 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Models in Sequential Recommendations: Bridging Performance Laws with Data Quality Insights
Paper and Code
Dec 03, 2024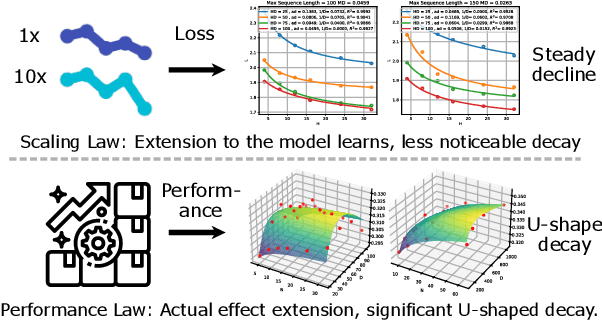
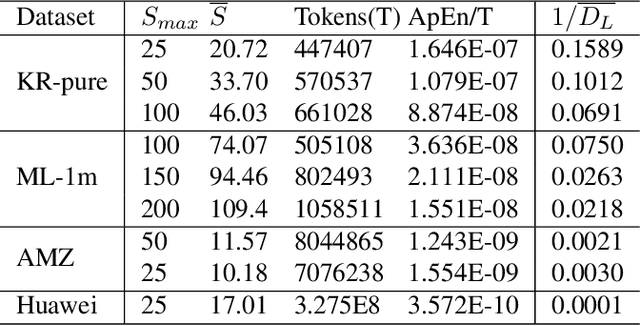
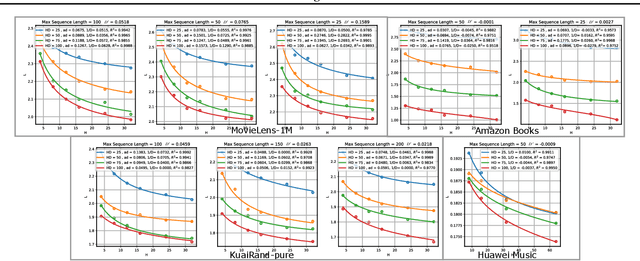
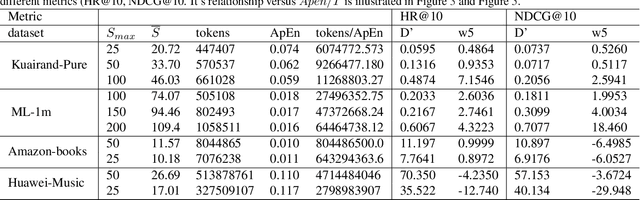
Sequential Recommendation (SR) plays a critical role in predicting users' sequential preferences. Despite its growing prominence in various industries, the increasing scale of SR models incurs substantial computational costs and unpredictability, challenging developers to manage resources efficiently. Under this predicament, Scaling Laws have achieved significant success by examining the loss as models scale up. However, there remains a disparity between loss and model performance, which is of greater concern in practical applications. Moreover, as data continues to expand, it incorporates repetitive and inefficient data. In response, we introduce the Performance Law for SR models, which aims to theoretically investigate and model the relationship between model performance and data quality. Specifically, we first fit the HR and NDCG metrics to transformer-based SR models. Subsequently, we propose Approximate Entropy (ApEn) to assess data quality, presenting a more nuanced approach compared to traditional data quantity metrics. Our method enables accurate predictions across various dataset scales and model sizes, demonstrating a strong correlation in large SR models and offering insights into achieving optimal performance for any given model configuration.