 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompTLL-UNet: Compressed Domain Text-Line Localization in Challenging Handwritten Documents using Deep Feature Learning from JPEG Coefficients
Aug 11, 2023


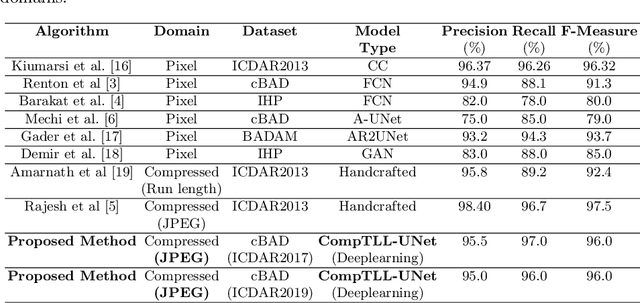
Automatic localization of text-lines in handwritten documents is still an open and challenging research problem. Various writing issues such as uneven spacing between the lines, oscillating and touching text, and the presence of skew become much more challenging when the case of complex handwritten document images are considered for segmentation directly in their respective compressed representation. This is because, the conventional way of processing compressed documents is through decompression, but here in this paper, we propose an idea that employs deep feature learning directly from the JPEG compressed coefficients without full decompression to accomplish text-line localization in the JPEG compressed domain. A modified U-Net architecture known as Compressed Text-Line Localization Network (CompTLL-UNet) is designed to accomplish it. The model is trained and tested with JPEG compressed version of benchmark datasets including ICDAR2017 (cBAD) and ICDAR2019 (cBAD), reporting the state-of-the-art performance with reduced storage and computational costs in the JPEG compressed domain.
DWT-CompCNN: Deep Image Classification Network for High Throughput JPEG 2000 Compressed Documents
Jun 02, 2023For any digital application with document images such as retrieval, the classification of document images becomes an essential stage. Conventionally for the purpose, the full versions of the documents, that is the uncompressed document images make the input dataset, which poses a threat due to the big volume required to accommodate the full versions of the documents. Therefore, it would be novel, if the same classification task could be accomplished directly (with some partial decompression) with the compressed representation of documents in order to make the whole process computationally more efficient. In this research work, a novel deep learning model, DWT CompCNN is proposed for classification of documents that are compressed using High Throughput JPEG 2000 (HTJ2K) algorithm. The proposed DWT-CompCNN comprises of five convolutional layers with filter sizes of 16, 32, 64, 128, and 256 consecutively for each increasing layer to improve learning from the wavelet coefficients extracted from the compressed images. Experiments are performed on two benchmark datasets- Tobacco-3482 and RVL-CDIP, which demonstrate that the proposed model is time and space efficient, and also achieves a better classification accuracy in compressed domain.
T2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network
Oct 01, 2022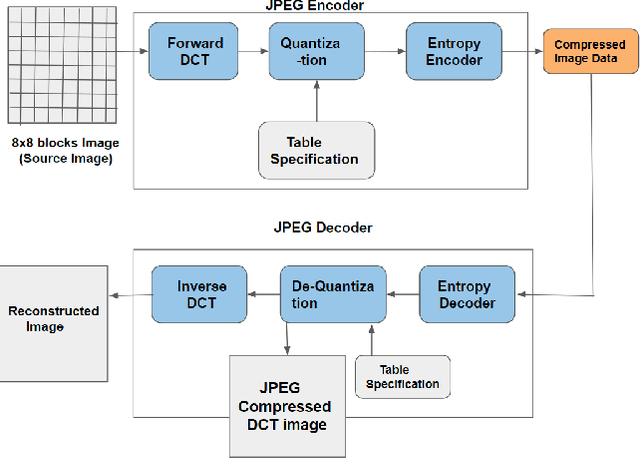


The problem of generating textual descriptions for the visual data has gained research attention in the recent years. In contrast to that the problem of generating visual data from textual descriptions is still very challenging, because it requires the combination of both Natural Language Processing (NLP) and Computer Vision techniques. The existing methods utilize the Generative Adversarial Networks (GANs) and generate the uncompressed images from textual description. However, in practice, most of the visual data are processed and transmitted in the compressed representation. Hence, the proposed work attempts to generate the visual data directly in the compressed representation form using Deep Convolutional GANs (DCGANs) to achieve the storage and computational efficiency. We propose GAN models for compressed image generation from text. The first model is directly trained with JPEG compressed DCT images (compressed domain) to generate the compressed images from text descriptions. The second model is trained with RGB images (pixel domain) to generate JPEG compressed DCT representation from text descriptions. The proposed models are tested on an open source benchmark dataset Oxford-102 Flower images using both RGB and JPEG compressed versions, and accomplished the state-of-the-art performance in the JPEG compressed domain. The code will be publicly released at GitHub after acceptance of paper.
