 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Relation Extraction through Language Probing with Exemplars from Set Co-Expansion
Aug 18, 2023Relation Extraction (RE) is a pivotal task in automatically extracting structured information from unstructured text. In this paper, we present a multi-faceted approach that integrates representative examples and through co-set expansion. The primary goal of our method is to enhance relation classification accuracy and mitigating confusion between contrastive classes. Our approach begins by seeding each relationship class with representative examples. Subsequently, our co-set expansion algorithm enriches training objectives by incorporating similarity measures between target pairs and representative pairs from the target class. Moreover, the co-set expansion process involves a class ranking procedure that takes into account exemplars from contrastive classes. Contextual details encompassing relation mentions are harnessed via context-free Hearst patterns to ascertain contextual similarity. Empirical evaluation demonstrates the efficacy of our co-set expansion approach, resulting in a significant enhancement of relation classification performance. Our method achieves an observed margin of at least 1 percent improvement in accuracy in most settings, on top of existing fine-tuning approaches. To further refine our approach, we conduct an in-depth analysis that focuses on tuning contrastive examples. This strategic selection and tuning effectively reduce confusion between classes sharing similarities, leading to a more precise classification process. Experimental results underscore the effectiveness of our proposed framework for relation extraction. The synergy between co-set expansion and context-aware prompt tuning substantially contributes to improved classification accuracy. Furthermore, the reduction in confusion between contrastive classes through contrastive examples tuning validates the robustness and reliability of our method.
Investigating Stylistic Profiles for the Task of Empathy Classification in Medical Narrative Essays
Feb 03, 2023One important aspect of language is how speakers generate utterances and texts to convey their intended meanings. In this paper, we bring various aspects of the Construction Grammar (CxG) and the Systemic Functional Grammar (SFG) theories in a deep learning computational framework to model empathic language. Our corpus consists of 440 essays written by premed students as narrated simulated patient-doctor interactions. We start with baseline classifiers (state-of-the-art recurrent neural networks and transformer models). Then, we enrich these models with a set of linguistic constructions proving the importance of this novel approach to the task of empathy classification for this dataset. Our results indicate the potential of such constructions to contribute to the overall empathy profile of first-person narrative essays.
Adaptive Multimodal and Multisensory Empathic Technologies for Enhanced Human Communication
Oct 24, 2021As digital social platforms and mobile technologies are becoming more prevalent and robust, the use of Artificial Intelligence (AI) in facilitating human communication will grow. This, in turn, will pave the way for the development of intuitive, adaptive, and effective empathic AI interfaces that better address the needs of socially and culturally diverse communities. I believe such developments must consider a principled framework that includes the human perceptual senses in the digital design process right from the start, for a more accurate, as well as a more aesthetic, memorable, and soothing experience. In this position paper, I suggest features, identify some challenges that need to be addressed in the process, and propose some future research directions that I think should be part of the design and implementation. Such an approach will allow various communities of practice to investigate the areas of intersection between artificial intelligence, on one side, and human communication, perceptual needs and social and cultural values, on the other.
* 10 pages; This position paper was presented at the Rethinking the Senses: A Workshop on Multisensory Embodied Experiences and Disability Interactions associated with the ACM CHI Conference on Human Factors in Computing Systems, May 2021
Exploring the Sensory Spaces of English Perceptual Verbs in Natural Language Data
Oct 19, 2021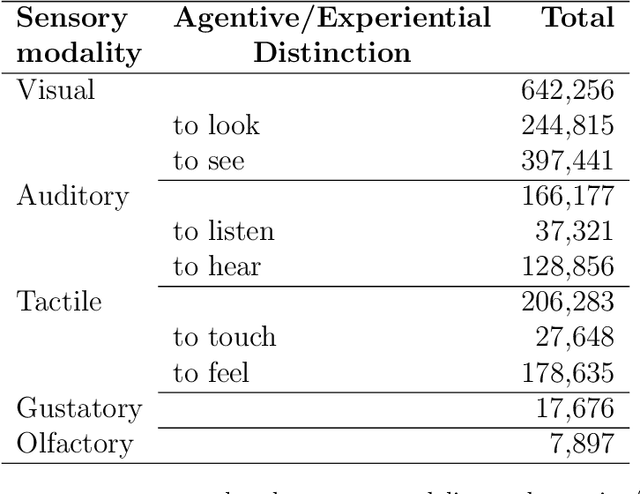

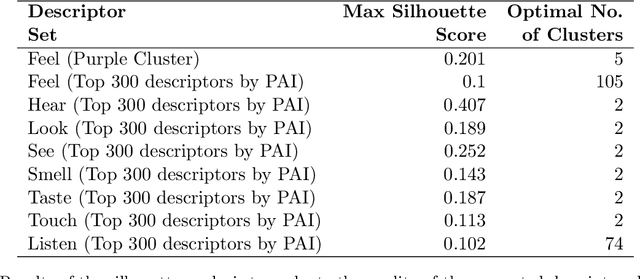
In this study, we explore how language captures the meaning of words, in particular meaning related to sensory experiences learned from statistical distributions across texts. We focus on the most frequent perception verbs of English analyzed from an and Agentive vs. Experiential distinction across the five basic sensory modalities: Visual (to look vs. to see), Auditory (to listen vs. to hear), Tactile (to touch vs. to feel), Olfactory (to smell), and Gustatory (to taste). In this study we report on a data-driven approach based on distributional-semantic word embeddings and clustering models to identify and uncover the descriptor sensory spaces of the perception verbs. In the analysis, we identified differences and similarities of the generated descriptors based on qualitative and quantitative differences of the perceptual experience they denote. For instance, our results show that while the perceptual spaces of the experiential verbs like to see, to hear show a more detached, logical way of knowing and learning, their agentive counterparts (to look, listen) provide a more intentional as well as more intimate and intuitive way of discovering and interacting with the world around us. We believe that such an approach has a high potential to expand our understanding and the applicability of such sensory spaces to different fields of social and cultural analysis. Research on the semantic organization of sensory spaces for various applications might benefit from an the Agentive/Experiential account to address the complexity of multiple senses wired with each other in still unexplored ways.
