 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Layers of Aligned Large Language Models: The Key to LLM Security
Paper and Code
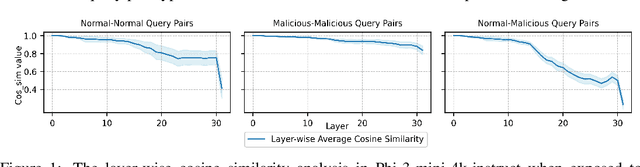



Aligned LLMs are highly secure, capable of recognizing and refusing to answer malicious questions. However, the role of internal parameters in maintaining this security is not well understood, further these models are vulnerable to security degradation when fine-tuned with non-malicious backdoor data or normal data. To address these challenges, our work uncovers the mechanism behind security in aligned LLMs at the parameter level, identifying a small set of contiguous layers in the middle of the model that are crucial for distinguishing malicious queries from normal ones, referred to as "safety layers." We first confirm the existence of these safety layers by analyzing variations in input vectors within the model's internal layers. Additionally, we leverage the over-rejection phenomenon and parameters scaling analysis to precisely locate the safety layers. Building on this understanding, we propose a novel fine-tuning approach, Safely Partial-Parameter Fine-Tuning (SPPFT), that fixes the gradient of the safety layers during fine-tuning to address the security degradation. Our experiments demonstrate that this approach significantly preserves model security while maintaining performance and reducing computational resources compared to full fine-tuning.