Early-stage COVID-19 diagnosis in presence of limited posteroanterior chest X-ray images via novel Pinball-OCSVM
Oct 16, 2020
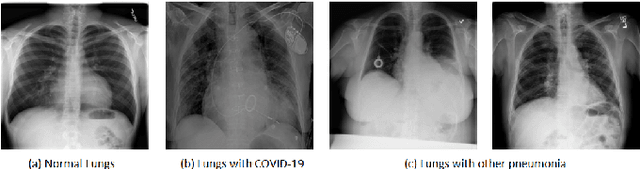


It is evident that the infection with this severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) starts with the upper respiratory tract and as the virus grows, the infection can progress to lungs and develop pneumonia. According to the statistics, approximately 14\% of the infected people with COVID-19 have severe cough and shortness of breath due to pneumonia, because as the viral infection increases, it damages the alveoli (small air sacs) and surrounding tissues. The conventional way of COVID-19 diagnosis is reverse transcription polymerase chain reaction (RT-PCR), which is less sensitive during early stages specially, if the patient is asymptomatic that may further lead to more severe pneumonia. To overcome this problem an early diagnosis method is proposed in this paper via one-class classification approach using a novel pinball loss function based one-class support vector machine (PB-OCSVM) considering posteroanterior chest X-ray images. Recently, several automated COVID-19 diagnosis models have been proposed based on various deep learning architectures to identify pulmonary infections using publicly available chest X-ray (CXR) where the presence of less number of COVID-19 positive samples compared to other classes (normal, pneumonia and Tuberculosis) raises the challenge for unbiased learning in deep learning models that has been solved using class balancing techniques which however should be avoided in any medical diagnosis process. Inspired by this phenomenon, this article proposes a novel PB-OCSVM model to work in presence of limited COVID-19 positive CXR samples with objectives to maximize the learning efficiency while minimize the false-positive and false-negative predictions. The proposed model outperformed over recently published deep learning approaches where accuracy, precision, specificity and sensitivity are used as performance measure parameters.
Depth-wise layering of 3d images using dense depth maps: a threshold based approach
Oct 05, 2020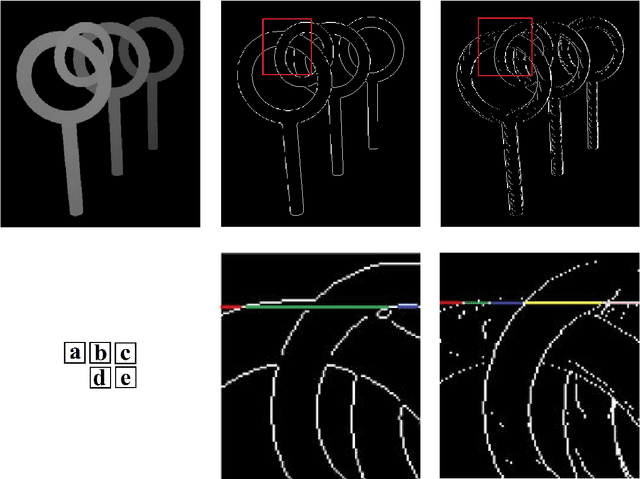
Image segmentation has long been a basic problem in computer vision. Depth-wise Layering is a kind of segmentation that slices an image in a depth-wise sequence unlike the conventional image segmentation problems dealing with surface-wise decomposition. The proposed Depth-wise Layering technique uses a single depth image of a static scene to slice it into multiple layers. The technique employs a thresholding approach to segment rows of the dense depth map into smaller partitions called Line-Segments in this paper. Then, it uses the line-segment labelling method to identify number of objects and layers of the scene independently. The final stage is to link objects of the scene to their respective object-layers. We evaluate the efficiency of the proposed technique by applying that on many images along with their dense depth maps. The experiments have shown promising results of layering.
