 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Weakly Supervised Open-Vocabulary Object Detection
Dec 19, 2023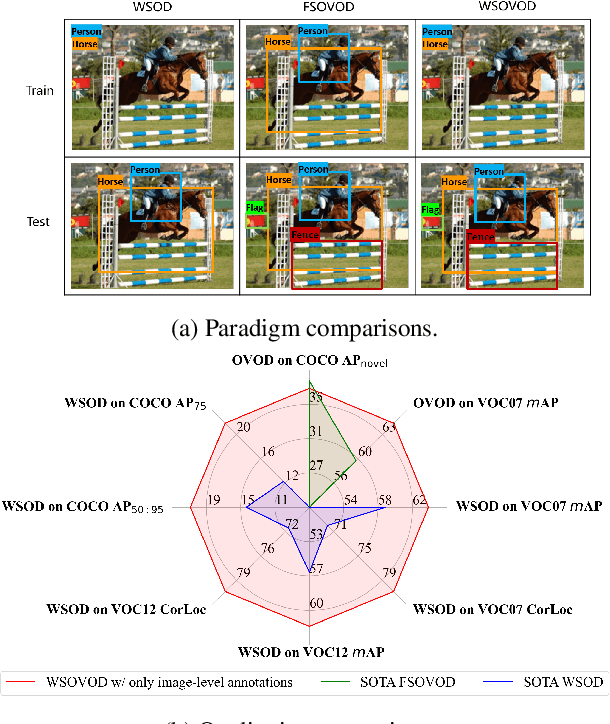

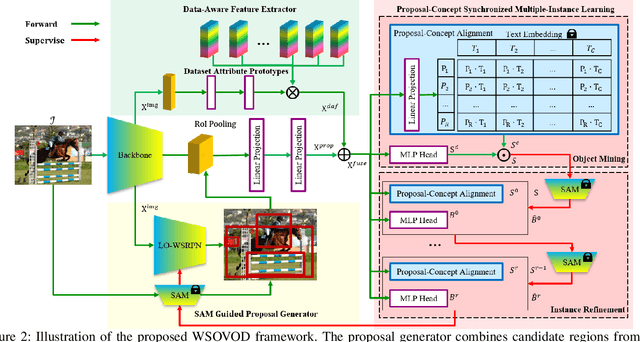

Despite weakly supervised object detection (WSOD) being a promising step toward evading strong instance-level annotations, its capability is confined to closed-set categories within a single training dataset. In this paper, we propose a novel weakly supervised open-vocabulary object detection framework, namely WSOVOD, to extend traditional WSOD to detect novel concepts and utilize diverse datasets with only image-level annotations. To achieve this, we explore three vital strategies, including dataset-level feature adaptation, image-level salient object localization, and region-level vision-language alignment. First, we perform data-aware feature extraction to produce an input-conditional coefficient, which is leveraged into dataset attribute prototypes to identify dataset bias and help achieve cross-dataset generalization. Second, a customized location-oriented weakly supervised region proposal network is proposed to utilize high-level semantic layouts from the category-agnostic segment anything model to distinguish object boundaries. Lastly, we introduce a proposal-concept synchronized multiple-instance network, i.e., object mining and refinement with visual-semantic alignment, to discover objects matched to the text embeddings of concepts. Extensive experiments on Pascal VOC and MS COCO demonstrate that the proposed WSOVOD achieves new state-of-the-art compared with previous WSOD methods in both close-set object localization and detection tasks. Meanwhile, WSOVOD enables cross-dataset and open-vocabulary learning to achieve on-par or even better performance than well-established fully-supervised open-vocabulary object detection (FSOVOD).