 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotting Separator Points at Line Terminals in Compressed Document Images for Text-line Segmentation
Paper and Code
Aug 18, 2017
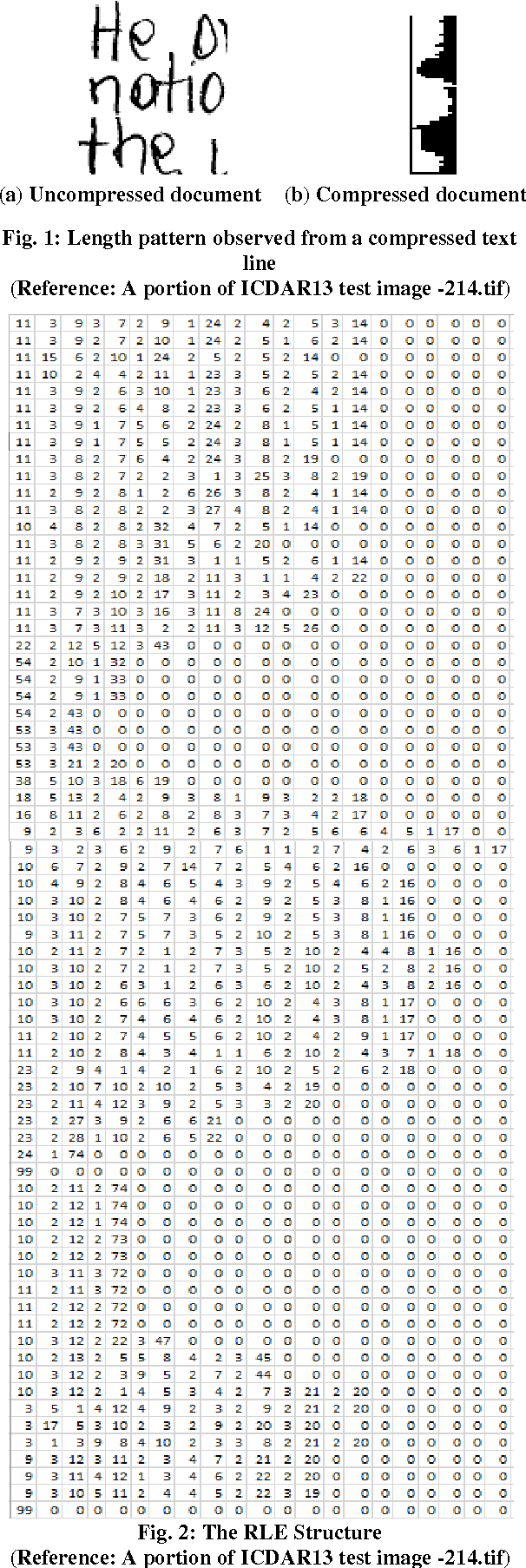
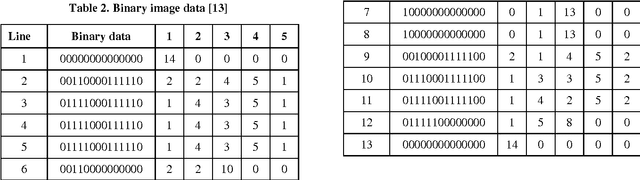
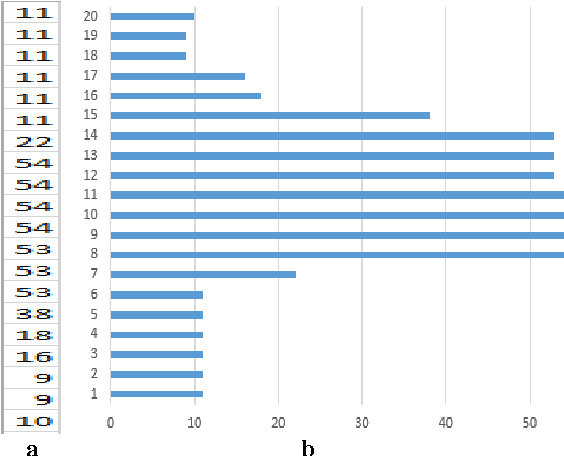
Line separators are used to segregate text-lines from one another in document image analysis. Finding the separator points at every line terminal in a document image would enable text-line segmentation. In particular, identifying the separators in handwritten text could be a thrilling exercise. Obviously it would be challenging to perform this in the compressed version of a document image and that is the proposed objective in this research. Such an effort would prevent the computational burden of decompressing a document for text-line segmentation. Since document images are generally compressed using run length encoding (RLE) technique as per the CCITT standards, the first column in the RLE will be a white column. The value (depth) in the white column is very low when a particular line is a text line and the depth could be larger at the point of text line separation. A longer consecutive sequence of such larger depth should indicate the gap between the text lines, which provides the separator region. In case of over separation and under separation issues, corrective actions such as deletion and insertion are suggested respectively. An extensive experimentation is conducted on the compressed images of the benchmark datasets of ICDAR13 and Alireza et al [17] to demonstrate the efficacy.