 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngularGrad: A New Optimization Technique for Angular Convergence of Convolutional Neural Networks
May 21, 2021Convolutional neural networks (CNNs) are trained using stochastic gradient descent (SGD)-based optimizers. Recently, the adaptive moment estimation (Adam) optimizer has become very popular due to its adaptive momentum, which tackles the dying gradient problem of SGD. Nevertheless, existing optimizers are still unable to exploit the optimization curvature information efficiently. This paper proposes a new AngularGrad optimizer that considers the behavior of the direction/angle of consecutive gradients. This is the first attempt in the literature to exploit the gradient angular information apart from its magnitude. The proposed AngularGrad generates a score to control the step size based on the gradient angular information of previous iterations. Thus, the optimization steps become smoother as a more accurate step size of immediate past gradients is captured through the angular information. Two variants of AngularGrad are developed based on the use of Tangent or Cosine functions for computing the gradient angular information. Theoretically, AngularGrad exhibits the same regret bound as Adam for convergence purposes. Nevertheless, extensive experiments conducted on benchmark data sets against state-of-the-art methods reveal a superior performance of AngularGrad. The source code will be made publicly available at: https://github.com/mhaut/AngularGrad.
Direct Processing of Document Images in Compressed Domain
Oct 14, 2014With the rapid increase in the volume of Big data of this digital era, fax documents, invoices, receipts, etc are traditionally subjected to compression for the efficiency of data storage and transfer. However, in order to process these documents, they need to undergo the stage of decompression which indents additional computing resources. This limitation induces the motivation to research on the possibility of directly processing of compressed images. In this research paper, we summarize the research work carried out to perform different operations straight from run-length compressed documents without going through the stage of decompression. The different operations demonstrated are feature extraction; text-line, word and character segmentation; document block segmentation; and font size detection, all carried out in the compressed version of the document. Feature extraction methods demonstrate how to extract the conventionally defined features such as projection profile, run-histogram and entropy, directly from the compressed document data. Document segmentation involves the extraction of compressed segments of text-lines, words and characters using the vertical and horizontal projection profile features. Further an attempt is made to segment randomly a block of interest from the compressed document and subsequently facilitate absolute and relative characterization of the segmented block which finds real time applications in automatic processing of Bank Cheques, Challans, etc, in compressed domain. Finally an application to detect font size at text line level is also investigated. All the proposed algorithms are validated experimentally with sufficient data set of compressed documents.
Entropy Computation of Document Images in Run-Length Compressed Domain
Apr 08, 2014
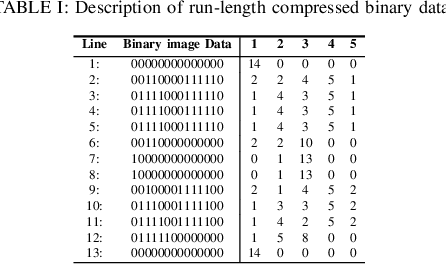


Compression of documents, images, audios and videos have been traditionally practiced to increase the efficiency of data storage and transfer. However, in order to process or carry out any analytical computations, decompression has become an unavoidable pre-requisite. In this research work, we have attempted to compute the entropy, which is an important document analytic directly from the compressed documents. We use Conventional Entropy Quantifier (CEQ) and Spatial Entropy Quantifiers (SEQ) for entropy computations [1]. The entropies obtained are useful in applications like establishing equivalence, word spotting and document retrieval. Experiments have been performed with all the data sets of [1], at character, word and line levels taking compressed documents in run-length compressed domain. The algorithms developed are computational and space efficient, and results obtained match 100% with the results reported in [1].
