 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr$^2$Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient Finetuning
Paper and Code
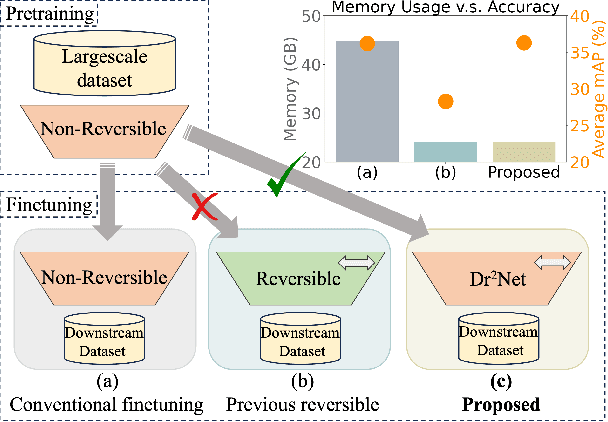

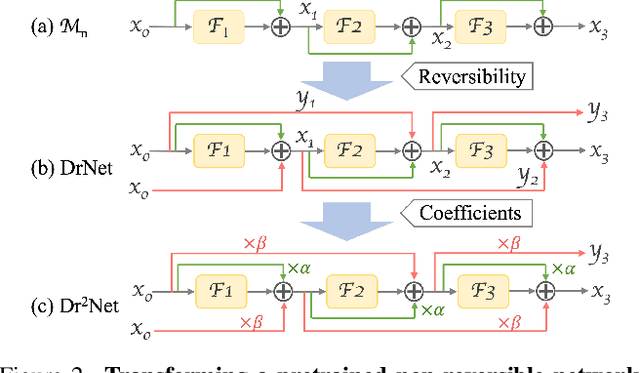
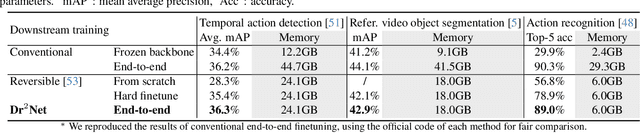
Large pretrained models are increasingly crucial in modern computer vision tasks. These models are typically used in downstream tasks by end-to-end finetuning, which is highly memory-intensive for tasks with high-resolution data, e.g., video understanding, small object detection, and point cloud analysis. In this paper, we propose Dynamic Reversible Dual-Residual Networks, or Dr$^2$Net, a novel family of network architectures that acts as a surrogate network to finetune a pretrained model with substantially reduced memory consumption. Dr$^2$Net contains two types of residual connections, one maintaining the residual structure in the pretrained models, and the other making the network reversible. Due to its reversibility, intermediate activations, which can be reconstructed from output, are cleared from memory during training. We use two coefficients on either type of residual connections respectively, and introduce a dynamic training strategy that seamlessly transitions the pretrained model to a reversible network with much higher numerical precision. We evaluate Dr$^2$Net on various pretrained models and various tasks, and show that it can reach comparable performance to conventional finetuning but with significantly less memory usage.