 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Detection of Font Size Straight from Run Length Compressed Text Documents
Paper and Code
Feb 18, 2014


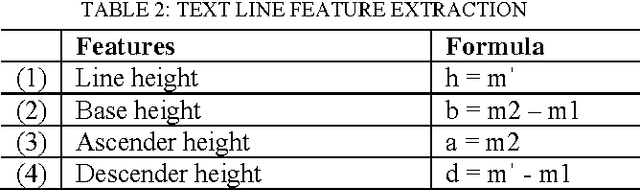
Automatic detection of font size finds many applications in the area of intelligent OCRing and document image analysis, which has been traditionally practiced over uncompressed documents, although in real life the documents exist in compressed form for efficient storage and transmission. It would be novel and intelligent if the task of font size detection could be carried out directly from the compressed data of these documents without decompressing, which would result in saving of considerable amount of processing time and space. Therefore, in this paper we present a novel idea of learning and detecting font size directly from run-length compressed text documents at line level using simple line height features, which paves the way for intelligent OCRing and document analysis directly from compressed documents. In the proposed model, the given mixed-case text documents of different font size are segmented into compressed text lines and the features extracted such as line height and ascender height are used to capture the pattern of font size in the form of a regression line, using which the automatic detection of font size is done during the recognition stage. The method is experimented with a dataset of 50 compressed documents consisting of 780 text lines of single font size and 375 text lines of mixed font size resulting in an overall accuracy of 99.67%.