 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-DRES: Detailed 3D Referring Expression Segmentation
Mar 03, 2026Current 3D visual grounding tasks only process sentence level detection or segmentation, which critically fails to leverage the rich compositional contextual reasonings within natural language expressions. To address this challenge, we introduce Detailed 3D Referring Expression Segmentation (3D-DRES), a new task that provides a phrase to 3D instance mapping, aiming at enhancing fine-grained 3D vision language understanding. To support 3D-DRES, we present DetailRefer, a new dataset comprising 54,432 descriptions spanning 11,054 distinct objects. Unlike previous datasets, DetailRefer implements a pioneering phrase-instance annotation paradigm where each referenced noun phrase is explicitly mapped to its corresponding 3D elements. Additionally, we introduce DetailBase, a purposefully streamlined yet effective baseline architecture that supports dual-mode segmentation at both sentence and phrase levels. Our experimental results demonstrate that models trained on DetailRefer not only excel at phrase-level segmentation but also show surprising improvements on traditional 3D-RES benchmarks.
MVGGT: Multimodal Visual Geometry Grounded Transformer for Multiview 3D Referring Expression Segmentation
Jan 13, 2026Most existing 3D referring expression segmentation (3DRES) methods rely on dense, high-quality point clouds, while real-world agents such as robots and mobile phones operate with only a few sparse RGB views and strict latency constraints. We introduce Multi-view 3D Referring Expression Segmentation (MV-3DRES), where the model must recover scene structure and segment the referred object directly from sparse multi-view images. Traditional two-stage pipelines, which first reconstruct a point cloud and then perform segmentation, often yield low-quality geometry, produce coarse or degraded target regions, and run slowly. We propose the Multimodal Visual Geometry Grounded Transformer (MVGGT), an efficient end-to-end framework that integrates language information into sparse-view geometric reasoning through a dual-branch design. Training in this setting exposes a critical optimization barrier, termed Foreground Gradient Dilution (FGD), where sparse 3D signals lead to weak supervision. To resolve this, we introduce Per-view No-target Suppression Optimization (PVSO), which provides stronger and more balanced gradients across views, enabling stable and efficient learning. To support consistent evaluation, we build MVRefer, a benchmark that defines standardized settings and metrics for MV-3DRES. Experiments show that MVGGT establishes the first strong baseline and achieves both high accuracy and fast inference, outperforming existing alternatives. Code and models are publicly available at https://mvggt.github.io.
IPDN: Image-enhanced Prompt Decoding Network for 3D Referring Expression Segmentation
Jan 09, 2025



3D Referring Expression Segmentation (3D-RES) aims to segment point cloud scenes based on a given expression. However, existing 3D-RES approaches face two major challenges: feature ambiguity and intent ambiguity. Feature ambiguity arises from information loss or distortion during point cloud acquisition due to limitations such as lighting and viewpoint. Intent ambiguity refers to the model's equal treatment of all queries during the decoding process, lacking top-down task-specific guidance. In this paper, we introduce an Image enhanced Prompt Decoding Network (IPDN), which leverages multi-view images and task-driven information to enhance the model's reasoning capabilities. To address feature ambiguity, we propose the Multi-view Semantic Embedding (MSE) module, which injects multi-view 2D image information into the 3D scene and compensates for potential spatial information loss. To tackle intent ambiguity, we designed a Prompt-Aware Decoder (PAD) that guides the decoding process by deriving task-driven signals from the interaction between the expression and visual features. Comprehensive experiments demonstrate that IPDN outperforms the state-ofthe-art by 1.9 and 4.2 points in mIoU metrics on the 3D-RES and 3D-GRES tasks, respectively.
RG-SAN: Rule-Guided Spatial Awareness Network for End-to-End 3D Referring Expression Segmentation
Dec 03, 2024



3D Referring Expression Segmentation (3D-RES) aims to segment 3D objects by correlating referring expressions with point clouds. However, traditional approaches frequently encounter issues like over-segmentation or mis-segmentation, due to insufficient emphasis on spatial information of instances. In this paper, we introduce a Rule-Guided Spatial Awareness Network (RG-SAN) by utilizing solely the spatial information of the target instance for supervision. This approach enables the network to accurately depict the spatial relationships among all entities described in the text, thus enhancing the reasoning capabilities. The RG-SAN consists of the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS) strategy. The TLM initially locates all mentioned instances and iteratively refines their positional information. The RWS strategy, acknowledging that only target objects have supervised positional information, employs dependency tree rules to precisely guide the core instance's positioning. Extensive testing on the ScanRefer benchmark has shown that RG-SAN not only establishes new performance benchmarks, with an mIoU increase of 5.1 points, but also exhibits significant improvements in robustness when processing descriptions with spatial ambiguity. All codes are available at https://github.com/sosppxo/RG-SAN.
3D-GRES: Generalized 3D Referring Expression Segmentation
Jul 31, 2024