* Published in IEEE Proceedings 2014 Fifth International Conference on Signals and Image Processing
Extraction of Projection Profile, Run-Histogram and Entropy Features Straight from Run-Length Compressed Text-Documents
Apr 02, 2014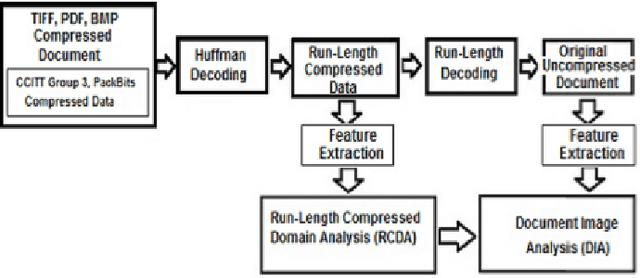
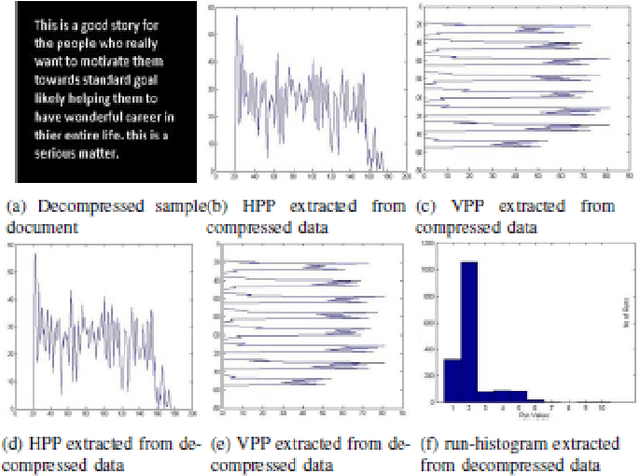
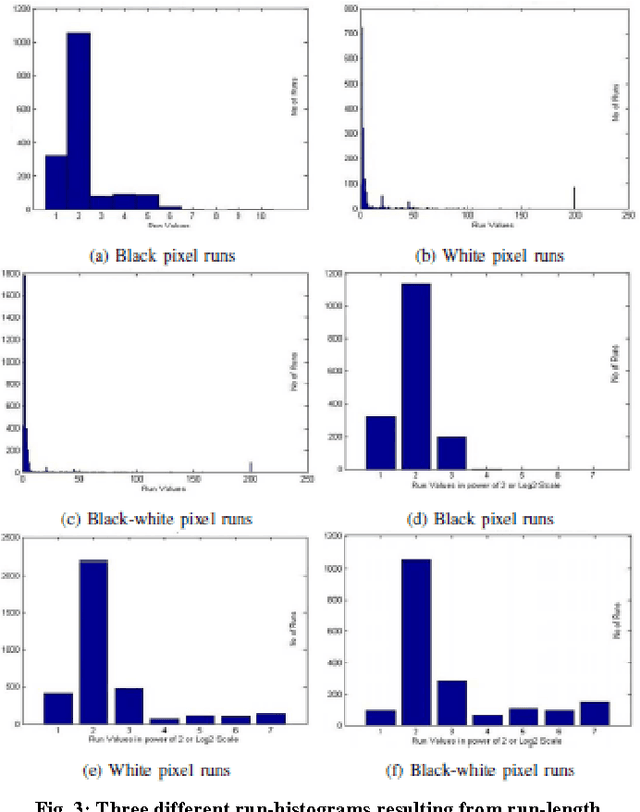
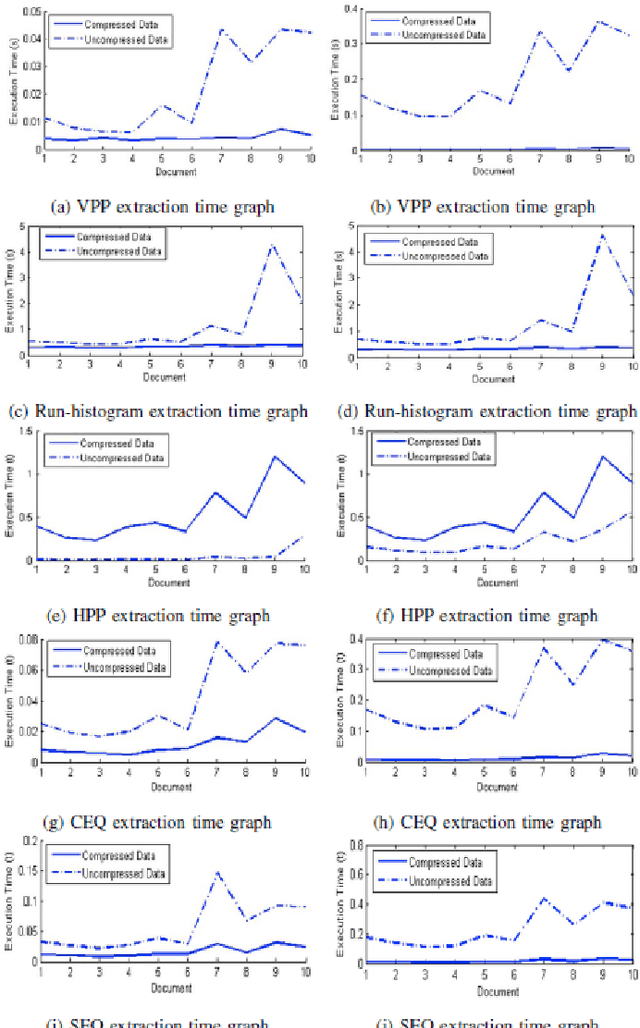
Document Image Analysis, like any Digital Image Analysis requires identification and extraction of proper features, which are generally extracted from uncompressed images, though in reality images are made available in compressed form for the reasons such as transmission and storage efficiency. However, this implies that the compressed image should be decompressed, which indents additional computing resources. This limitation induces the motivation to research in extracting features directly from the compressed image. In this research, we propose to extract essential features such as projection profile, run-histogram and entropy for text document analysis directly from run-length compressed text-documents. The experimentation illustrates that features are extracted directly from the compressed image without going through the stage of decompression, because of which the computing time is reduced. The feature values so extracted are exactly identical to those extracted from uncompressed images.
* Published by IEEE in Proceedings of ACPR-2013. arXiv admin note: text overlap with arXiv:1403.7783
