 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Bayesian Learning based Joint Localization and Channel Estimation with Distance-dependent Noise
Mar 07, 2024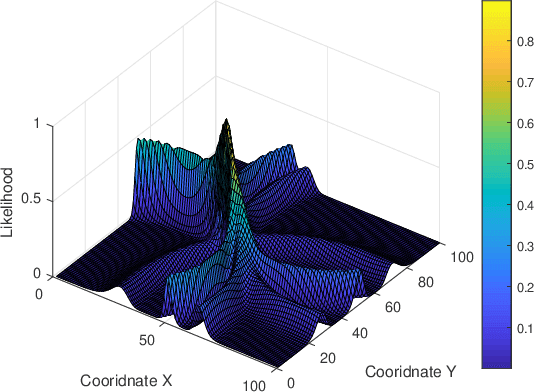
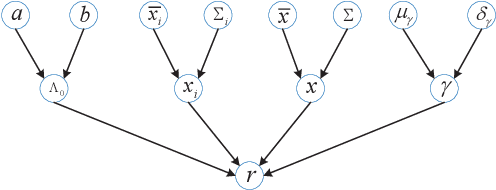
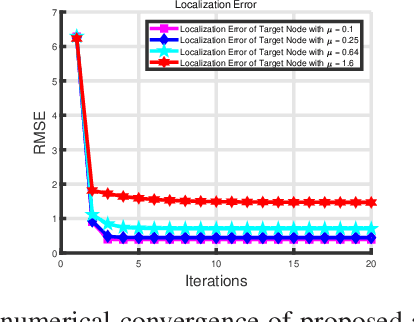
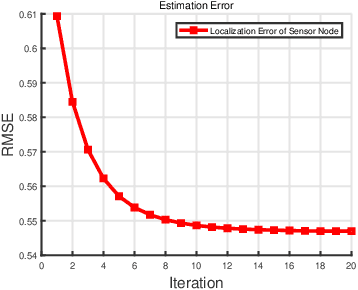
In the Industrial Internet of Things (IIoTs) and Ocean of Things (OoTs), the advent of massive intelligent services has imposed stringent requirements on both communication and localization, particularly emphasizing precise localization and channel information. This paper focuses on the challenge of jointly optimizing localization and communication in IoT networks. Departing from the conventional independent noise model used in localization and channel estimation problems, we consider a more realistic model incorporating distance-dependent noise variance, as revealed in recent theoretical analyses and experimental results. The distance-dependent noise introduces unknown noise power and a complex noise model, resulting in an exceptionally challenging non-convex and nonlinear optimization problem. In this study, we address a joint localization and channel estimation problem encompassing distance-dependent noise, unknown channel parameters, and uncertainties in sensor node locations. To surmount the intractable nonlinear and non-convex objective function inherent in the problem, we introduce a variational Bayesian learning-based framework. This framework enables the joint optimization of localization and channel parameters by leveraging an effective approximation to the true posterior distribution. Furthermore, the proposed joint learning algorithm provides an iterative closed-form solution and exhibits superior performance in terms of computational complexity compared to existing algorithms. Computer simulation results demonstrate that the proposed algorithm approaches the performance of the Bayesian Cramer-Rao bound (BCRB), achieves localization performance comparable to the ML-GMP algorithm, and outperforms the other two comparison algorithms.
Variational Bayesian Learning Based Localization and Channel Reconstruction in RIS-aided Systems
Mar 02, 2024



The emerging immersive and autonomous services have posed stringent requirements on both communications and localization. By considering the great potential of reconfigurable intelligent surface (RIS), this paper focuses on the joint channel estimation and localization for RIS-aided wireless systems. As opposed to existing works that treat channel estimation and localization independently, this paper exploits the intrinsic coupling and nonlinear relationships between the channel parameters and user location for enhancement of both localization and channel reconstruction. By noticing the non-convex, nonlinear objective function and the sparser angle pattern, a variational Bayesian learning-based framework is developed to jointly estimate the channel parameters and user location through leveraging an effective approximation of the posterior distribution. The proposed framework is capable of unifying near-field and far-field scenarios owing to exploitation of sparsity of the angular domain. Since the joint channel and location estimation problem has a closed-form solution in each iteration, our proposed iterative algorithm performs better than the conventional particle swarm optimization (PSO) and maximum likelihood (ML) based ones in terms of computational complexity. Simulations demonstrate that the proposed algorithm almost reaches the Bayesian Cramer-Rao bound (BCRB) and achieves a superior estimation accuracy by comparing to the PSO and the ML algorithms.
Bi-directional Masks for Efficient N:M Sparse Training
Feb 13, 2023We focus on addressing the dense backward propagation issue for training efficiency of N:M fine-grained sparsity that preserves at most N out of M consecutive weights and achieves practical speedups supported by the N:M sparse tensor core. Therefore, we present a novel method of Bi-directional Masks (Bi-Mask) with its two central innovations in: 1) Separate sparse masks in the two directions of forward and backward propagation to obtain training acceleration. It disentangles the forward and backward weight sparsity and overcomes the very dense gradient computation. 2) An efficient weight row permutation method to maintain performance. It picks up the permutation candidate with the most eligible N:M weight blocks in the backward to minimize the gradient gap between traditional uni-directional masks and our bi-directional masks. Compared with existing uni-directional scenario that applies a transposable mask and enables backward acceleration, our Bi-Mask is experimentally demonstrated to be more superior in performance. Also, our Bi-Mask performs on par with or even better than methods that fail to achieve backward acceleration. Project of this paper is available at \url{https://github.com/zyxxmu/Bi-Mask}.
Learning Best Combination for Efficient N:M Sparsity
Jun 14, 2022



By forcing at most N out of M consecutive weights to be non-zero, the recent N:M network sparsity has received increasing attention for its two attractive advantages: 1) Promising performance at a high sparsity. 2) Significant speedups on NVIDIA A100 GPUs. Recent studies require an expensive pre-training phase or a heavy dense-gradient computation. In this paper, we show that the N:M learning can be naturally characterized as a combinatorial problem which searches for the best combination candidate within a finite collection. Motivated by this characteristic, we solve N:M sparsity in an efficient divide-and-conquer manner. First, we divide the weight vector into $C_{\text{M}}^{\text{N}}$ combination subsets of a fixed size N. Then, we conquer the combinatorial problem by assigning each combination a learnable score that is jointly optimized with its associate weights. We prove that the introduced scoring mechanism can well model the relative importance between combination subsets. And by gradually removing low-scored subsets, N:M fine-grained sparsity can be efficiently optimized during the normal training phase. Comprehensive experiments demonstrate that our learning best combination (LBC) performs consistently better than off-the-shelf N:M sparsity methods across various networks. Our code is released at \url{https://github.com/zyxxmu/LBC}.