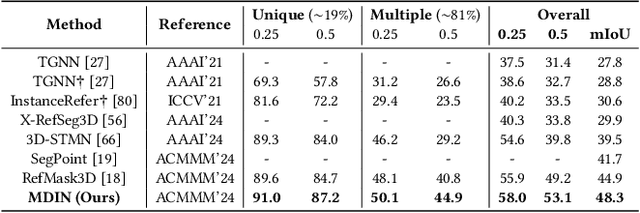
3D Referring Expression Segmentation (3D-RES) is dedicated to segmenting a specific instance within a 3D space based on a natural language description. However, current approaches are limited to segmenting a single target, restricting the versatility of the task. To overcome this limitation, we introduce Generalized 3D Referring Expression Segmentation (3D-GRES), which extends the capability to segment any number of instances based on natural language instructions. In addressing this broader task, we propose the Multi-Query Decoupled Interaction Network (MDIN), designed to break down multi-object segmentation tasks into simpler, individual segmentations. MDIN comprises two fundamental components: Text-driven Sparse Queries (TSQ) and Multi-object Decoupling Optimization (MDO). TSQ generates sparse point cloud features distributed over key targets as the initialization for queries. Meanwhile, MDO is tasked with assigning each target in multi-object scenarios to different queries while maintaining their semantic consistency. To adapt to this new task, we build a new dataset, namely Multi3DRes. Our comprehensive evaluations on this dataset demonstrate substantial enhancements over existing models, thus charting a new path for intricate multi-object 3D scene comprehension. The benchmark and code are available at https://github.com/sosppxo/MDIN.
JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues
Oct 20, 2023The rising importance of 3D representation learning, pivotal in computer vision, autonomous driving, and robotics, is evident. However, a prevailing trend, which straightforwardly resorted to transferring 2D alignment strategies to the 3D domain, encounters three distinct challenges: (1) Information Degradation: This arises from the alignment of 3D data with mere single-view 2D images and generic texts, neglecting the need for multi-view images and detailed subcategory texts. (2) Insufficient Synergy: These strategies align 3D representations to image and text features individually, hampering the overall optimization for 3D models. (3) Underutilization: The fine-grained information inherent in the learned representations is often not fully exploited, indicating a potential loss in detail. To address these issues, we introduce JM3D, a comprehensive approach integrating point cloud, text, and image. Key contributions include the Structured Multimodal Organizer (SMO), enriching vision-language representation with multiple views and hierarchical text, and the Joint Multi-modal Alignment (JMA), combining language understanding with visual representation. Our advanced model, JM3D-LLM, marries 3D representation with large language models via efficient fine-tuning. Evaluations on ModelNet40 and ScanObjectNN establish JM3D's superiority. The superior performance of JM3D-LLM further underscores the effectiveness of our representation transfer approach. Our code and models are available at https://github.com/Mr-Neko/JM3D.
3D-STMN: Dependency-Driven Superpoint-Text Matching Network for End-to-End 3D Referring Expression Segmentation
Aug 31, 2023



In 3D Referring Expression Segmentation (3D-RES), the earlier approach adopts a two-stage paradigm, extracting segmentation proposals and then matching them with referring expressions. However, this conventional paradigm encounters significant challenges, most notably in terms of the generation of lackluster initial proposals and a pronounced deceleration in inference speed. Recognizing these limitations, we introduce an innovative end-to-end Superpoint-Text Matching Network (3D-STMN) that is enriched by dependency-driven insights. One of the keystones of our model is the Superpoint-Text Matching (STM) mechanism. Unlike traditional methods that navigate through instance proposals, STM directly correlates linguistic indications with their respective superpoints, clusters of semantically related points. This architectural decision empowers our model to efficiently harness cross-modal semantic relationships, primarily leveraging densely annotated superpoint-text pairs, as opposed to the more sparse instance-text pairs. In pursuit of enhancing the role of text in guiding the segmentation process, we further incorporate the Dependency-Driven Interaction (DDI) module to deepen the network's semantic comprehension of referring expressions. Using the dependency trees as a beacon, this module discerns the intricate relationships between primary terms and their associated descriptors in expressions, thereby elevating both the localization and segmentation capacities of our model. Comprehensive experiments on the ScanRefer benchmark reveal that our model not only set new performance standards, registering an mIoU gain of 11.7 points but also achieve a staggering enhancement in inference speed, surpassing traditional methods by 95.7 times. The code and models are available at https://github.com/sosppxo/3D-STMN.