Extraction of Line Word Character Segments Directly from Run Length Compressed Printed Text Documents
Mar 30, 2014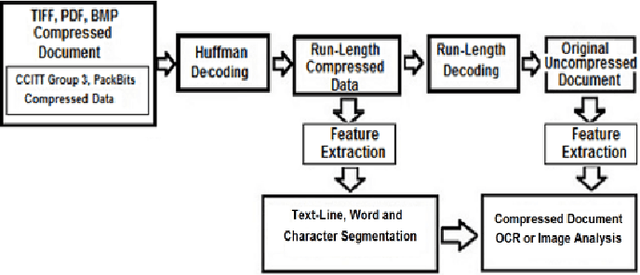



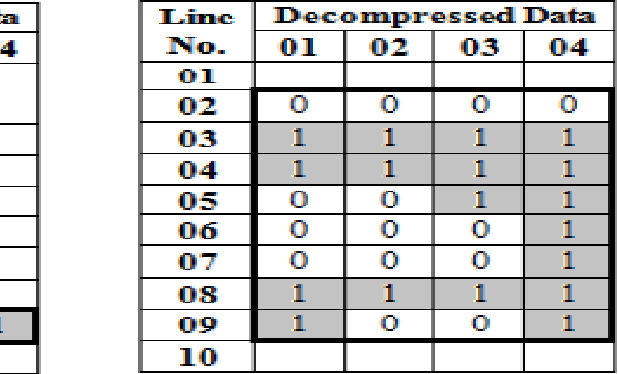
Segmentation of a text-document into lines, words and characters, which is considered to be the crucial pre-processing stage in Optical Character Recognition (OCR) is traditionally carried out on uncompressed documents, although most of the documents in real life are available in compressed form, for the reasons such as transmission and storage efficiency. However, this implies that the compressed image should be decompressed, which indents additional computing resources. This limitation has motivated us to take up research in document image analysis using compressed documents. In this paper, we think in a new way to carry out segmentation at line, word and character level in run-length compressed printed-text-documents. We extract the horizontal projection profile curve from the compressed file and using the local minima points perform line segmentation. However, tracing vertical information which leads to tracking words-characters in a run-length compressed file is not very straight forward. Therefore, we propose a novel technique for carrying out simultaneous word and character segmentation by popping out column runs from each row in an intelligent sequence. The proposed algorithms have been validated with 1101 text-lines, 1409 words and 7582 characters from a data-set of 35 noise and skew free compressed documents of Bengali, Kannada and English Scripts.
