 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscending Forgery Specificity with Latent Space Augmentation for Generalizable Deepfake Detection
Paper and Code
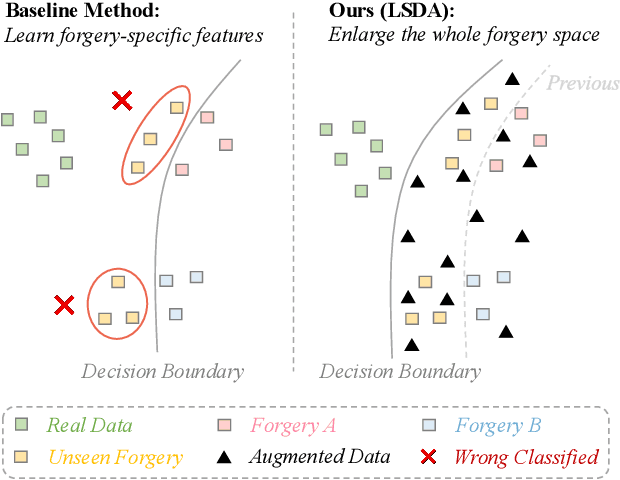

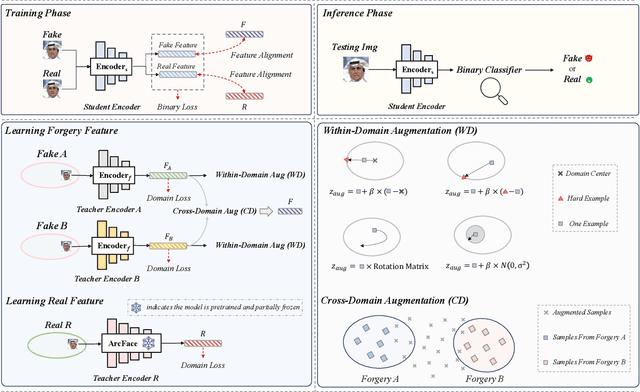

Deepfake detection faces a critical generalization hurdle, with performance deteriorating when there is a mismatch between the distributions of training and testing data. A broadly received explanation is the tendency of these detectors to be overfitted to forgery-specific artifacts, rather than learning features that are widely applicable across various forgeries. To address this issue, we propose a simple yet effective detector called LSDA (\underline{L}atent \underline{S}pace \underline{D}ata \underline{A}ugmentation), which is based on a heuristic idea: representations with a wider variety of forgeries should be able to learn a more generalizable decision boundary, thereby mitigating the overfitting of method-specific features (see Figure. 1). Following this idea, we propose to enlarge the forgery space by constructing and simulating variations within and across forgery features in the latent space. This approach encompasses the acquisition of enriched, domain-specific features and the facilitation of smoother transitions between different forgery types, effectively bridging domain gaps. Our approach culminates in refining a binary classifier that leverages the distilled knowledge from the enhanced features, striving for a generalizable deepfake detector. Comprehensive experiments show that our proposed method is surprisingly effective and transcends state-of-the-art detectors across several widely used benchmarks.