 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompTLL-UNet: Compressed Domain Text-Line Localization in Challenging Handwritten Documents using Deep Feature Learning from JPEG Coefficients
Aug 11, 2023


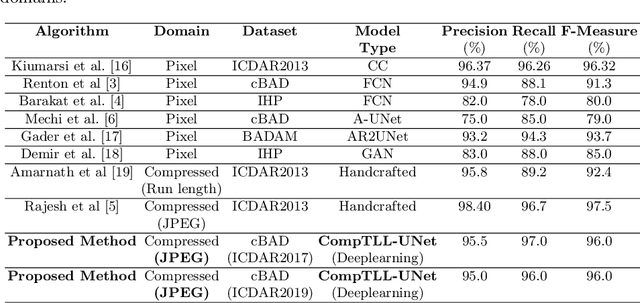
Automatic localization of text-lines in handwritten documents is still an open and challenging research problem. Various writing issues such as uneven spacing between the lines, oscillating and touching text, and the presence of skew become much more challenging when the case of complex handwritten document images are considered for segmentation directly in their respective compressed representation. This is because, the conventional way of processing compressed documents is through decompression, but here in this paper, we propose an idea that employs deep feature learning directly from the JPEG compressed coefficients without full decompression to accomplish text-line localization in the JPEG compressed domain. A modified U-Net architecture known as Compressed Text-Line Localization Network (CompTLL-UNet) is designed to accomplish it. The model is trained and tested with JPEG compressed version of benchmark datasets including ICDAR2017 (cBAD) and ICDAR2019 (cBAD), reporting the state-of-the-art performance with reduced storage and computational costs in the JPEG compressed domain.
T2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network
Oct 01, 2022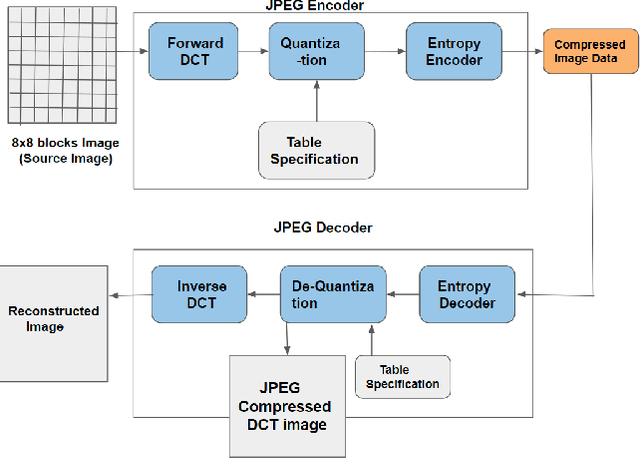

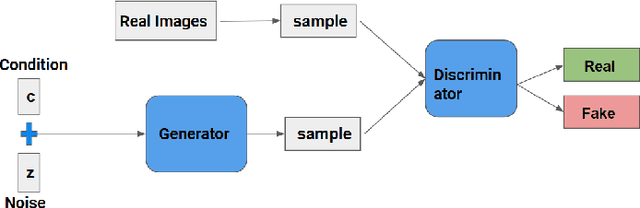

The problem of generating textual descriptions for the visual data has gained research attention in the recent years. In contrast to that the problem of generating visual data from textual descriptions is still very challenging, because it requires the combination of both Natural Language Processing (NLP) and Computer Vision techniques. The existing methods utilize the Generative Adversarial Networks (GANs) and generate the uncompressed images from textual description. However, in practice, most of the visual data are processed and transmitted in the compressed representation. Hence, the proposed work attempts to generate the visual data directly in the compressed representation form using Deep Convolutional GANs (DCGANs) to achieve the storage and computational efficiency. We propose GAN models for compressed image generation from text. The first model is directly trained with JPEG compressed DCT images (compressed domain) to generate the compressed images from text descriptions. The second model is trained with RGB images (pixel domain) to generate JPEG compressed DCT representation from text descriptions. The proposed models are tested on an open source benchmark dataset Oxford-102 Flower images using both RGB and JPEG compressed versions, and accomplished the state-of-the-art performance in the JPEG compressed domain. The code will be publicly released at GitHub after acceptance of paper.
