 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining
Paper and Code
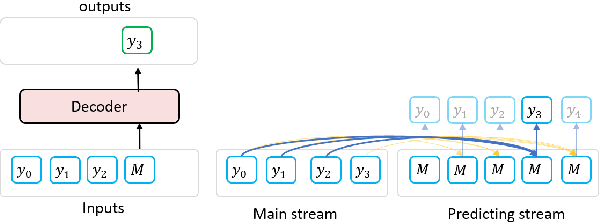
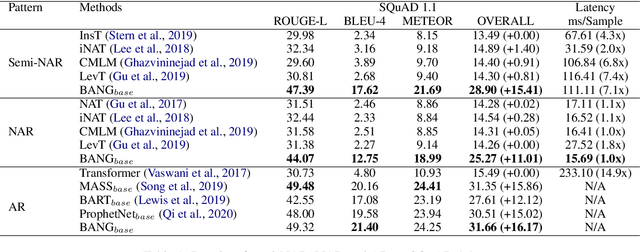
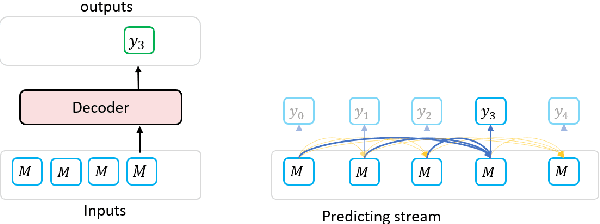

In this paper, we propose BANG, a new pretraining model to Bridge the gap between Autoregressive (AR) and Non-autoregressive (NAR) Generation. AR and NAR generation can be uniformly regarded as what extend of previous tokens can be attended to, and BANG bridges AR and NAR generation through designing a novel model structure for large-scale pre-training. A pretrained BANG model can simultaneously support AR, NAR, and semi-NAR generation to meet different requirements. Experiments on question generation (SQuAD 1.1), summarization (XSum), and dialogue (PersonaChat) show that BANG improves NAR and semi-NAR performance significantly as well as attaining comparable performance with strong AR pretrained models. Compared with the semi-NAR strong baselines, BANG achieves absolute improvements of 14.01 and 5.24 in overall scores of SQuAD and XSum, respectively. In addition, BANG achieves absolute improvements of 10.73, 6.39, and 5.90 in overall scores of SQuAD, XSUM, and PersonaChat compared with the NAR strong baselines, respectively. Our code will be made publicly available in the near future\footnote{https://github.com/microsoft/BANG}.