 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Synergy of Speculative Decoding and Batching in Serving Large Language Models
Paper and Code
Oct 28, 2023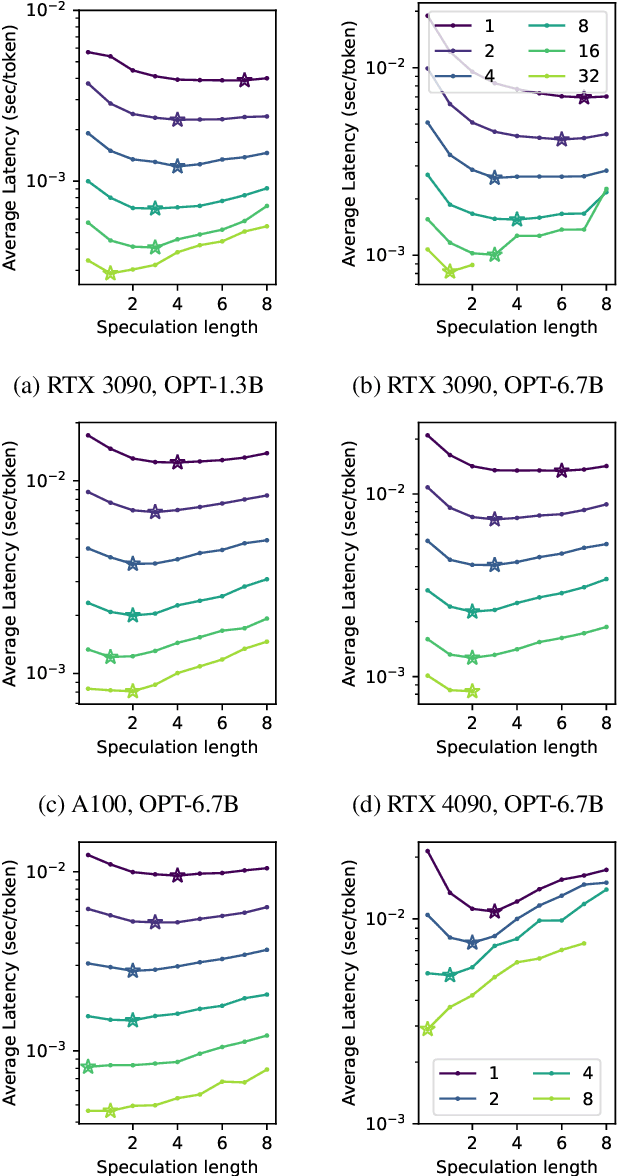
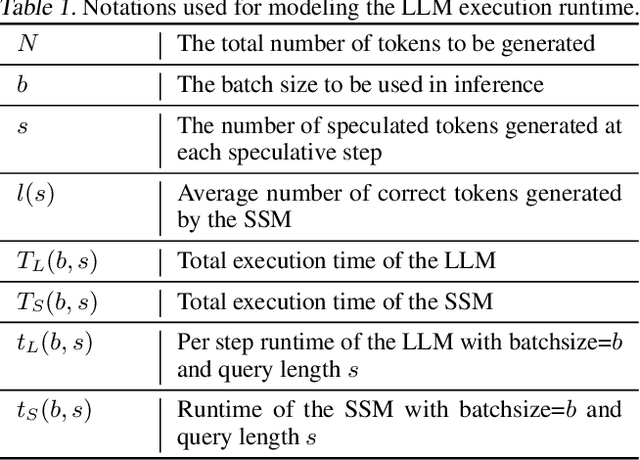
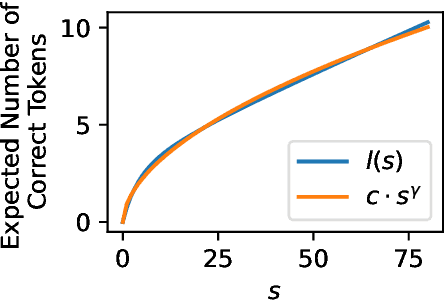
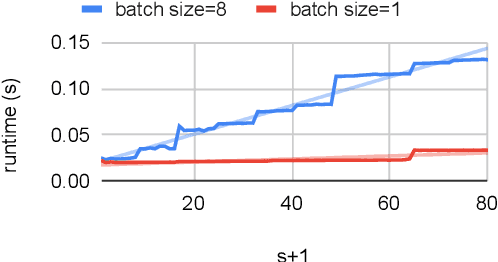
Large Language Models (LLMs) like GPT are state-of-the-art text generation models that provide significant assistance in daily routines. However, LLM execution is inherently sequential, since they only produce one token at a time, thus incurring low hardware utilization on modern GPUs. Batching and speculative decoding are two techniques to improve GPU hardware utilization in LLM inference. To study their synergy, we implement a prototype implementation and perform an extensive characterization analysis on various LLM models and GPU architectures. We observe that the optimal speculation length depends on the batch size used. We analyze the key observation and build a quantitative model to explain it. Based on our analysis, we propose a new adaptive speculative decoding strategy that chooses the optimal speculation length for different batch sizes. Our evaluations show that our proposed method can achieve equal or better performance than the state-of-the-art speculation decoding schemes with fixed speculation length.