Automatic Page Segmentation Without Decompressing the Run-Length Compressed Text Documents
Jul 02, 2020


Page segmentation is considered to be the crucial stage for the automatic analysis of documents with complex layouts. This has traditionally been carried out in uncompressed documents, although most of the documents in real life exist in a compressed form warranted by the requirement to make storage and transfer efficient. However, carrying out page segmentation directly in compressed documents without going through the stage of decompression is a challenging goal. This research paper proposes demonstrating the possibility of carrying out a page segmentation operation directly in the run-length data of the CCITT Group-3 compressed text document, which could be single- or multi-columned and might even have some text regions in the inverted text color mode. Therefore, before carrying out the segmentation of the text document into columns, each column into paragraphs, each paragraph into text lines, each line into words, and, finally, each word into characters, a pre-processing of the text document needs to be carried out. The pre-processing stage identifies the normal text regions and inverted text regions, and the inverted text regions are toggled to the normal mode. In the sequel to initiate column separation, a new strategy of incremental assimilation of white space runs in the vertical direction and the auto-estimation of certain related parameters is proposed. A procedure to realize column-segmentation employing these extracted parameters has been devised. Subsequently, what follows first is a two-level horizontal row separation process, which segments every column into paragraphs, and in turn, into text-lines. Then, there is a two-level vertical column separation process, which completes the separation into words and characters.
Target specific mining of COVID-19 scholarly articles using one-class approach
Apr 24, 2020
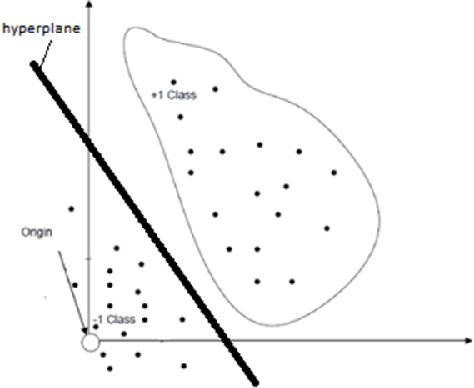

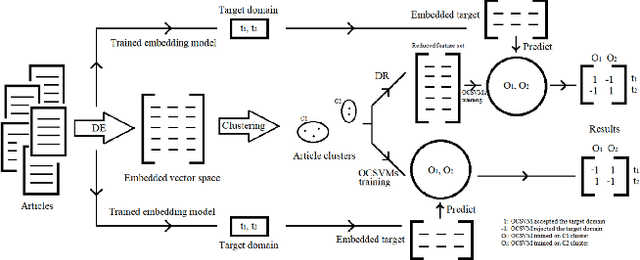
In recent years, several research articles have been published in the field of corona-virus caused diseases like severe acute respiratory syndrome (SARS), middle east respiratory syndrome (MERS) and COVID-19. In the presence of numerous research articles, extracting best-suited articles is time-consuming and manually impractical. The objective of this paper is to extract the activity and trends of corona-virus related research articles using machine learning approaches. The COVID-19 open research dataset (CORD-19) is used for experiments, whereas several target-tasks along with explanations are defined for classification, based on domain knowledge. Clustering