* 19 pages
Inter-Sense: An Investigation of Sensory Blending in Fiction
Oct 19, 2021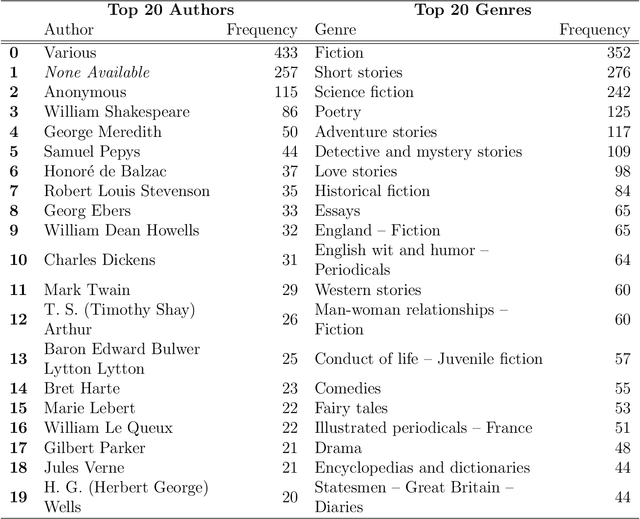
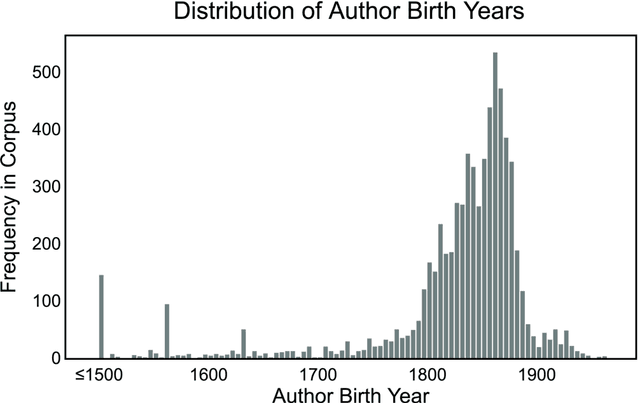

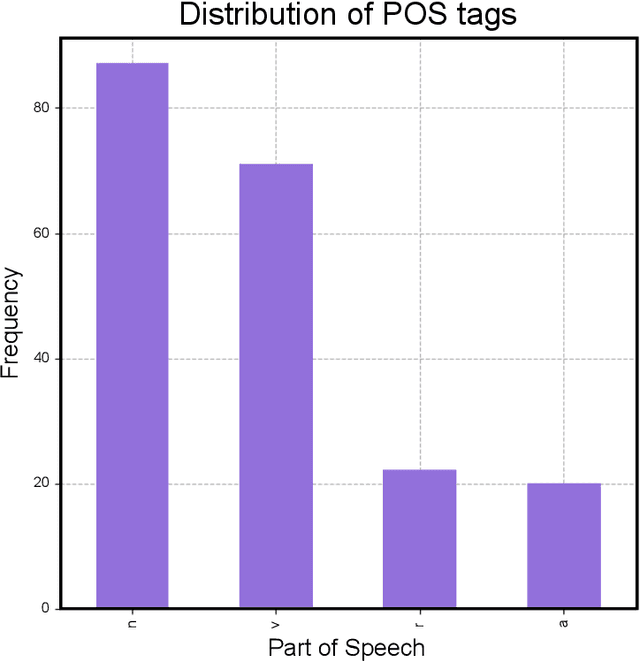
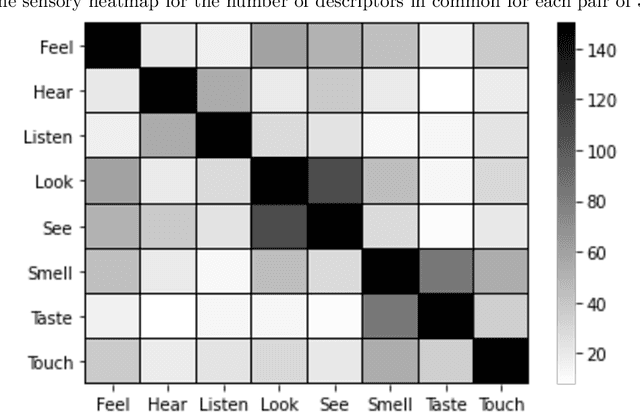
This study reports on the semantic organization of English sensory descriptors of the five basic senses of sight, hearing, touch, taste, and smell in a large corpus of over 8,000 fiction books. We introduce a large-scale text data-driven approach based on distributional-semantic word embeddings to identify and extract these descriptors as well as analyze their mixing interconnections in the resulting conceptual and sensory space. The findings are relevant for research on concept acquisition and representation, as well as for applications that can benefit from a better understanding of perceptual spaces of sensory experiences, in fiction, in particular, and in language in general.
* 18 pages