Document Image Binarization in JPEG Compressed Domain using Dual Discriminator Generative Adversarial Networks
Sep 13, 2022

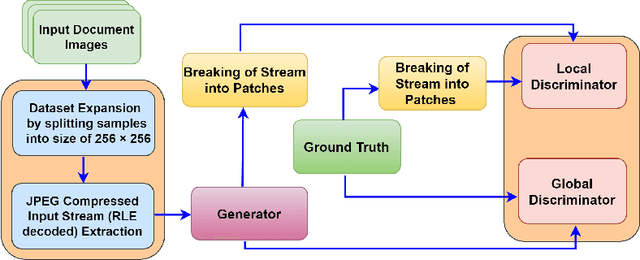

Image binarization techniques are being popularly used in enhancement of noisy and/or degraded images catering different Document Image Anlaysis (DIA) applications like word spotting, document retrieval, and OCR. Most of the existing techniques focus on feeding pixel images into the Convolution Neural Networks to accomplish document binarization, which may not produce effective results when working with compressed images that need to be processed without full decompression. Therefore in this research paper, the idea of document image binarization directly using JPEG compressed stream of document images is proposed by employing Dual Discriminator Generative Adversarial Networks (DD-GANs). Here the two discriminator networks - Global and Local work on different image ratios and use focal loss as generator loss. The proposed model has been thoroughly tested with different versions of DIBCO dataset having challenges like holes, erased or smudged ink, dust, and misplaced fibres. The model proved to be highly robust, efficient both in terms of time and space complexities, and also resulted in state-of-the-art performance in JPEG compressed domain.
HWRCNet: Handwritten Word Recognition in JPEG Compressed Domain using CNN-BiLSTM Network
Jan 08, 2022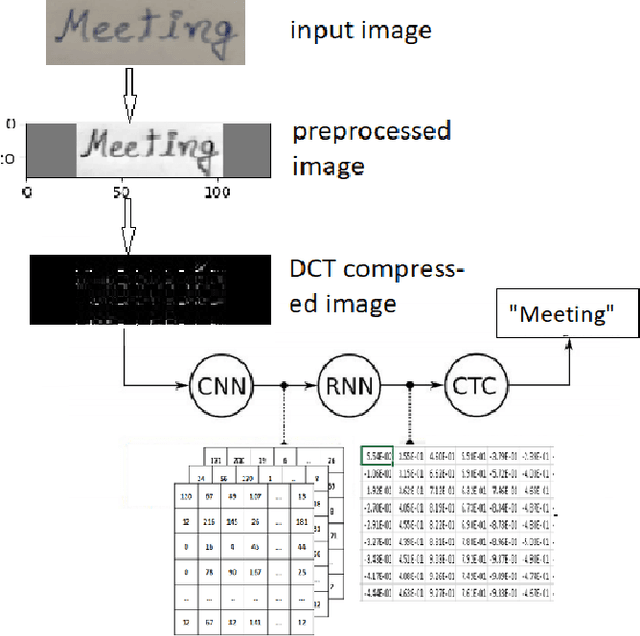
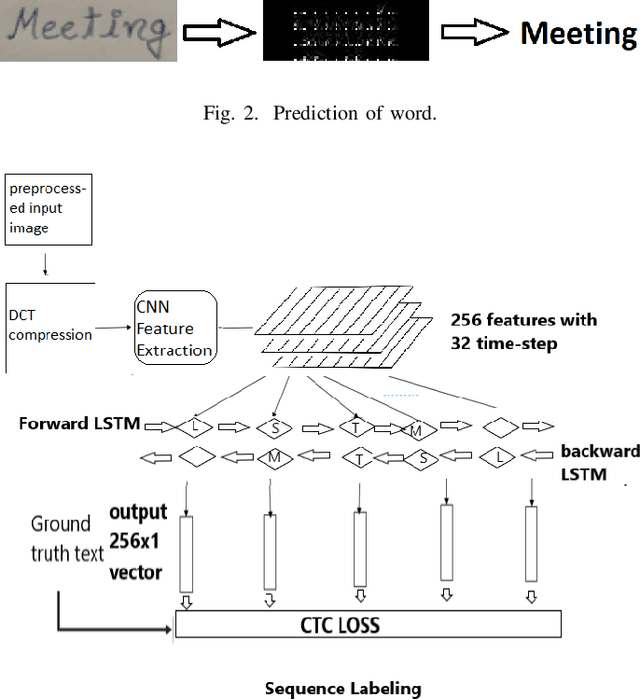
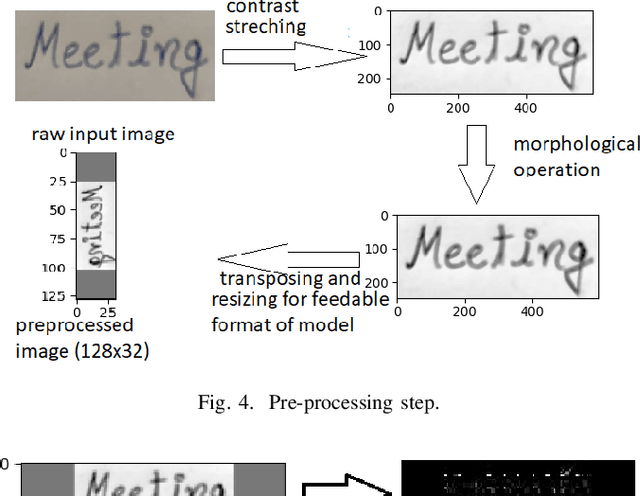
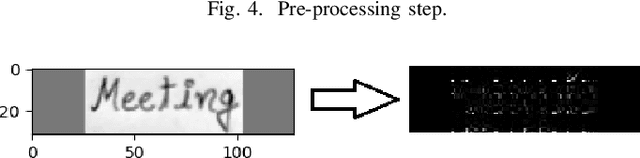