techniques are used to create the different clusters of available articles, and later the task assignment is performed using parallel one-class support vector machines (OCSVMs). Experiments with original and reduced features validate the performance of the approach. It is evident that the k-means clustering algorithm, followed by parallel OCSVMs, outperforms other methods for both original and reduced feature space.
Word and character segmentation directly in run-length compressed handwritten document images
Aug 18, 2019
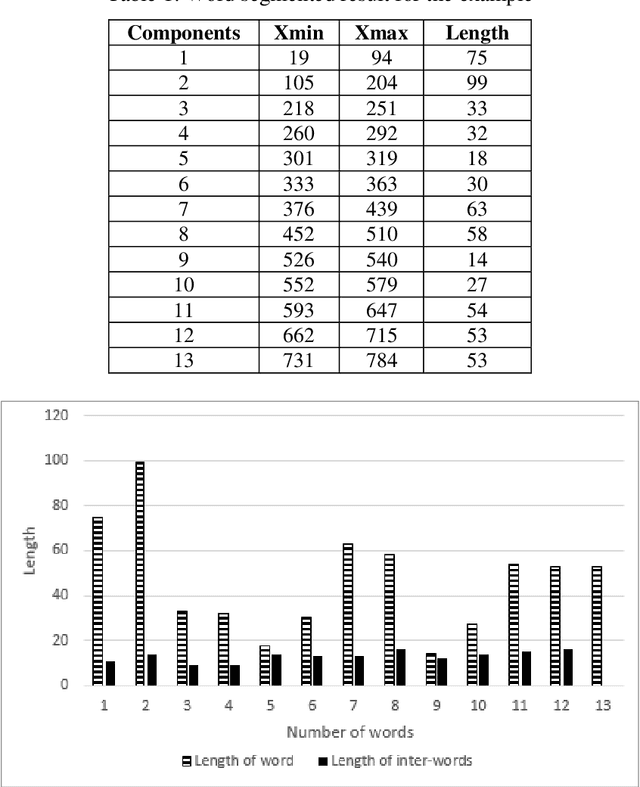
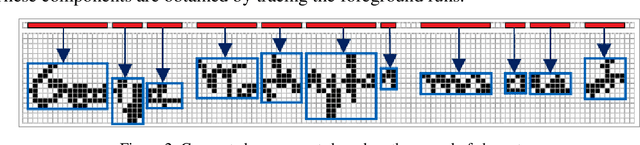
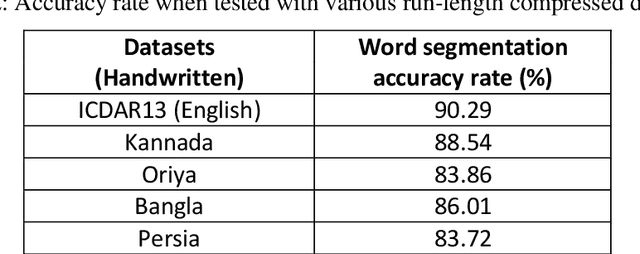
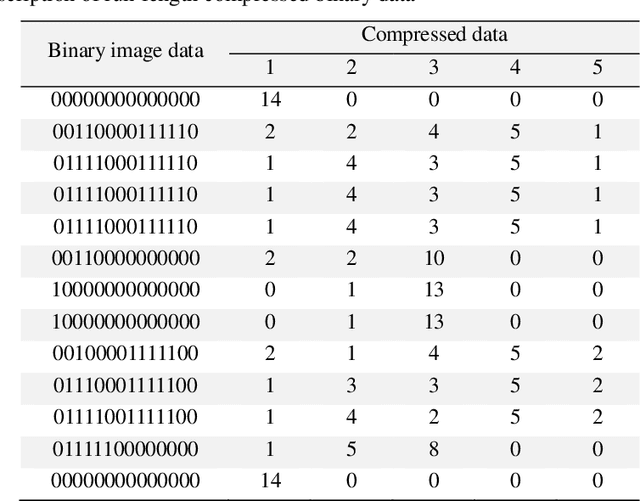
From the literature, it is demonstrated that performing text-line segmentation directly in the run-length compressed handwritten document images significantly reduces the computational time and memory space. In this paper, we investigate the issues of word and character segmentation directly on the run-length compressed document images. Primarily, the spreads of the characters are intelligently extracted from the foreground runs of the compressed data and subsequently connected components are established. The spacing between the connected components would be larger between the adjacent words when compared to that of intra-words. With this knowledge, a threshold is empirically chosen for inter-word separation. Every connected component within a word is further analysed for character segmentation. Here, min-cut graph concept is used for separating the touching characters. Over-segmentation and under-segmentation issues are addressed by insertion and deletion operations respectively. The approach has been developed particularly for compressed handwritten English document images. However, the model has been tested on non-English document images.
Spotting Separator Points at Line Terminals in Compressed Document Images for Text-line Segmentation
Aug 18, 2017
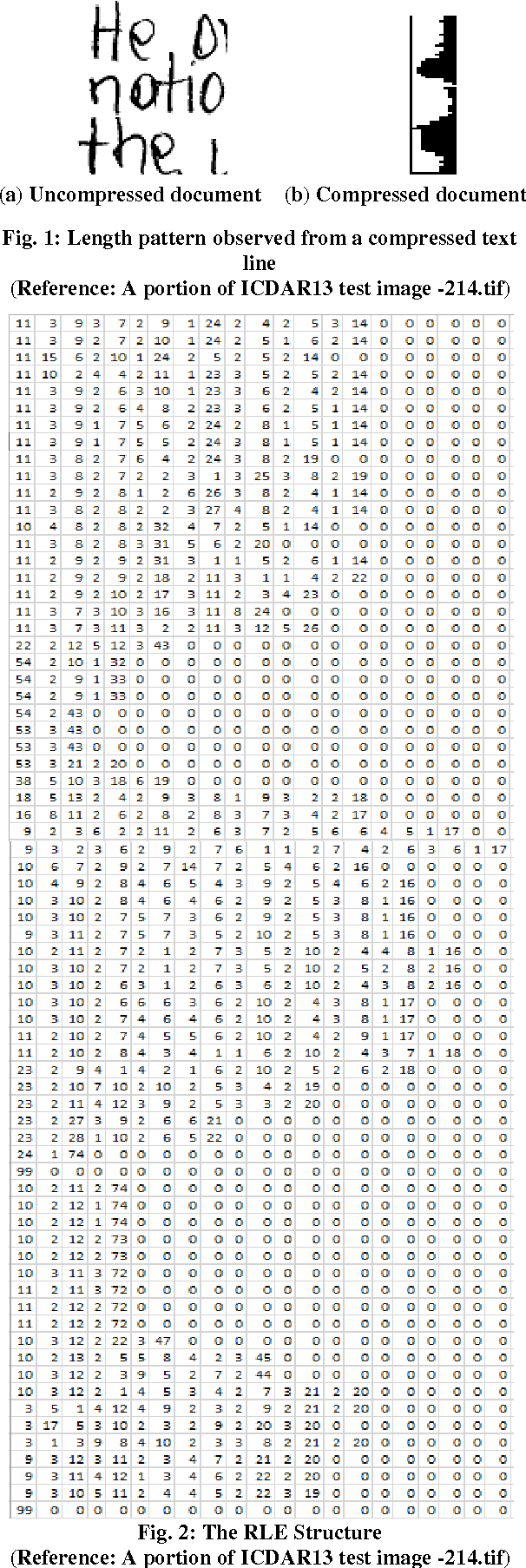
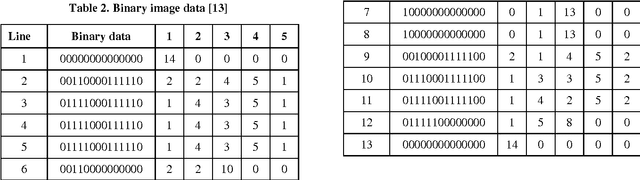
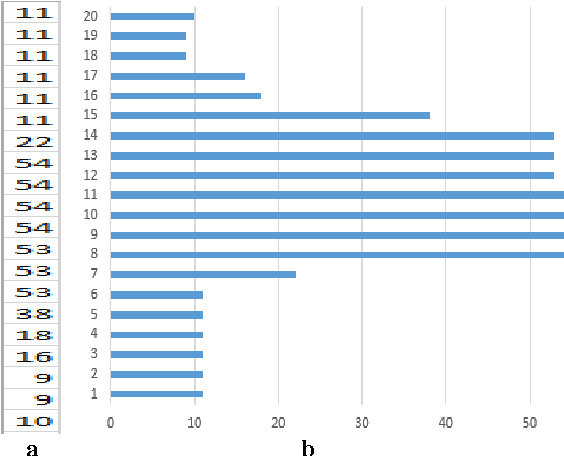
Line separators are used to segregate text-lines from one another in document image analysis. Finding the separator points at every line terminal in a document image would enable text-line segmentation. In particular, identifying the separators in handwritten text could be a thrilling exercise. Obviously it would be challenging to perform this in the compressed version of a document image and that is the proposed objective in this research. Such an effort would prevent the computational burden of decompressing a document for text-line segmentation. Since document images are generally compressed using run