 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealDPO: Real or Not Real, that is the Preference
Oct 16, 2025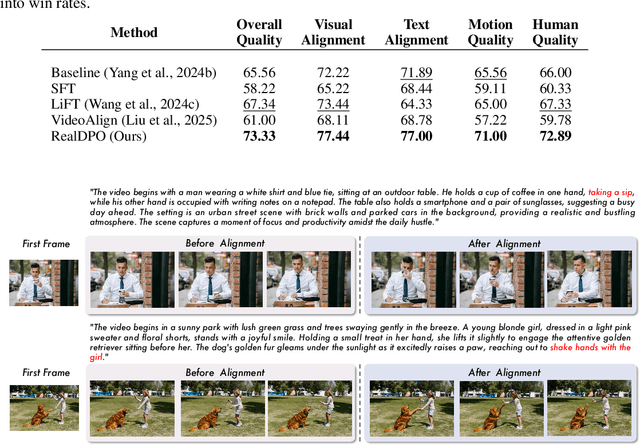

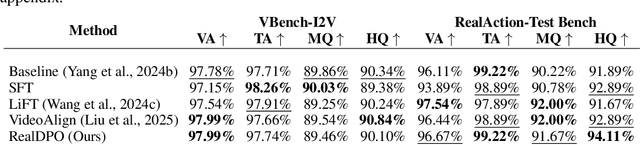
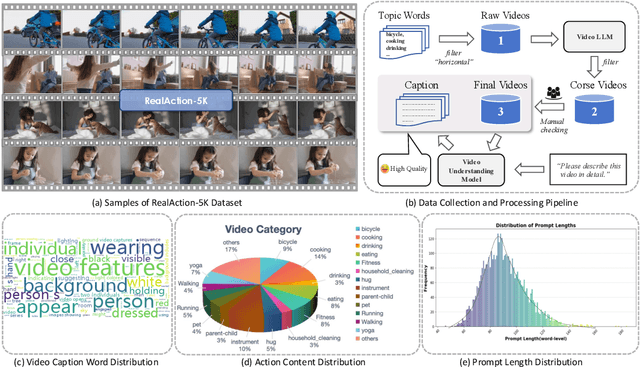
Video generative models have recently achieved notable advancements in synthesis quality. However, generating complex motions remains a critical challenge, as existing models often struggle to produce natural, smooth, and contextually consistent movements. This gap between generated and real-world motions limits their practical applicability. To address this issue, we introduce RealDPO, a novel alignment paradigm that leverages real-world data as positive samples for preference learning, enabling more accurate motion synthesis. Unlike traditional supervised fine-tuning (SFT), which offers limited corrective feedback, RealDPO employs Direct Preference Optimization (DPO) with a tailored loss function to enhance motion realism. By contrasting real-world videos with erroneous model outputs, RealDPO enables iterative self-correction, progressively refining motion quality. To support post-training in complex motion synthesis, we propose RealAction-5K, a curated dataset of high-quality videos capturing human daily activities with rich and precise motion details. Extensive experiments demonstrate that RealDPO significantly improves video quality, text alignment, and motion realism compared to state-of-the-art models and existing preference optimization techniques.
IPDN: Image-enhanced Prompt Decoding Network for 3D Referring Expression Segmentation
Jan 09, 2025



3D Referring Expression Segmentation (3D-RES) aims to segment point cloud scenes based on a given expression. However, existing 3D-RES approaches face two major challenges: feature ambiguity and intent ambiguity. Feature ambiguity arises from information loss or distortion during point cloud acquisition due to limitations such as lighting and viewpoint. Intent ambiguity refers to the model's equal treatment of all queries during the decoding process, lacking top-down task-specific guidance. In this paper, we introduce an Image enhanced Prompt Decoding Network (IPDN), which leverages multi-view images and task-driven information to enhance the model's reasoning capabilities. To address feature ambiguity, we propose the Multi-view Semantic Embedding (MSE) module, which injects multi-view 2D image information into the 3D scene and compensates for potential spatial information loss. To tackle intent ambiguity, we designed a Prompt-Aware Decoder (PAD) that guides the decoding process by deriving task-driven signals from the interaction between the expression and visual features. Comprehensive experiments demonstrate that IPDN outperforms the state-ofthe-art by 1.9 and 4.2 points in mIoU metrics on the 3D-RES and 3D-GRES tasks, respectively.
Exploring Phrase-Level Grounding with Text-to-Image Diffusion Model
Jul 07, 2024Recently, diffusion models have increasingly demonstrated their capabilities in vision understanding. By leveraging prompt-based learning to construct sentences, these models have shown proficiency in classification and visual grounding tasks. However, existing approaches primarily showcase their ability to perform sentence-level localization, leaving the potential for leveraging contextual information for phrase-level understanding largely unexplored. In this paper, we utilize Panoptic Narrative Grounding (PNG) as a proxy task to investigate this capability further. PNG aims to segment object instances mentioned by multiple noun phrases within a given narrative text. Specifically, we introduce the DiffPNG framework, a straightforward yet effective approach that fully capitalizes on the diffusion's architecture for segmentation by decomposing the process into a sequence of localization, segmentation, and refinement steps. The framework initially identifies anchor points using cross-attention mechanisms and subsequently performs segmentation with self-attention to achieve zero-shot PNG. Moreover, we introduce a refinement module based on SAM to enhance the quality of the segmentation masks. Our extensive experiments on the PNG dataset demonstrate that DiffPNG achieves strong performance in the zero-shot PNG task setting, conclusively proving the diffusion model's capability for context-aware, phrase-level understanding. Source code is available at \url{https://github.com/nini0919/DiffPNG}.
SAM as the Guide: Mastering Pseudo-Label Refinement in Semi-Supervised Referring Expression Segmentation
Jun 03, 2024

