 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMsSVT++: Mixed-scale Sparse Voxel Transformer with Center Voting for 3D Object Detection
Paper and Code
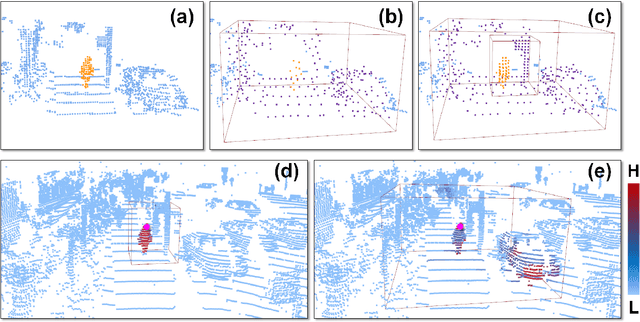
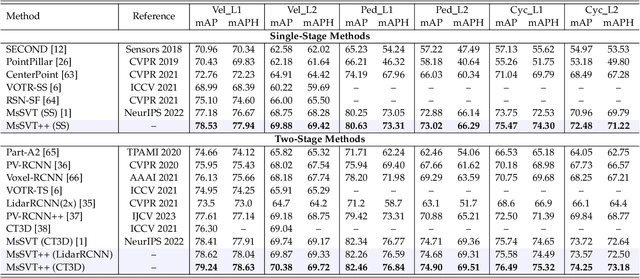
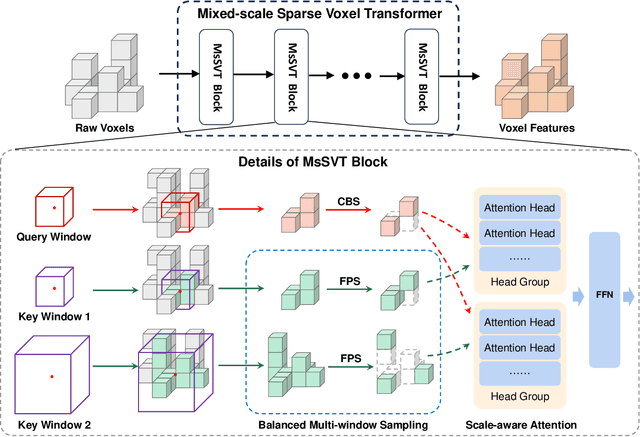
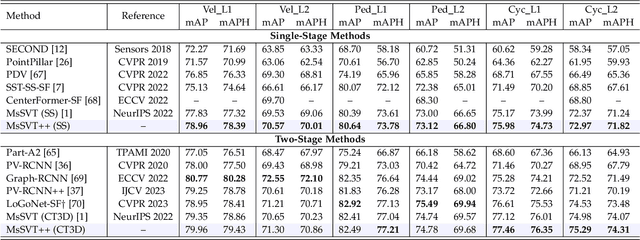
Accurate 3D object detection in large-scale outdoor scenes, characterized by considerable variations in object scales, necessitates features rich in both long-range and fine-grained information. While recent detectors have utilized window-based transformers to model long-range dependencies, they tend to overlook fine-grained details. To bridge this gap, we propose MsSVT++, an innovative Mixed-scale Sparse Voxel Transformer that simultaneously captures both types of information through a divide-and-conquer approach. This approach involves explicitly dividing attention heads into multiple groups, each responsible for attending to information within a specific range. The outputs of these groups are subsequently merged to obtain final mixed-scale features. To mitigate the computational complexity associated with applying a window-based transformer in 3D voxel space, we introduce a novel Chessboard Sampling strategy and implement voxel sampling and gathering operations sparsely using a hash map. Moreover, an important challenge stems from the observation that non-empty voxels are primarily located on the surface of objects, which impedes the accurate estimation of bounding boxes. To overcome this challenge, we introduce a Center Voting module that integrates newly voted voxels enriched with mixed-scale contextual information towards the centers of the objects, thereby improving precise object localization. Extensive experiments demonstrate that our single-stage detector, built upon the foundation of MsSVT++, consistently delivers exceptional performance across diverse datasets.