The handwritten word recognition from images using deep learning is an active research area with promising performance. It practical scenario, it might be required to process the handwritten images in the compressed domain due to due to security reasons. However, the utilization of deep learning is still very limited for the processing of compressed images. Motivated by the need of processing document images in the compressed domain using recent developments in deep learning, we propose a HWRCNet model for handwritten word recognition in JPEG compressed domain. The proposed model combines the Convolutional Neural Network (CNN) and Bi-Directional Long Short Term Memory (BiLSTM) based Recurrent Neural Network (RNN). Basically, we train the model using compressed domain images and observe a very appealing performance with 89.05% word recognition accuracy and 13.37% character error rate.
Detection of Plant Leaf Disease Directly in the JPEG Compressed Domain using Transfer Learning Technique
Jul 10, 2021
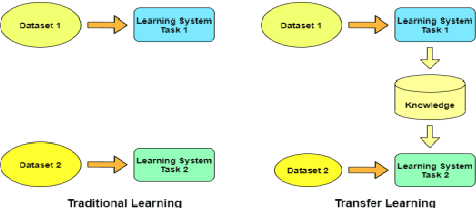
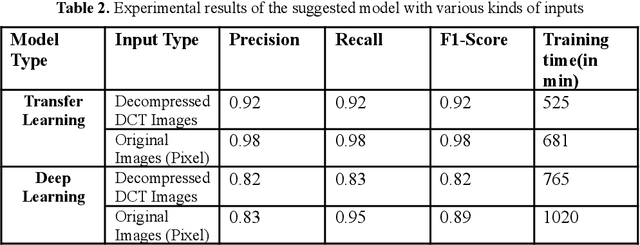
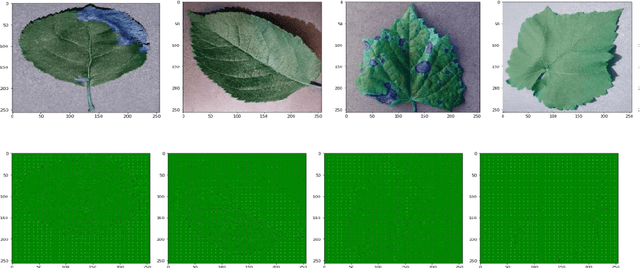
Plant leaf diseases pose a significant danger to food security and they cause depletion in quality and volume of production. Therefore accurate and timely detection of leaf disease is very important to check the loss of the crops and meet the growing food demand of the people. Conventional techniques depend on lab investigation and human skills which are generally costly and inaccessible. Recently, Deep Neural Networks have been exceptionally fruitful in image classification. In this research paper, plant leaf disease detection employing transfer learning is explored in the JPEG compressed domain. Here, the JPEG compressed stream consisting of DCT coefficients is, directly fed into the Neural Network to improve the efficiency of classification. The experimental results on JPEG compressed leaf dataset demonstrate the efficacy of the proposed model.
