 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionRCNN: LiDAR-Camera Fusion for Two-stage 3D Object Detection
Paper and Code
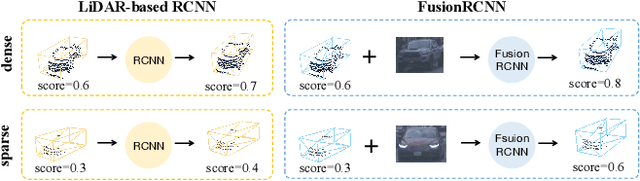



3D object detection with multi-sensors is essential for an accurate and reliable perception system of autonomous driving and robotics. Existing 3D detectors significantly improve the accuracy by adopting a two-stage paradigm which merely relies on LiDAR point clouds for 3D proposal refinement. Though impressive, the sparsity of point clouds, especially for the points far away, making it difficult for the LiDAR-only refinement module to accurately recognize and locate objects.To address this problem, we propose a novel multi-modality two-stage approach named FusionRCNN, which effectively and efficiently fuses point clouds and camera images in the Regions of Interest(RoI). FusionRCNN adaptively integrates both sparse geometry information from LiDAR and dense texture information from camera in a unified attention mechanism. Specifically, it first utilizes RoIPooling to obtain an image set with a unified size and gets the point set by sampling raw points within proposals in the RoI extraction step; then leverages an intra-modality self-attention to enhance the domain-specific features, following by a well-designed cross-attention to fuse the information from two modalities.FusionRCNN is fundamentally plug-and-play and supports different one-stage methods with almost no architectural changes. Extensive experiments on KITTI and Waymo benchmarks demonstrate that our method significantly boosts the performances of popular detectors.Remarkably, FusionRCNN significantly improves the strong SECOND baseline by 6.14% mAP on Waymo, and outperforms competing two-stage approaches. Code will be released soon at https://github.com/xxlbigbrother/Fusion-RCNN.