 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistDGL: Distributed Graph Neural Network Training for Billion-Scale Graphs
Paper and Code
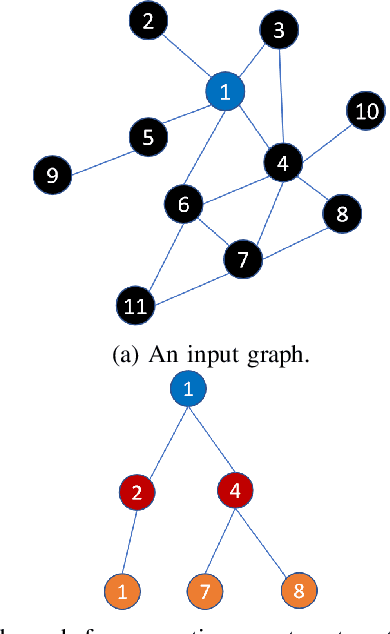
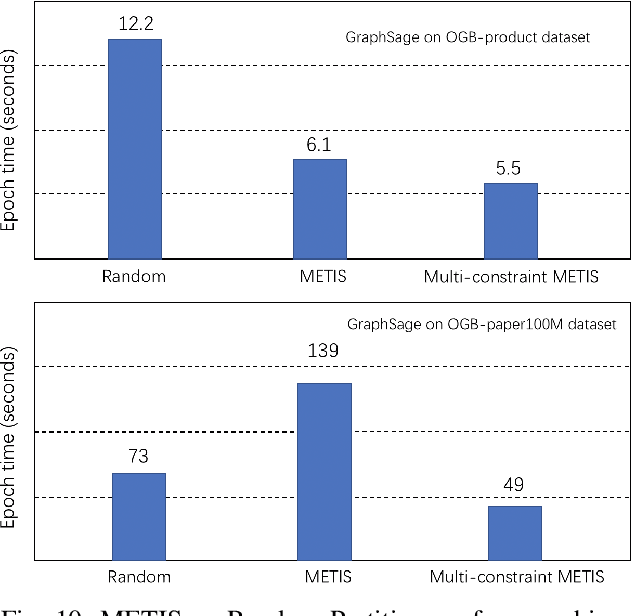
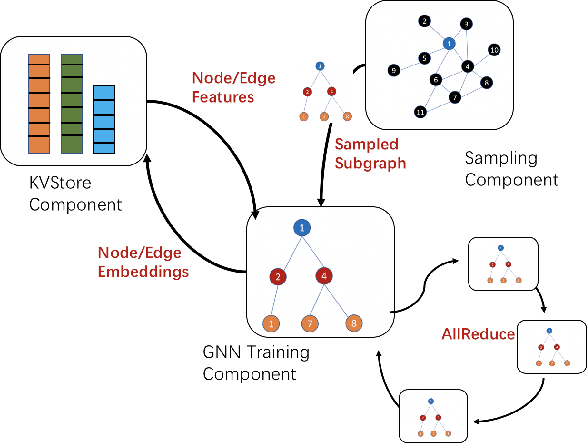
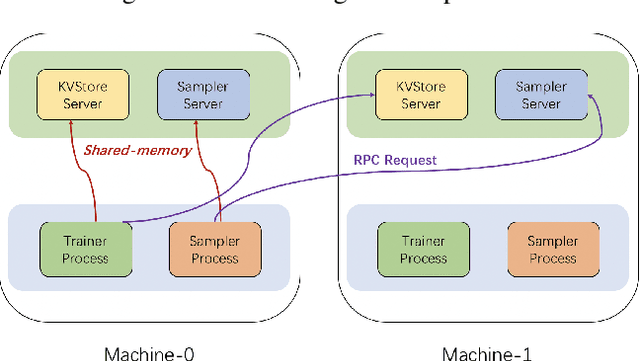
Graph neural networks (GNN) have shown great success in learning from graph-structured data. They are widely used in various applications, such as recommendation, fraud detection, and search. In these domains, the graphs are typically large, containing hundreds of millions of nodes and several billions of edges. To tackle this challenge, we develop DistDGL, a system for training GNNs in a mini-batch fashion on a cluster of machines. DistDGL is based on the Deep Graph Library (DGL), a popular GNN development framework. DistDGL distributes the graph and its associated data (initial features and embeddings) across the machines and uses this distribution to derive a computational decomposition by following an owner-compute rule. DistDGL follows a synchronous training approach and allows ego-networks forming the mini-batches to include non-local nodes. To minimize the overheads associated with distributed computations, DistDGL uses a high-quality and light-weight min-cut graph partitioning algorithm along with multiple balancing constraints. This allows it to reduce communication overheads and statically balance the computations. It further reduces the communication by replicating halo nodes and by using sparse embedding updates. The combination of these design choices allows DistDGL to train high-quality models while achieving high parallel efficiency and memory scalability. We demonstrate our optimizations on both inductive and transductive GNN models. Our results show that DistDGL achieves linear speedup without compromising model accuracy and requires only 13 seconds to complete a training epoch for a graph with 100 million nodes and 3 billion edges on a cluster with 16 machines.