Direct Processing of Run Length Compressed Document Image for Segmentation and Characterization of a Specified Block
Feb 18, 2014

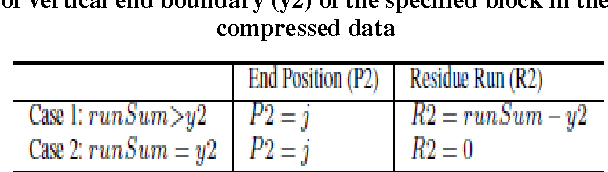
Extracting a block of interest referred to as segmenting a specified block in an image and studying its characteristics is of general research interest, and could be a challenging if such a segmentation task has to be carried out directly in a compressed image. This is the objective of the present research work. The proposal is to evolve a method which would segment and extract a specified block, and carry out its characterization without decompressing a compressed image, for two major reasons that most of the image archives contain images in compressed format and decompressing an image indents additional computing time and space. Specifically in this research work, the proposal is to work on run-length compressed document images.
* 7 Pages and Published with International Journal of Computer Applications (IJCA)
Automatic Detection of Font Size Straight from Run Length Compressed Text Documents
Feb 18, 2014


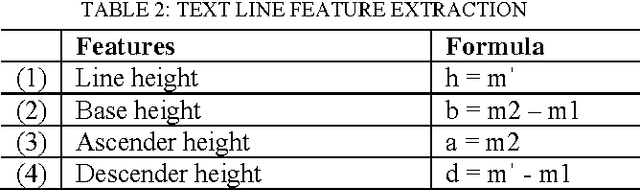
Automatic detection of font size finds many applications in the area of intelligent OCRing and document image analysis, which has been traditionally practiced over uncompressed documents, although in real life the documents exist in compressed form for efficient storage and transmission. It would be novel and intelligent if the task of font size detection could be carried out directly from the compressed data of these documents without decompressing, which would result in saving of considerable amount of processing time and space. Therefore, in this paper we present a novel idea of learning and detecting font size directly from run-length compressed text documents at line level using simple line height features, which paves the way for intelligent OCRing and document analysis directly from compressed documents. In the proposed model, the given mixed-case text documents of different font size are segmented into compressed text lines and the features extracted such as line height and ascender height are used to capture the pattern of font size in the form of a regression line, using which the automatic detection of font size is done during the recognition stage. The method is experimented with a dataset of 50 compressed documents consisting of 780 text lines of single font size and 375 text lines of mixed font size resulting in an overall accuracy of 99.67%.
* 8 Pages
Video Text Localization using Wavelet and Shearlet Transforms
Nov 15, 2013Text in video is useful and important in indexing and retrieving the video documents efficiently and accurately. In this paper, we present a new method of text detection using a combined dictionary consisting of wavelets and a recently introduced transform called shearlets. Wavelets provide optimally sparse expansion for point-like structures and shearlets provide optimally sparse expansions for curve-like structures. By combining these two features we have computed a high frequency sub-band to brighten the text part. Then K-means clustering is used for obtaining text pixels from the Standard Deviation (SD) of combined coefficient of wavelets and shearlets as well as the union of wavelets and shearlets features. Text parts are obtained by grouping neighboring regions based on geometric properties of the classified output frame of unsupervised K-means classification. The proposed method tested on a standard as well as newly collected database shows to be superior to some existing methods.