 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSong Aesthetics Evaluation with Multi-Stem Attention and Hierarchical Uncertainty Modeling
Jan 18, 2026Music generative artificial intelligence (AI) is rapidly expanding music content, necessitating automated song aesthetics evaluation. However, existing studies largely focus on speech, audio or singing quality, leaving song aesthetics underexplored. Moreover, conventional approaches often predict a precise Mean Opinion Score (MOS) value directly, which struggles to capture the nuances of human perception in song aesthetics evaluation. This paper proposes a song-oriented aesthetics evaluation framework, featuring two novel modules: 1) Multi-Stem Attention Fusion (MSAF) builds bidirectional cross-attention between mixture-vocal and mixture-accompaniment pairs, fusing them to capture complex musical features; 2) Hierarchical Granularity-Aware Interval Aggregation (HiGIA) learns multi-granularity score probability distributions, aggregates them into a score interval, and applies a regression within the interval to produce the final score. We evaluated on two datasets of full-length songs: SongEval dataset (AI-generated) and an internal aesthetics dataset (human-created), and compared with two state-of-the-art (SOTA) models. Results show that the proposed method achieves stronger performance for multi-dimensional song aesthetics evaluation.
Small Tunes Transformer: Exploring Macro & Micro-Level Hierarchies for Skeleton-Conditioned Melody Generation
Oct 11, 2024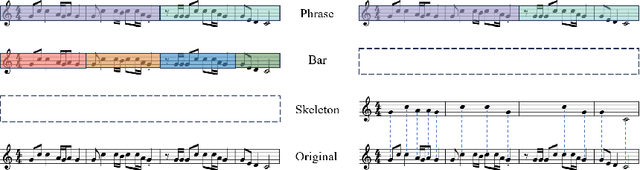
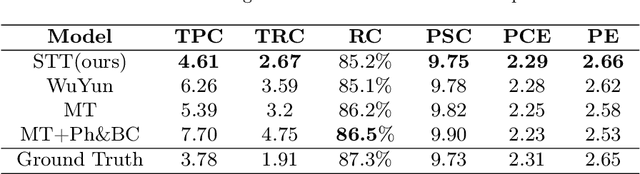
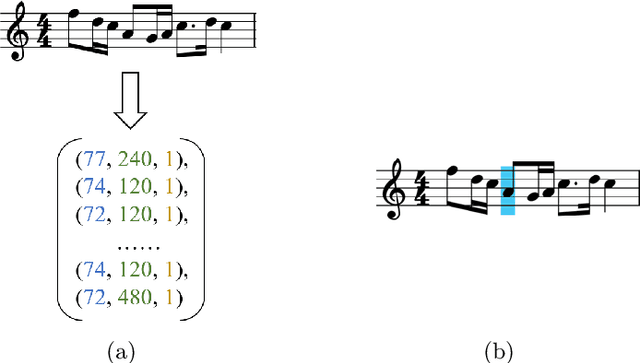

Recently, symbolic music generation has become a focus of numerous deep learning research. Structure as an important part of music, contributes to improving the quality of music, and an increasing number of works start to study the hierarchical structure. In this study, we delve into the multi-level structures within music from macro-level and micro-level hierarchies. At the macro-level hierarchy, we conduct phrase segmentation algorithm to explore how phrases influence the overall development of music, and at the micro-level hierarchy, we design skeleton notes extraction strategy to explore how skeleton notes within each phrase guide the melody generation. Furthermore, we propose a novel Phrase-level Cross-Attention mechanism to capture the intrinsic relationship between macro-level hierarchy and micro-level hierarchy. Moreover, in response to the current lack of research on Chinese-style music, we construct our Small Tunes Dataset: a substantial collection of MIDI files comprising 10088 Small Tunes, a category of traditional Chinese Folk Songs. This dataset serves as the focus of our study. We generate Small Tunes songs utilizing the extracted skeleton notes as conditions, and experiment results indicate that our proposed model, Small Tunes Transformer, outperforms other state-of-the-art models. Besides, we design three novel objective evaluation metrics to evaluate music from both rhythm and melody dimensions.