length encoding (RLE) technique as per the CCITT standards, the first column in the RLE will be a white column. The value (depth) in the white column is very low when a particular line is a text line and the depth could be larger at the point of text line separation. A longer consecutive sequence of such larger depth should indicate the gap between the text lines, which provides the separator region. In case of over separation and under separation issues, corrective actions such as deletion and insertion are suggested respectively. An extensive experimentation is conducted on the compressed images of the benchmark datasets of ICDAR13 and Alireza et al [17] to demonstrate the efficacy.
* Line separators, Document image analysis, Handwritten text, Compression and decompression, RLE, CCITT. Line separator points at every line terminal in a compressed handwritten document images enabling text line segmentation
Direct Processing of Document Images in Compressed Domain
Oct 14, 2014With the rapid increase in the volume of Big data of this digital era, fax documents, invoices, receipts, etc are traditionally subjected to compression for the efficiency of data storage and transfer. However, in order to process these documents, they need to undergo the stage of decompression which indents additional computing resources. This limitation induces the motivation to research on the possibility of directly processing of compressed images. In this research paper, we summarize the research work carried out to perform different operations straight from run-length compressed documents without going through the stage of decompression. The different operations demonstrated are feature extraction; text-line, word and character segmentation; document block segmentation; and font size detection, all carried out in the compressed version of the document. Feature extraction methods demonstrate how to extract the conventionally defined features such as projection profile, run-histogram and entropy, directly from the compressed document data. Document segmentation involves the extraction of compressed segments of text-lines, words and characters using the vertical and horizontal projection profile features. Further an attempt is made to segment randomly a block of interest from the compressed document and subsequently facilitate absolute and relative characterization of the segmented block which finds real time applications in automatic processing of Bank Cheques, Challans, etc, in compressed domain. Finally an application to detect font size at text line level is also investigated. All the proposed algorithms are validated experimentally with sufficient data set of compressed documents.