 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP-Mat: A 3D-and-Instance-Aware Human Matting and Editing Framework with Multiplane Representation
Apr 20, 2025

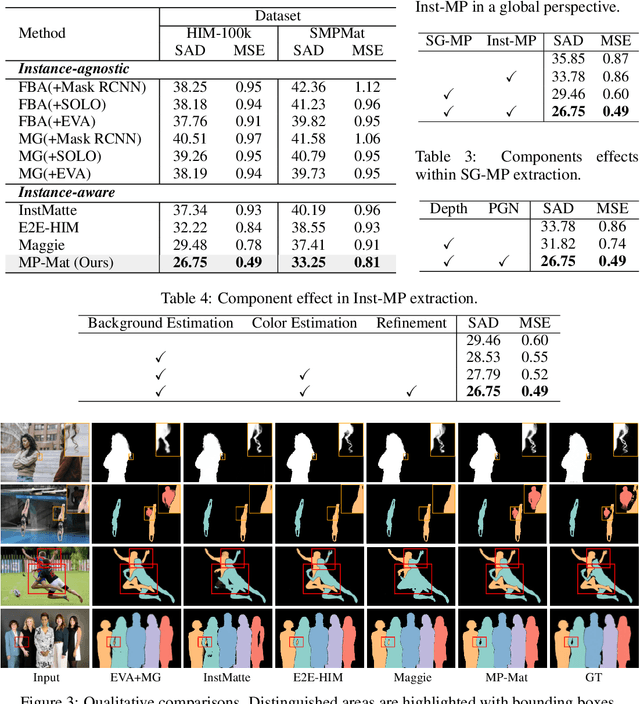

Human instance matting aims to estimate an alpha matte for each human instance in an image, which is challenging as it easily fails in complex cases requiring disentangling mingled pixels belonging to multiple instances along hairy and thin boundary structures. In this work, we address this by introducing MP-Mat, a novel 3D-and-instance-aware matting framework with multiplane representation, where the multiplane concept is designed from two different perspectives: scene geometry level and instance level. Specifically, we first build feature-level multiplane representations to split the scene into multiple planes based on depth differences. This approach makes the scene representation 3D-aware, and can serve as an effective clue for splitting instances in different 3D positions, thereby improving interpretability and boundary handling ability especially in occlusion areas. Then, we introduce another multiplane representation that splits the scene in an instance-level perspective, and represents each instance with both matte and color. We also treat background as a special instance, which is often overlooked by existing methods. Such an instance-level representation facilitates both foreground and background content awareness, and is useful for other down-stream tasks like image editing. Once built, the representation can be reused to realize controllable instance-level image editing with high efficiency. Extensive experiments validate the clear advantage of MP-Mat in matting task. We also demonstrate its superiority in image editing tasks, an area under-explored by existing matting-focused methods, where our approach under zero-shot inference even outperforms trained specialized image editing techniques by large margins. Code is open-sourced at https://github.com/JiaoSiyi/MPMat.git}.
DFIMat: Decoupled Flexible Interactive Matting in Multi-Person Scenarios
Oct 13, 2024Interactive portrait matting refers to extracting the soft portrait from a given image that best meets the user's intent through their inputs. Existing methods often underperform in complex scenarios, mainly due to three factors. (1) Most works apply a tightly coupled network that directly predicts matting results, lacking interpretability and resulting in inadequate modeling. (2) Existing works are limited to a single type of user input, which is ineffective for intention understanding and also inefficient for user operation. (3) The multi-round characteristics have been under-explored, which is crucial for user interaction. To alleviate these limitations, we propose DFIMat, a decoupled framework that enables flexible interactive matting. Specifically, we first decouple the task into 2 sub-ones: localizing target instances by understanding scene semantics and the flexible user inputs, and conducting refinement for instance-level matting. We observe a clear performance gain from decoupling, as it makes sub-tasks easier to learn, and the flexible multi-type input further enhances both effectiveness and efficiency. DFIMat also considers the multi-round interaction property, where a contrastive reasoning module is designed to enhance cross-round refinement. Another limitation for multi-person matting task is the lack of training data. We address this by introducing a new synthetic data generation pipeline that can generate much more realistic samples than previous arts. A new large-scale dataset SMPMat is subsequently established. Experiments verify the significant superiority of DFIMat. With it, we also investigate the roles of different input types, providing valuable principles for users. Our code and dataset can be found at https://github.com/JiaoSiyi/DFIMat.