high-quality, diverse, and scalable 3D generation. Project website: https://bidiff.github.io/.
Obj-NeRF: Extract Object NeRFs from Multi-view Images
Nov 26, 2023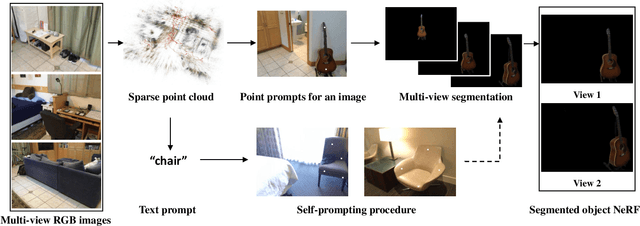
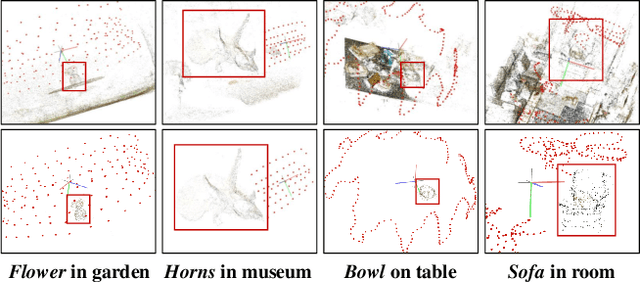


Neural Radiance Fields (NeRFs) have demonstrated remarkable effectiveness in novel view synthesis within 3D environments. However, extracting a radiance field of one specific object from multi-view images encounters substantial challenges due to occlusion and background complexity, thereby presenting difficulties in downstream applications such as NeRF editing and 3D mesh extraction. To solve this problem, in this paper, we propose Obj-NeRF, a comprehensive pipeline that recovers the 3D geometry of a specific object from multi-view images using a single prompt. This method combines the 2D segmentation capabilities of the Segment Anything Model (SAM) in conjunction with the 3D reconstruction ability of NeRF. Specifically, we first obtain multi-view segmentation for the indicated object using SAM with a single prompt. Then, we use the segmentation images to supervise NeRF construction, integrating several effective techniques. Additionally, we construct a large object-level NeRF dataset containing diverse objects, which can be useful in various downstream tasks. To demonstrate the practicality of our method, we also apply Obj-NeRF to various applications, including object removal, rotation, replacement, and recoloring.
Sample-adaptive Augmentation for Point Cloud Recognition Against Real-world Corruptions
Sep 19, 2023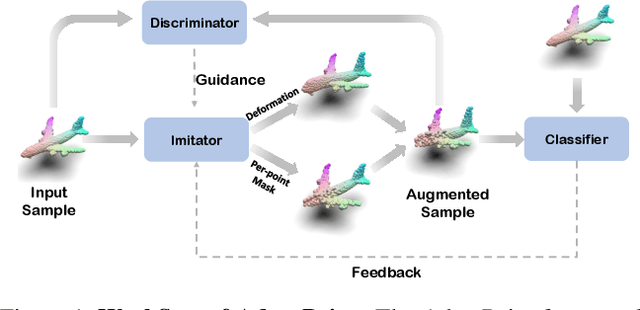

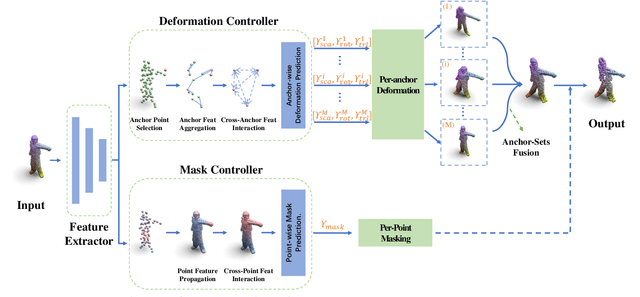

Robust 3D perception under corruption has become an essential task for the realm of 3D vision. While current data augmentation techniques usually perform random transformations on all point cloud objects in an offline way and ignore the structure of the samples, resulting in over-or-under enhancement. In this work, we propose an alternative to make sample-adaptive transformations based on the structure of the sample to cope with potential corruption via an auto-augmentation framework, named as AdaptPoint. Specially, we leverage a imitator, consisting of a Deformation Controller and a Mask Controller, respectively in charge of predicting deformation parameters and producing a per-point mask, based on the intrinsic structural information of the input point cloud, and then conduct corruption simulations on top. Then a discriminator is utilized to prevent the generation of excessive corruption that deviates from the original data distribution. In addition, a perception-guidance feedback mechanism is incorporated to guide the generation of samples with appropriate difficulty level. Furthermore, to address the paucity of real-world corrupted point cloud, we also introduce a new dataset ScanObjectNN-C, that exhibits greater similarity to actual data in real-world environments, especially when contrasted with preceding CAD datasets. Experiments show that our method achieves state-of-the-art results on multiple corruption benchmarks, including ModelNet-C, our ScanObjectNN-C, and ShapeNet-C.