Deep Learning Based Image Retrieval in the JPEG Compressed Domain
Jul 08, 2021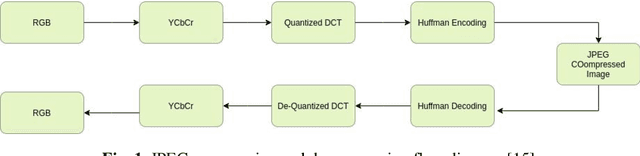

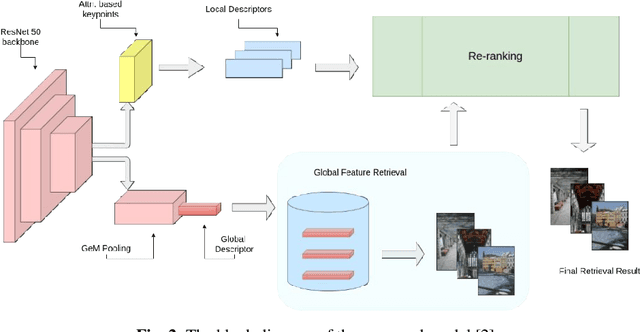

Content-based image retrieval (CBIR) systems on pixel domain use low-level features, such as colour, texture and shape, to retrieve images. In this context, two types of image representations i.e. local and global image features have been studied in the literature. Extracting these features from pixel images and comparing them with images from the database is very time-consuming. Therefore, in recent years, there has been some effort to accomplish image analysis directly in the compressed domain with lesser computations. Furthermore, most of the images in our daily transactions are stored in the JPEG compressed format. Therefore, it would be ideal if we could retrieve features directly from the partially decoded or compressed data and use them for retrieval. Here, we propose a unified model for image retrieval which takes DCT coefficients as input and efficiently extracts global and local features directly in the JPEG compressed domain for accurate image retrieval. The experimental findings indicate that our proposed model performed similarly to the current DELG model which takes RGB features as an input with reference to mean average precision while having a faster training and retrieval speed.
