 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network
Oct 01, 2022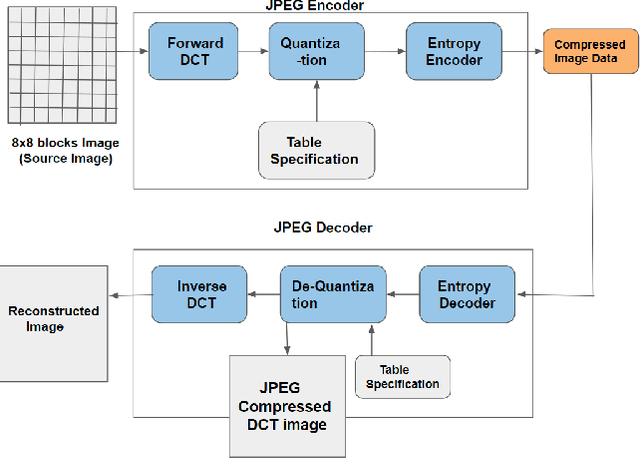

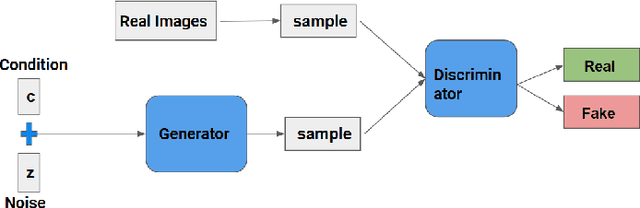

The problem of generating textual descriptions for the visual data has gained research attention in the recent years. In contrast to that the problem of generating visual data from textual descriptions is still very challenging, because it requires the combination of both Natural Language Processing (NLP) and Computer Vision techniques. The existing methods utilize the Generative Adversarial Networks (GANs) and generate the uncompressed images from textual description. However, in practice, most of the visual data are processed and transmitted in the compressed representation. Hence, the proposed work attempts to generate the visual data directly in the compressed representation form using Deep Convolutional GANs (DCGANs) to achieve the storage and computational efficiency. We propose GAN models for compressed image generation from text. The first model is directly trained with JPEG compressed DCT images (compressed domain) to generate the compressed images from text descriptions. The second model is trained with RGB images (pixel domain) to generate JPEG compressed DCT representation from text descriptions. The proposed models are tested on an open source benchmark dataset Oxford-102 Flower images using both RGB and JPEG compressed versions, and accomplished the state-of-the-art performance in the JPEG compressed domain. The code will be publicly released at GitHub after acceptance of paper.