 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBangla Text Recognition from Video Sequence: A New Focus
Jan 06, 2014
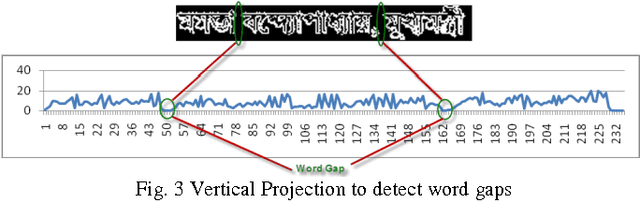
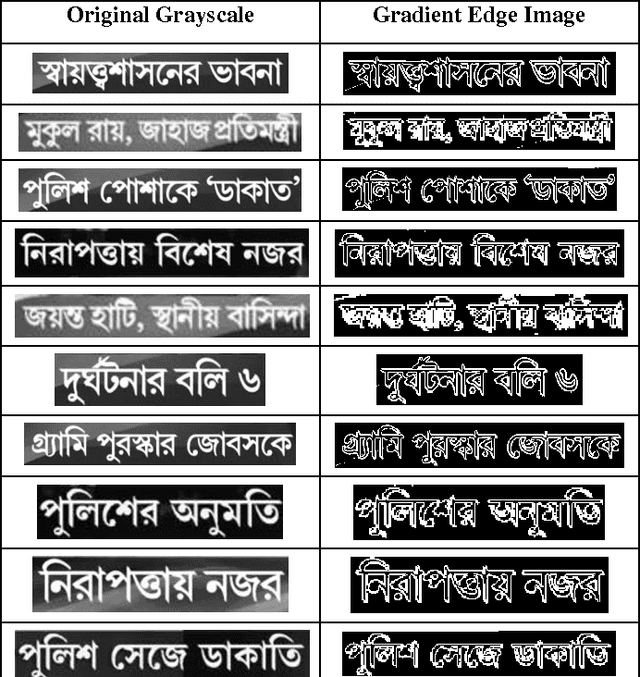

Extraction and recognition of Bangla text from video frame images is challenging due to complex color background, low-resolution etc. In this paper, we propose an algorithm for extraction and recognition of Bangla text form such video frames with complex background. Here, a two-step approach has been proposed. First, the text line is segmented into words using information based on line contours. First order gradient value of the text blocks are used to find the word gap. Next, a local binarization technique is applied on each word and text line is reconstructed using those words. Secondly, this binarized text block is sent to OCR for recognition purpose.
Video Text Localization using Wavelet and Shearlet Transforms
Nov 15, 2013Text in video is useful and important in indexing and retrieving the video documents efficiently and accurately. In this paper, we present a new method of text detection using a combined dictionary consisting of wavelets and a recently introduced transform called shearlets. Wavelets provide optimally sparse expansion for point-like structures and shearlets provide optimally sparse expansions for curve-like structures. By combining these two features we have computed a high frequency sub-band to brighten the text part. Then K-means clustering is used for obtaining text pixels from the Standard Deviation (SD) of combined coefficient of wavelets and shearlets as well as the union of wavelets and shearlets features. Text parts are obtained by grouping neighboring regions based on geometric properties of the classified output frame of unsupervised K-means classification. The proposed method tested on a standard as well as newly collected database shows to be superior to some existing methods.