Automatic Text Line Segmentation Directly in JPEG Compressed Document Images
Jul 29, 2019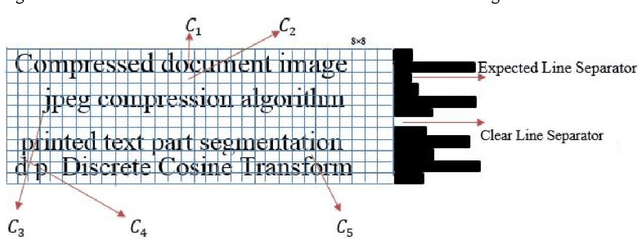
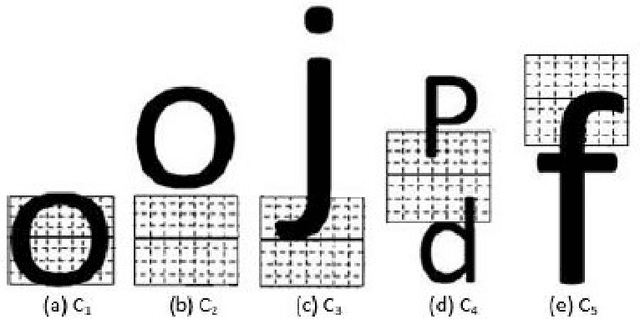


JPEG is one of the popular image compression algorithms that provide efficient storage and transmission capabilities in consumer electronics, and hence it is the most preferred image format over the internet world. In the present digital and Big-data era, a huge volume of JPEG compressed document images are being archived and communicated through consumer electronics on daily basis. Though it is advantageous to have data in the compressed form on one side, however, on the other side processing with off-the-shelf methods becomes computationally expensive because it requires decompression and recompression operations. Therefore, it would be novel and efficient, if the compressed data are processed directly in their respective compressed domains of consumer electronics. In the present research paper, we propose to demonstrate this idea taking the case study of printed text line segmentation. Since, JPEG achieves compression by dividing the image into non overlapping 8x8 blocks in the pixel domain and using Discrete Cosine Transform (DCT); it is very likely that the partitioned 8x8 DCT blocks overlap the contents of two adjacent text-lines without leaving any clue for the line separator, thus making text-line segmentation a challenging problem. Two approaches of segmentation have been proposed here using the DC projection profile and AC coefficients of each 8x8 DCT block. The first approach is based on the strategy of partial decompression of selected DCT blocks, and the second approach is with intelligent analysis of F10 and F11 AC coefficients and without using any type of decompression. The proposed methods have been tested with variable font sizes, font style and spacing between lines, and a good performance is reported.
DCT-CompCNN: A Novel Image Classification Network Using JPEG Compressed DCT Coefficients
Jul 26, 2019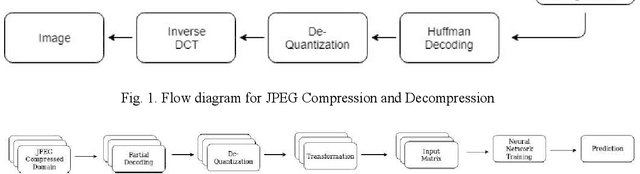
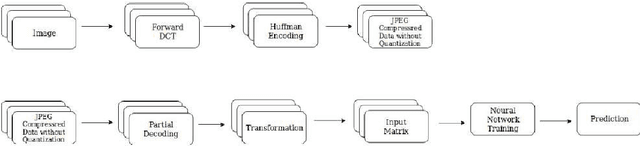
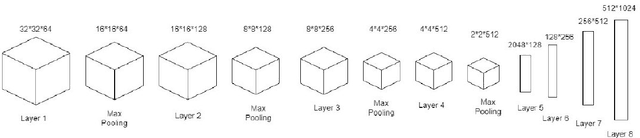
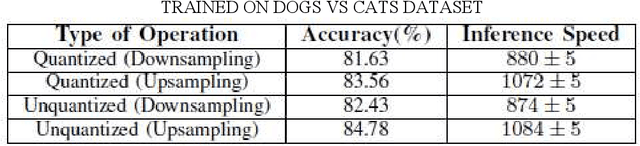
The popularity of Convolutional Neural Network (CNN) in the field of Image Processing and Computer Vision has motivated researchers and industrialist experts across the globe to solve different challenges with high accuracy. The simplest way to train a CNN classifier is to directly feed the original RGB pixels images into the network. However, if we intend to classify images directly with its compressed data, the same approach may not work better, like in case of JPEG compressed images. This research paper investigates the issues of modifying the input representation of the JPEG compressed data, and then feeding into the CNN. The architecture is termed as DCT-CompCNN. This novel approach has shown that CNNs can also be trained with JPEG compressed DCT coefficients, and subsequently can produce a better performance in comparison with the conventional CNN approach. The efficiency of the modified input representation is tested with the existing ResNet-50 architecture and the proposed DCT-CompCNN architecture on a public image classification datasets like Dog Vs Cat and CIFAR-10 datasets, reporting a better performance