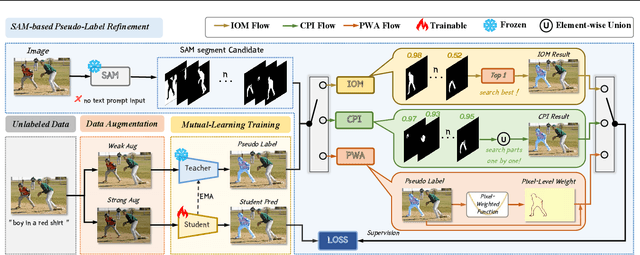

In this paper, we introduce SemiRES, a semi-supervised framework that effectively leverages a combination of labeled and unlabeled data to perform RES. A significant hurdle in applying semi-supervised techniques to RES is the prevalence of noisy pseudo-labels, particularly at the boundaries of objects. SemiRES incorporates the Segment Anything Model (SAM), renowned for its precise boundary demarcation, to improve the accuracy of these pseudo-labels. Within SemiRES, we offer two alternative matching strategies: IoU-based Optimal Matching (IOM) and Composite Parts Integration (CPI). These strategies are designed to extract the most accurate masks from SAM's output, thus guiding the training of the student model with enhanced precision. In instances where a precise mask cannot be matched from the available candidates, we develop the Pixel-Wise Adjustment (PWA) strategy, guiding the student model's training directly by the pseudo-labels. Extensive experiments on three RES benchmarks--RefCOCO, RefCOCO+, and G-Ref reveal its superior performance compared to fully supervised methods. Remarkably, with only 1% labeled data, our SemiRES outperforms the supervised baseline by a large margin, e.g. +18.64% gains on RefCOCO val set. The project code is available at \url{https://github.com/nini0919/SemiRES}.
Semi-Supervised Panoptic Narrative Grounding
Oct 27, 2023
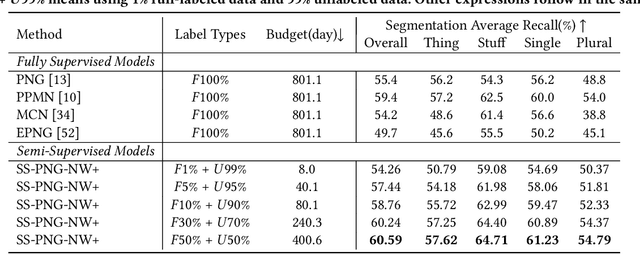


Despite considerable progress, the advancement of Panoptic Narrative Grounding (PNG) remains hindered by costly annotations. In this paper, we introduce a novel Semi-Supervised Panoptic Narrative Grounding (SS-PNG) learning scheme, capitalizing on a smaller set of labeled image-text pairs and a larger set of unlabeled pairs to achieve competitive performance. Unlike visual segmentation tasks, PNG involves one pixel belonging to multiple open-ended nouns. As a result, existing multi-class based semi-supervised segmentation frameworks cannot be directly applied to this task. To address this challenge, we first develop a novel SS-PNG Network (SS-PNG-NW) tailored to the SS-PNG setting. We thoroughly investigate strategies such as Burn-In and data augmentation to determine the optimal generic configuration for the SS-PNG-NW. Additionally, to tackle the issue of imbalanced pseudo-label quality, we propose a Quality-Based Loss Adjustment (QLA) approach to adjust the semi-supervised objective, resulting in an enhanced SS-PNG-NW+. Employing our proposed QLA, we improve BCE Loss and Dice loss at pixel and mask levels, respectively. We conduct extensive experiments on PNG datasets, with our SS-PNG-NW+ demonstrating promising results comparable to fully-supervised models across all data ratios. Remarkably, our SS-PNG-NW+ outperforms fully-supervised models with only 30% and 50% supervision data, exceeding their performance by 0.8% and 1.1% respectively. This highlights the effectiveness of our proposed SS-PNG-NW+ in overcoming the challenges posed by limited annotations and enhancing the applicability of PNG tasks. The source code is available at https://github.com/nini0919/SSPNG.
Asynchronous Federated Learning with Incentive Mechanism Based on Contract Theory
Oct 10, 2023



To address the challenges posed by the heterogeneity inherent in federated learning (FL) and to attract high-quality clients, various incentive mechanisms have been employed. However, existing incentive mechanisms are typically utilized in conventional synchronous aggregation, resulting in significant straggler issues. In this study, we propose a novel asynchronous FL framework that integrates an incentive mechanism based on contract theory. Within the incentive mechanism, we strive to maximize the utility of the task publisher by adaptively adjusting clients' local model training epochs, taking into account factors such as time delay and test accuracy. In the asynchronous scheme, considering client quality, we devise aggregation weights and an access control algorithm to facilitate asynchronous aggregation. Through experiments conducted on the MNIST dataset, the simulation results demonstrate that the test accuracy achieved by our framework is 3.12% and 5.84% higher than that achieved by FedAvg and FedProx without any attacks, respectively. The framework exhibits a 1.35% accuracy improvement over the ideal Local SGD under attacks. Furthermore, aiming for the same target accuracy, our framework demands notably less computation time than both FedAvg and FedProx.